 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Context-Aware Person Fall Detection
Apr 11, 2024
As the global population ages, the number of fall-related incidents is on the rise. Effective fall detection systems, specifically in healthcare sector, are crucial to mitigate the risks associated with such events. This study evaluates the role of visual context, including background objects, on the accuracy of fall detection classifiers. We present a segmentation pipeline to semi-automatically separate individuals and objects in images. Well-established models like ResNet-18, EfficientNetV2-S, and Swin-Small are trained and evaluated. During training, pixel-based transformations are applied to segmented objects, and the models are then evaluated on raw images without segmentation. Our findings highlight the significant influence of visual context on fall detection. The application of Gaussian blur to the image background notably improves the performance and generalization capabilities of all models. Background objects such as beds, chairs, or wheelchairs can challenge fall detection systems, leading to false positive alarms. However, we demonstrate that object-specific contextual transformations during training effectively mitigate this challenge. Further analysis using saliency maps supports our observation that visual context is crucial in classification tasks. We create both dataset processing API and segmentation pipeline, available at https://github.com/A-NGJ/image-segmentation-cli.
Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting
Apr 01, 2024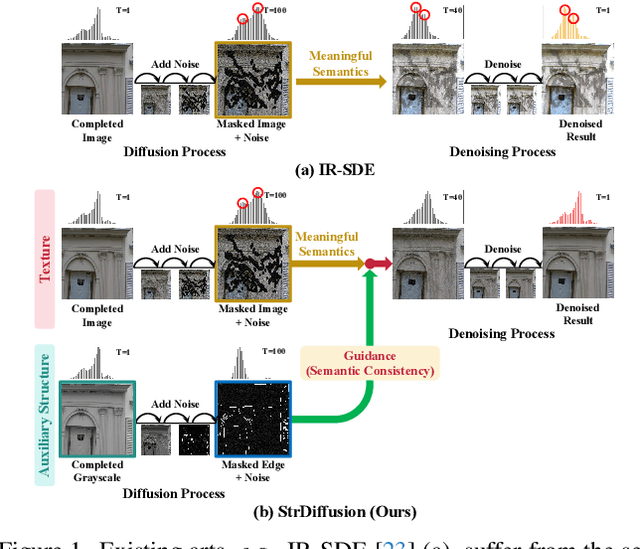
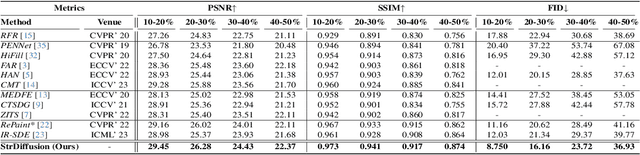
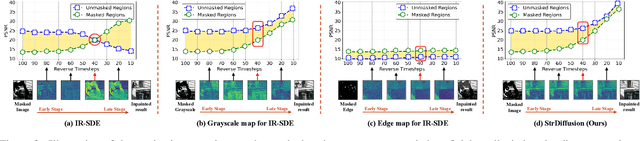
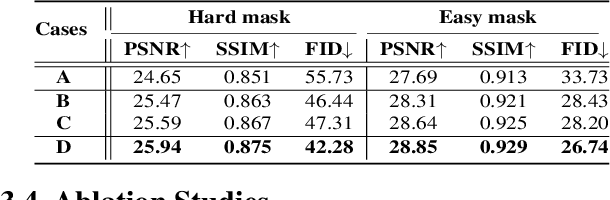
Denoising diffusion probabilistic models for image inpainting aim to add the noise to the texture of image during the forward process and recover masked regions with unmasked ones of the texture via the reverse denoising process.Despite the meaningful semantics generation,the existing arts suffer from the semantic discrepancy between masked and unmasked regions, since the semantically dense unmasked texture fails to be completely degraded while the masked regions turn to the pure noise in diffusion process,leading to the large discrepancy between them. In this paper,we aim to answer how unmasked semantics guide texture denoising process;together with how to tackle the semantic discrepancy,to facilitate the consistent and meaningful semantics generation. To this end,we propose a novel structure-guided diffusion model named StrDiffusion,to reformulate the conventional texture denoising process under structure guidance to derive a simplified denoising objective for image inpainting,while revealing:1)the semantically sparse structure is beneficial to tackle semantic discrepancy in early stage, while dense texture generates reasonable semantics in late stage;2)the semantics from unmasked regions essentially offer the time-dependent structure guidance for the texture denoising process,benefiting from the time-dependent sparsity of the structure semantics.For the denoising process,a structure-guided neural network is trained to estimate the simplified denoising objective by exploiting the consistency of the denoised structure between masked and unmasked regions.Besides,we devise an adaptive resampling strategy as a formal criterion as whether structure is competent to guide the texture denoising process,while regulate their semantic correlations.Extensive experiments validate the merits of StrDiffusion over the state-of-the-arts.Our code is available at https://github.com/htyjers/StrDiffusion.
