 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAP-Tuning: Neural Augmented Prompt Tuning for Adversarially Robust Vision-Language Models
Jun 15, 2025



Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capabilities in understanding relationships between visual and textual data through joint embedding spaces. Despite their effectiveness, these models remain vulnerable to adversarial attacks, particularly in the image modality, posing significant security concerns. Building upon our previous work on Adversarial Prompt Tuning (AdvPT), which introduced learnable text prompts to enhance adversarial robustness in VLMs without extensive parameter training, we present a significant extension by introducing the Neural Augmentor framework for Multi-modal Adversarial Prompt Tuning (NAP-Tuning).Our key innovations include: (1) extending AdvPT from text-only to multi-modal prompting across both text and visual modalities, (2) expanding from single-layer to multi-layer prompt architectures, and (3) proposing a novel architecture-level redesign through our Neural Augmentor approach, which implements feature purification to directly address the distortions introduced by adversarial attacks in feature space. Our NAP-Tuning approach incorporates token refiners that learn to reconstruct purified features through residual connections, allowing for modality-specific and layer-specific feature correction.Comprehensive experiments demonstrate that NAP-Tuning significantly outperforms existing methods across various datasets and attack types. Notably, our approach shows significant improvements over the strongest baselines under the challenging AutoAttack benchmark, outperforming them by 33.5% on ViT-B16 and 33.0% on ViT-B32 architectures while maintaining competitive clean accuracy.
RoGA: Towards Generalizable Deepfake Detection through Robust Gradient Alignment
May 27, 2025
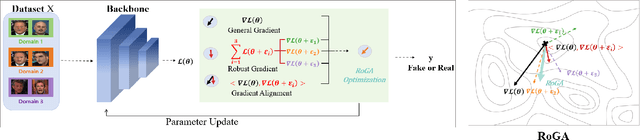


Recent advancements in domain generalization for deepfake detection have attracted significant attention, with previous methods often incorporating additional modules to prevent overfitting to domain-specific patterns. However, such regularization can hinder the optimization of the empirical risk minimization (ERM) objective, ultimately degrading model performance. In this paper, we propose a novel learning objective that aligns generalization gradient updates with ERM gradient updates. The key innovation is the application of perturbations to model parameters, aligning the ascending points across domains, which specifically enhances the robustness of deepfake detection models to domain shifts. This approach effectively preserves domain-invariant features while managing domain-specific characteristics, without introducing additional regularization. Experimental results on multiple challenging deepfake detection datasets demonstrate that our gradient alignment strategy outperforms state-of-the-art domain generalization techniques, confirming the efficacy of our method. The code is available at https://github.com/Lynn0925/RoGA.
Contrastive Desensitization Learning for Cross Domain Face Forgery Detection
May 27, 2025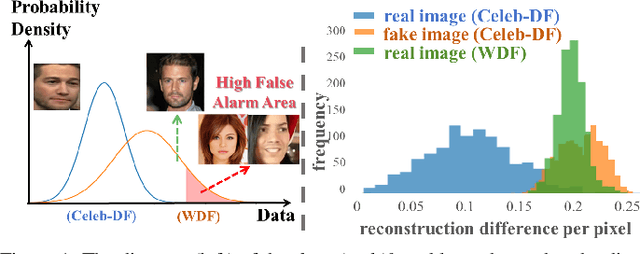



In this paper, we propose a new cross-domain face forgery detection method that is insensitive to different and possibly unseen forgery methods while ensuring an acceptable low false positive rate. Although existing face forgery detection methods are applicable to multiple domains to some degree, they often come with a high false positive rate, which can greatly disrupt the usability of the system. To address this issue, we propose an Contrastive Desensitization Network (CDN) based on a robust desensitization algorithm, which captures the essential domain characteristics through learning them from domain transformation over pairs of genuine face images. One advantage of CDN lies in that the learnt face representation is theoretical justified with regard to the its robustness against the domain changes. Extensive experiments over large-scale benchmark datasets demonstrate that our method achieves a much lower false alarm rate with improved detection accuracy compared to several state-of-the-art methods.
Towards One-shot Federated Learning: Advances, Challenges, and Future Directions
May 05, 2025One-shot FL enables collaborative training in a single round, eliminating the need for iterative communication, making it particularly suitable for use in resource-constrained and privacy-sensitive applications. This survey offers a thorough examination of One-shot FL, highlighting its distinct operational framework compared to traditional federated approaches. One-shot FL supports resource-limited devices by enabling single-round model aggregation while maintaining data locality. The survey systematically categorizes existing methodologies, emphasizing advancements in client model initialization, aggregation techniques, and strategies for managing heterogeneous data distributions. Furthermore, we analyze the limitations of current approaches, particularly in terms of scalability and generalization in non-IID settings. By analyzing cutting-edge techniques and outlining open challenges, this survey aspires to provide a comprehensive reference for researchers and practitioners aiming to design and implement One-shot FL systems, advancing the development and adoption of One-shot FL solutions in a real-world, resource-constrained scenario.
Adversarial Prompt Tuning for Vision-Language Models
Nov 19, 2023With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities. However, these models remain vulnerable to adversarial attacks, particularly in the image modality, presenting considerable security risks. This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs. AdvPT innovatively leverages learnable text prompts and aligns them with adversarial image embeddings, to address the vulnerabilities inherent in VLMs without the need for extensive parameter training or modification of the model architecture. We demonstrate that AdvPT improves resistance against white-box and black-box adversarial attacks and exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting defensive capabilities. Comprehensive experimental analyses provide insights into adversarial prompt tuning, a novel paradigm devoted to improving resistance to adversarial images through textual input modifications, paving the way for future robust multimodal learning research. These findings open up new possibilities for enhancing the security of VLMs. Our code will be available upon publication of the paper.