 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Method to Predict Classifier Accuracy on Larger Datasets given Small Pilot Data
Nov 29, 2023



Practitioners building classifiers often start with a smaller pilot dataset and plan to grow to larger data in the near future. Such projects need a toolkit for extrapolating how much classifier accuracy may improve from a 2x, 10x, or 50x increase in data size. While existing work has focused on finding a single "best-fit" curve using various functional forms like power laws, we argue that modeling and assessing the uncertainty of predictions is critical yet has seen less attention. In this paper, we propose a Gaussian process model to obtain probabilistic extrapolations of accuracy or similar performance metrics as dataset size increases. We evaluate our approach in terms of error, likelihood, and coverage across six datasets. Though we focus on medical tasks and image modalities, our open source approach generalizes to any kind of classifier.
Approximate Bayesian Computation for an Explicit-Duration Hidden Markov Model of COVID-19 Hospital Trajectories
Apr 28, 2021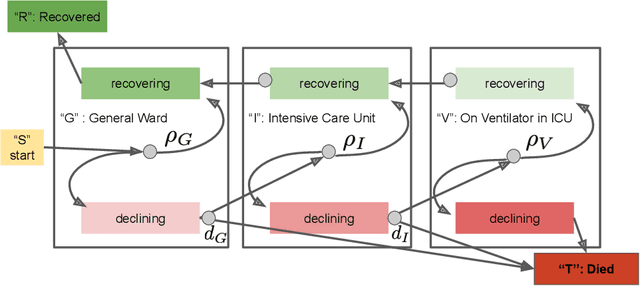
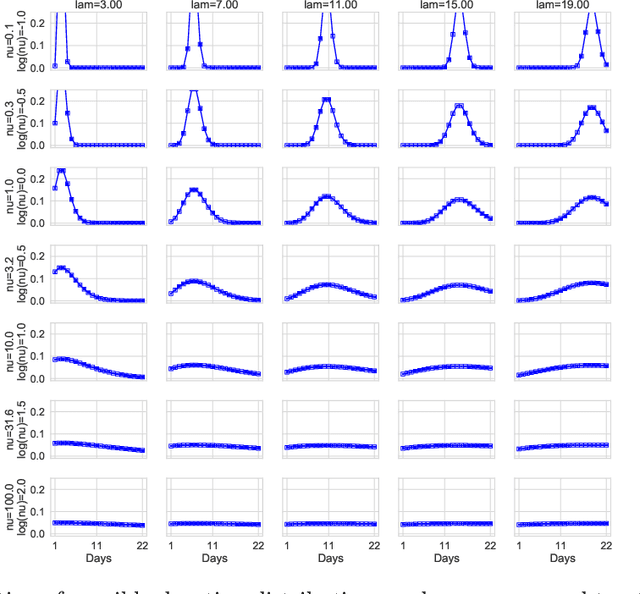
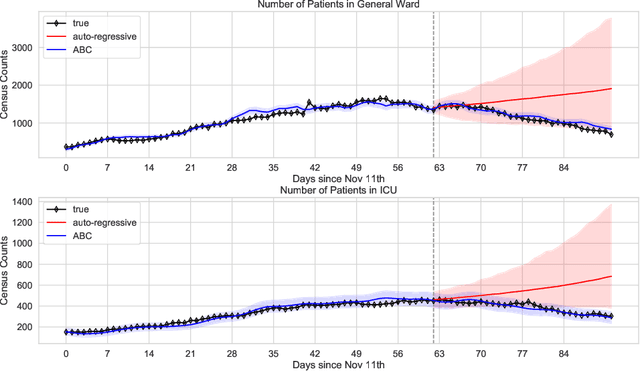
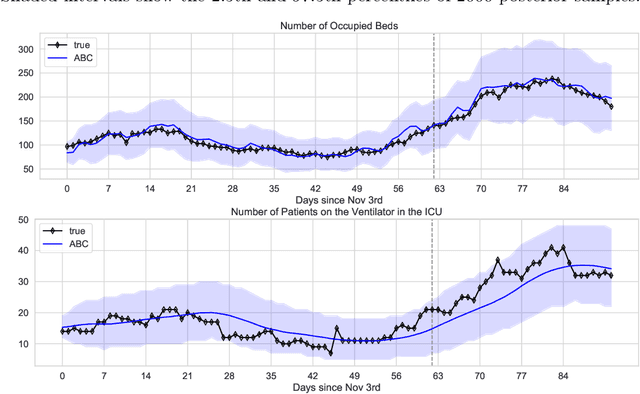
We address the problem of modeling constrained hospital resources in the midst of the COVID-19 pandemic in order to inform decision-makers of future demand and assess the societal value of possible interventions. For broad applicability, we focus on the common yet challenging scenario where patient-level data for a region of interest are not available. Instead, given daily admissions counts, we model aggregated counts of observed resource use, such as the number of patients in the general ward, in the intensive care unit, or on a ventilator. In order to explain how individual patient trajectories produce these counts, we propose an aggregate count explicit-duration hidden Markov model, nicknamed the ACED-HMM, with an interpretable, compact parameterization. We develop an Approximate Bayesian Computation approach that draws samples from the posterior distribution over the model's transition and duration parameters given aggregate counts from a specific location, thus adapting the model to a region or individual hospital site of interest. Samples from this posterior can then be used to produce future forecasts of any counts of interest. Using data from the United States and the United Kingdom, we show our mechanistic approach provides competitive probabilistic forecasts for the future even as the dynamics of the pandemic shift. Furthermore, we show how our model provides insight about recovery probabilities or length of stay distributions, and we suggest its potential to answer challenging what-if questions about the societal value of possible interventions.
