 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQEDBENCH: Quantifying the Alignment Gap in Automated Evaluation of University-Level Mathematical Proofs
Feb 24, 2026As Large Language Models (LLMs) saturate elementary benchmarks, the research frontier has shifted from generation to the reliability of automated evaluation. We demonstrate that standard "LLM-as-a-Judge" protocols suffer from a systematic Alignment Gap when applied to upper-undergraduate to early graduate level mathematics. To quantify this, we introduce QEDBench, the first large-scale dual-rubric alignment benchmark to systematically measure alignment with human experts on university-level math proofs by contrasting course-specific rubrics against expert common knowledge criteria. By deploying a dual-evaluation matrix (7 judges x 5 solvers) against 1,000+ hours of human evaluation, we reveal that certain frontier evaluators like Claude Opus 4.5, DeepSeek-V3, Qwen 2.5 Max, and Llama 4 Maverick exhibit significant positive bias (up to +0.18, +0.20, +0.30, +0.36 mean score inflation, respectively). Furthermore, we uncover a critical reasoning gap in the discrete domain: while Gemini 3.0 Pro achieves state-of-the-art performance (0.91 average human evaluation score), other reasoning models like GPT-5 Pro and Claude Sonnet 4.5 see their performance significantly degrade in discrete domains. Specifically, their average human evaluation scores drop to 0.72 and 0.63 in Discrete Math, and to 0.74 and 0.50 in Graph Theory. In addition to these research results, we also release QEDBench as a public benchmark for evaluating and improving AI judges. Our benchmark is publicly published at https://github.com/qqliu/Yale-QEDBench.
A Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025



This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.
Future Slot Prediction for Unsupervised Object Discovery in Surgical Video
Jul 02, 2025Object-centric slot attention is an emerging paradigm for unsupervised learning of structured, interpretable object-centric representations (slots). This enables effective reasoning about objects and events at a low computational cost and is thus applicable to critical healthcare applications, such as real-time interpretation of surgical video. The heterogeneous scenes in real-world applications like surgery are, however, difficult to parse into a meaningful set of slots. Current approaches with an adaptive slot count perform well on images, but their performance on surgical videos is low. To address this challenge, we propose a dynamic temporal slot transformer (DTST) module that is trained both for temporal reasoning and for predicting the optimal future slot initialization. The model achieves state-of-the-art performance on multiple surgical databases, demonstrating that unsupervised object-centric methods can be applied to real-world data and become part of the common arsenal in healthcare applications.
StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D
Dec 02, 2023



In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Ultrathin, high-speed, all-optical photoacoustic endomicroscopy probe for guiding minimally invasive surgery
May 06, 2022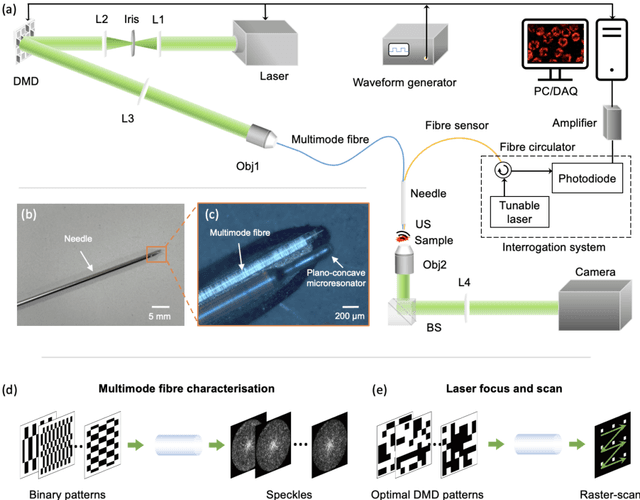
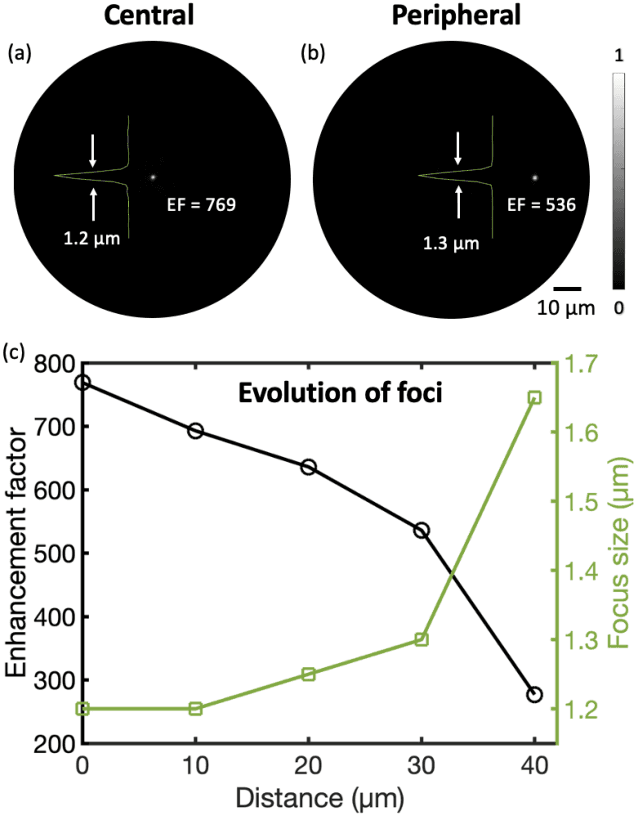
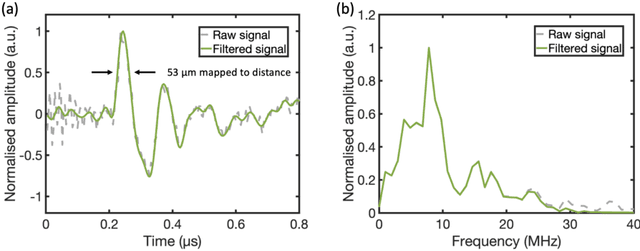
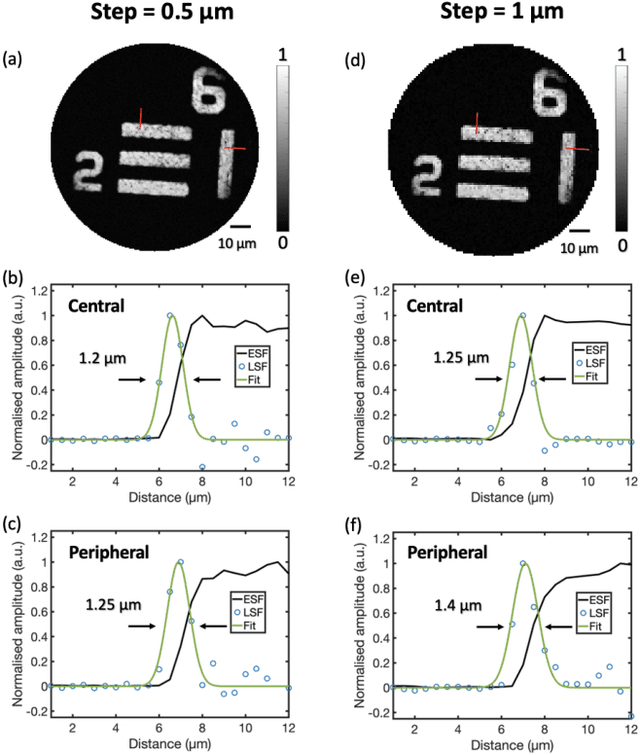
Photoacoustic (PA) endoscopy has shown significant potential for clinical diagnosis and surgical guidance. Multimode fibres (MMFs) are becoming increasing attractive for the development of miniature endoscopy probes owing to ultrathin size, low cost and diffraction-limited spatial resolution enabled by wavefront shaping. However, current MMF-based PA endomicroscopy probes are either limited by a bulky ultrasound detector or a low imaging speed which hindered their usability. In this work, we report the development of a highly miniaturised and high-speed PA endomicroscopy probe that is integrated within the cannula of a 20 gauge medical needle. This probe comprises a MMF for delivering the PA excitation light and a single-mode optical fibre with a plano-concave microresonator for ultrasound detection. Wavefront shaping with a digital micromirror device enabled rapid raster-scanning of a focused light spot at the distal end of the MMF for tissue interrogation. High-resolution PA imaging of mouse red blood cells covering an area 100 microns in diameter was achieved with the needle probe at ~3 frames per second. Mosaicing imaging was performed after fibre characterisation by translating the needle probe to enlarge the field-of-view in real-time. The developed ultrathin PA endomicroscopy probe is promising for guiding minimally invasive surgery by providing functional, molecular and microstructural information of tissue in real-time.
No Shadow Left Behind: Removing Objects and their Shadows using Approximate Lighting and Geometry
Dec 19, 2020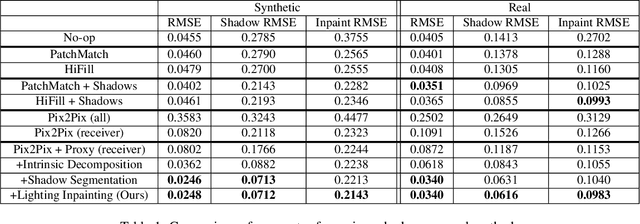
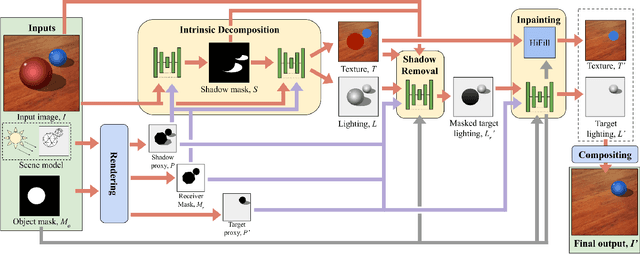


Removing objects from images is a challenging problem that is important for many applications, including mixed reality. For believable results, the shadows that the object casts should also be removed. Current inpainting-based methods only remove the object itself, leaving shadows behind, or at best require specifying shadow regions to inpaint. We introduce a deep learning pipeline for removing a shadow along with its caster. We leverage rough scene models in order to remove a wide variety of shadows (hard or soft, dark or subtle, large or thin) from surfaces with a wide variety of textures. We train our pipeline on synthetically rendered data, and show qualitative and quantitative results on both synthetic and real scenes.