Who Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
Apr 05, 2024With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness-the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented against few weak baselines by correlation to human Likert scores over a set of easy-to-discriminate images. We introduce T2IScoreScore (TS2), a curated set of semantic error graphs containing a prompt and a set increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.
Harnessing The Power of Attention For Patch-Based Biomedical Image Classification
Apr 01, 2024Biomedical image analysis can be facilitated by an innovative architecture rooted in self-attention mechanisms. The traditional convolutional neural network (CNN), characterized by fixed-sized windows, needs help capturing intricate spatial and temporal relations at the pixel level. The immutability of CNN filter weights post-training further restricts input fluctuations. Recognizing these limitations, we propose a new paradigm of attention-based models instead of convolutions. As an alternative to traditional CNNs, these models demonstrate robust modelling capabilities and the ability to grasp comprehensive long-range contextual information efficiently. Providing a solution to critical challenges faced by attention-based vision models such as inductive bias, weight sharing, receptive field limitations, and data handling in high resolution, our work combines non-overlapping (vanilla patching) with novel overlapped Shifted Patching Techniques (S.P.T.s) to induce local context that enhances model generalization. Moreover, we examine the novel Lancoz5 interpolation technique, which adapts variable image sizes to higher resolutions. Experimental evidence validates our model's generalization effectiveness, comparing favourably with existing approaches. Attention-based methods are particularly effective with ample data, especially when advanced data augmentation methodologies are integrated to strengthen their robustness.
Reconstructing Hand-Held Objects in 3D
Apr 10, 2024Objects manipulated by the hand (i.e., manipulanda) are particularly challenging to reconstruct from in-the-wild RGB images or videos. Not only does the hand occlude much of the object, but also the object is often only visible in a small number of image pixels. At the same time, two strong anchors emerge in this setting: (1) estimated 3D hands help disambiguate the location and scale of the object, and (2) the set of manipulanda is small relative to all possible objects. With these insights in mind, we present a scalable paradigm for handheld object reconstruction that builds on recent breakthroughs in large language/vision models and 3D object datasets. Our model, MCC-Hand-Object (MCC-HO), jointly reconstructs hand and object geometry given a single RGB image and inferred 3D hand as inputs. Subsequently, we use GPT-4(V) to retrieve a 3D object model that matches the object in the image and rigidly align the model to the network-inferred geometry; we call this alignment Retrieval-Augmented Reconstruction (RAR). Experiments demonstrate that MCC-HO achieves state-of-the-art performance on lab and Internet datasets, and we show how RAR can be used to automatically obtain 3D labels for in-the-wild images of hand-object interactions.