A standardized framework for risk-based assessment of treatment effect heterogeneity in observational healthcare databases
Oct 13, 2020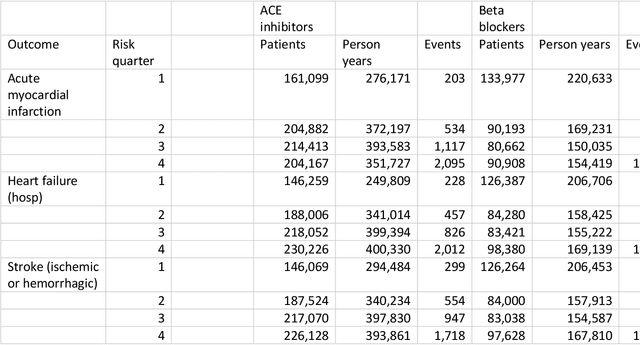
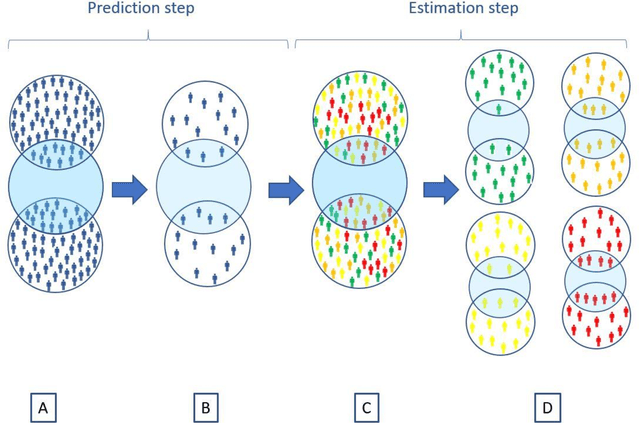

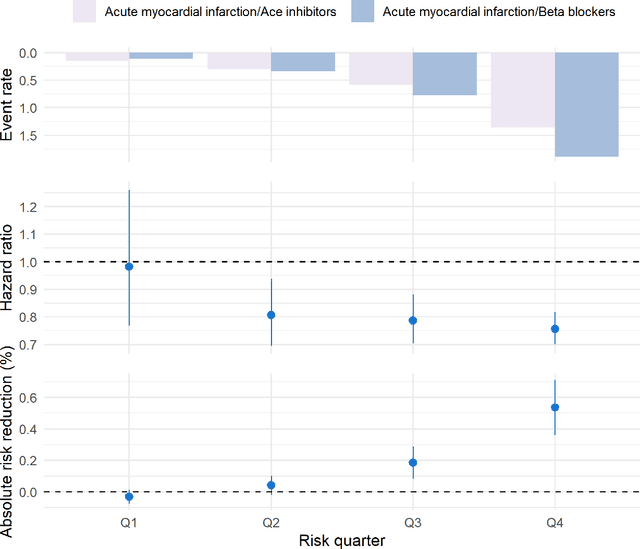
Aim: One of the aims of the Observation Health Data Sciences and Informatics (OHDSI) initiative is population-level treatment effect estimation in large observational databases. Since treatment effects are well-known to vary across groups of patients with different baseline risk, we aimed to extend the OHDSI methods library with a framework for risk-based assessment of treatment effect heterogeneity. Materials and Methods: The proposed framework consists of five steps: 1) definition of the problem, i.e. the population, the treatment, the comparator and the outcome(s) of interest; 2) identification of relevant databases; 3) development of a prediction model for the outcome(s) of interest; 4) estimation of propensity scores within strata of predicted risk and estimation of relative and absolute treatment effect within strata of predicted risk; 5) evaluation and presentation of results. Results: We demonstrate our framework by evaluating heterogeneity of the effect of angiotensin-converting enzyme (ACE) inhibitors versus beta blockers on a set of 9 outcomes of interest across three observational databases. With increasing risk of acute myocardial infarction we observed increasing absolute benefits, i.e. from -0.03% to 0.54% in the lowest to highest risk groups. Cough-related absolute harms decreased from 4.1% to 2.6%. Conclusions: The proposed framework may be useful for the evaluation of heterogeneity of treatment effect on observational data that are mapped to the OMOP Common Data Model. The proof of concept study demonstrates its feasibility in large observational data. Further insights may arise by application to safety and effectiveness questions across the global data network.