Sampling Training Data for Continual Learning Between Robots and the Cloud
Dec 12, 2020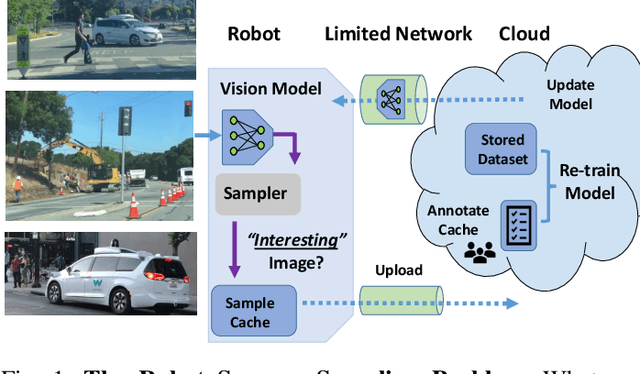
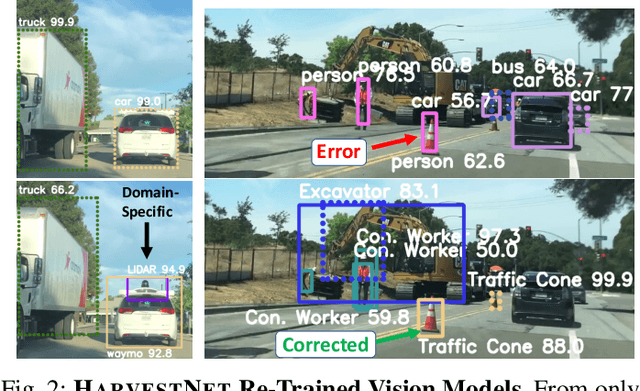
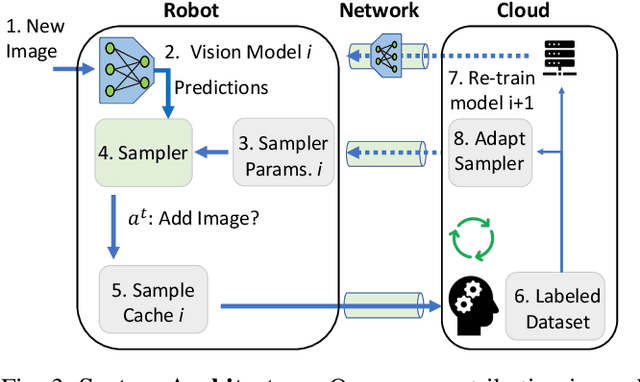
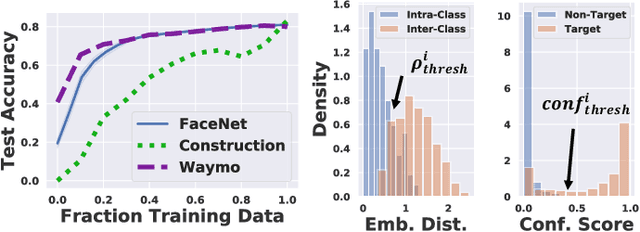
Today's robotic fleets are increasingly measuring high-volume video and LIDAR sensory streams, which can be mined for valuable training data, such as rare scenes of road construction sites, to steadily improve robotic perception models. However, re-training perception models on growing volumes of rich sensory data in central compute servers (or the "cloud") places an enormous time and cost burden on network transfer, cloud storage, human annotation, and cloud computing resources. Hence, we introduce HarvestNet, an intelligent sampling algorithm that resides on-board a robot and reduces system bottlenecks by only storing rare, useful events to steadily improve perception models re-trained in the cloud. HarvestNet significantly improves the accuracy of machine-learning models on our novel dataset of road construction sites, field testing of self-driving cars, and streaming face recognition, while reducing cloud storage, dataset annotation time, and cloud compute time by between 65.7-81.3%. Further, it is between 1.05-2.58x more accurate than baseline algorithms and scalably runs on embedded deep learning hardware. We provide a suite of compute-efficient perception models for the Google Edge Tensor Processing Unit (TPU), an extended technical report, and a novel video dataset to the research community at https://sites.google.com/view/harvestnet.