Burst Super-Resolution with Diffusion Models for Improving Perceptual Quality
Apr 08, 2024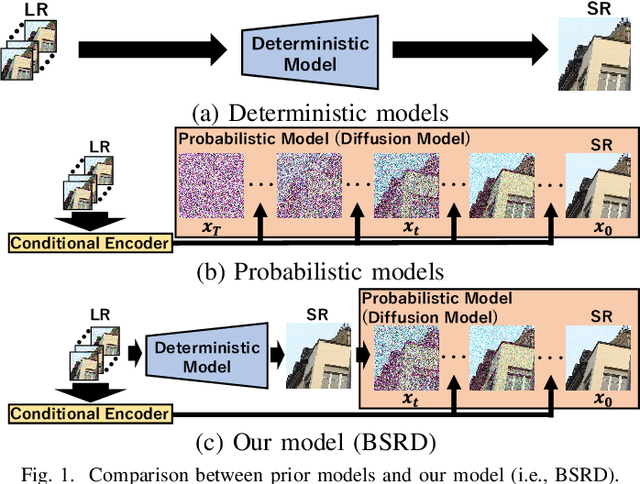
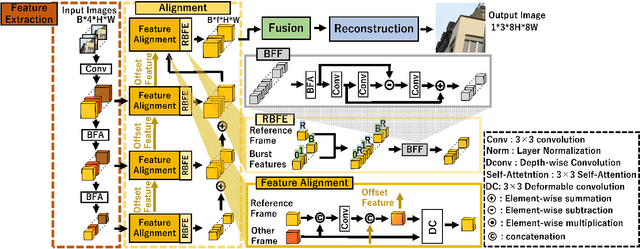
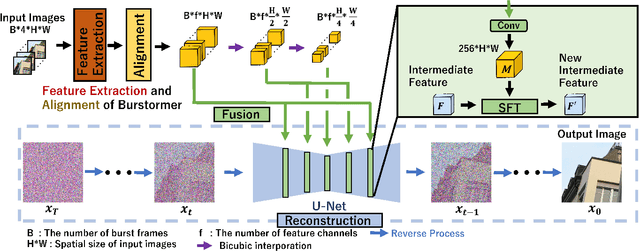
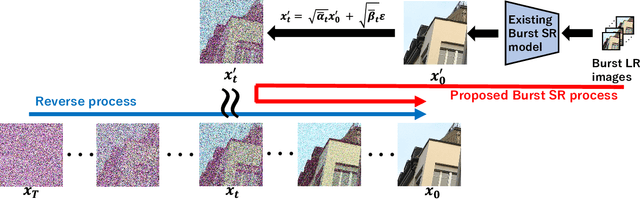
While burst LR images are useful for improving the SR image quality compared with a single LR image, prior SR networks accepting the burst LR images are trained in a deterministic manner, which is known to produce a blurry SR image. In addition, it is difficult to perfectly align the burst LR images, making the SR image more blurry. Since such blurry images are perceptually degraded, we aim to reconstruct the sharp high-fidelity boundaries. Such high-fidelity images can be reconstructed by diffusion models. However, prior SR methods using the diffusion model are not properly optimized for the burst SR task. Specifically, the reverse process starting from a random sample is not optimized for image enhancement and restoration methods, including burst SR. In our proposed method, on the other hand, burst LR features are used to reconstruct the initial burst SR image that is fed into an intermediate step in the diffusion model. This reverse process from the intermediate step 1) skips diffusion steps for reconstructing the global structure of the image and 2) focuses on steps for refining detailed textures. Our experimental results demonstrate that our method can improve the scores of the perceptual quality metrics. Code: https://github.com/placerkyo/BSRD
TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
Mar 25, 2024Recent advances in text-to-video generation have demonstrated the utility of powerful diffusion models. Nevertheless, the problem is not trivial when shaping diffusion models to animate static image (i.e., image-to-video generation). The difficulty originates from the aspect that the diffusion process of subsequent animated frames should not only preserve the faithful alignment with the given image but also pursue temporal coherence among adjacent frames. To alleviate this, we present TRIP, a new recipe of image-to-video diffusion paradigm that pivots on image noise prior derived from static image to jointly trigger inter-frame relational reasoning and ease the coherent temporal modeling via temporal residual learning. Technically, the image noise prior is first attained through one-step backward diffusion process based on both static image and noised video latent codes. Next, TRIP executes a residual-like dual-path scheme for noise prediction: 1) a shortcut path that directly takes image noise prior as the reference noise of each frame to amplify the alignment between the first frame and subsequent frames; 2) a residual path that employs 3D-UNet over noised video and static image latent codes to enable inter-frame relational reasoning, thereby easing the learning of the residual noise for each frame. Furthermore, both reference and residual noise of each frame are dynamically merged via attention mechanism for final video generation. Extensive experiments on WebVid-10M, DTDB and MSR-VTT datasets demonstrate the effectiveness of our TRIP for image-to-video generation. Please see our project page at https://trip-i2v.github.io/TRIP/.
SGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.
RSMamba: Remote Sensing Image Classification with State Space Model
Mar 28, 2024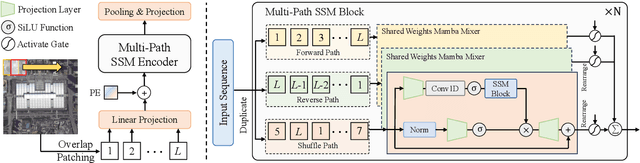
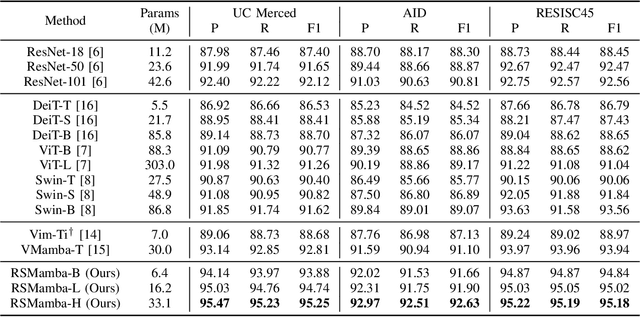
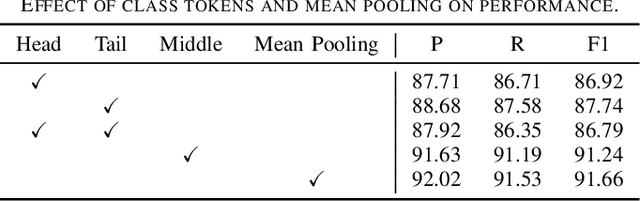
Remote sensing image classification forms the foundation of various understanding tasks, serving a crucial function in remote sensing image interpretation. The recent advancements of Convolutional Neural Networks (CNNs) and Transformers have markedly enhanced classification accuracy. Nonetheless, remote sensing scene classification remains a significant challenge, especially given the complexity and diversity of remote sensing scenarios and the variability of spatiotemporal resolutions. The capacity for whole-image understanding can provide more precise semantic cues for scene discrimination. In this paper, we introduce RSMamba, a novel architecture for remote sensing image classification. RSMamba is based on the State Space Model (SSM) and incorporates an efficient, hardware-aware design known as the Mamba. It integrates the advantages of both a global receptive field and linear modeling complexity. To overcome the limitation of the vanilla Mamba, which can only model causal sequences and is not adaptable to two-dimensional image data, we propose a dynamic multi-path activation mechanism to augment Mamba's capacity to model non-causal data. Notably, RSMamba maintains the inherent modeling mechanism of the vanilla Mamba, yet exhibits superior performance across multiple remote sensing image classification datasets. This indicates that RSMamba holds significant potential to function as the backbone of future visual foundation models. The code will be available at \url{https://github.com/KyanChen/RSMamba}.
SCINeRF: Neural Radiance Fields from a Snapshot Compressive Image
Mar 29, 2024
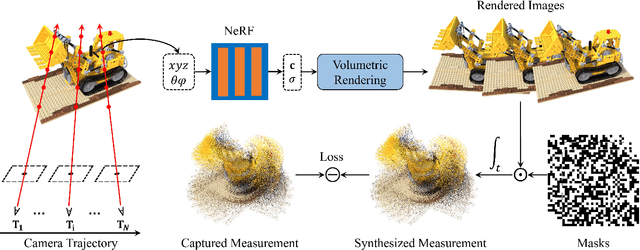


In this paper, we explore the potential of Snapshot Compressive Imaging (SCI) technique for recovering the underlying 3D scene representation from a single temporal compressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspectral or temporal information, into a single image using low-cost 2D imaging sensors. To achieve this, a series of specially designed 2D masks are usually employed, which not only reduces storage requirements but also offers potential privacy protection. Inspired by this, to take one step further, our approach builds upon the powerful 3D scene representation capabilities of neural radiance fields (NeRF). Specifically, we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene structures. To assess the effectiveness of our method, we conduct extensive evaluations using both synthetic data and real data captured by our SCI system. Extensive experimental results demonstrate that our proposed approach surpasses the state-of-the-art methods in terms of image reconstruction and novel view image synthesis. Moreover, our method also exhibits the ability to restore high frame-rate multi-view consistent images by leveraging SCI and the rendering capabilities of NeRF. The code is available at https://github.com/WU-CVGL/SCINeRF.