 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDFFDNet: Towards Accurate and Efficient Unsupervised Multi-Grid Image Registration
Sep 09, 2025Previous deep image registration methods that employ single homography, multi-grid homography, or thin-plate spline often struggle with real scenes containing depth disparities due to their inherent limitations. To address this, we propose an Exponential-Decay Free-Form Deformation Network (EDFFDNet), which employs free-form deformation with an exponential-decay basis function. This design achieves higher efficiency and performs well in scenes with depth disparities, benefiting from its inherent locality. We also introduce an Adaptive Sparse Motion Aggregator (ASMA), which replaces the MLP motion aggregator used in previous methods. By transforming dense interactions into sparse ones, ASMA reduces parameters and improves accuracy. Additionally, we propose a progressive correlation refinement strategy that leverages global-local correlation patterns for coarse-to-fine motion estimation, further enhancing efficiency and accuracy. Experiments demonstrate that EDFFDNet reduces parameters, memory, and total runtime by 70.5%, 32.6%, and 33.7%, respectively, while achieving a 0.5 dB PSNR gain over the state-of-the-art method. With an additional local refinement stage,EDFFDNet-2 further improves PSNR by 1.06 dB while maintaining lower computational costs. Our method also demonstrates strong generalization ability across datasets, outperforming previous deep learning methods.
SGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024



Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.
Deep Dual Consecutive Network for Human Pose Estimation
Mar 19, 2021
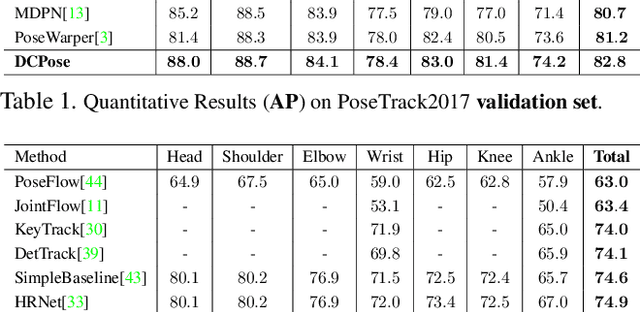
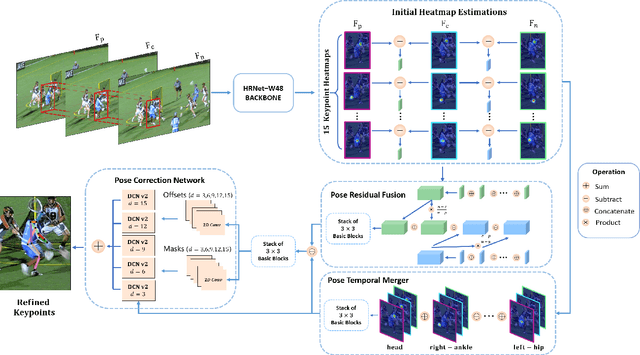
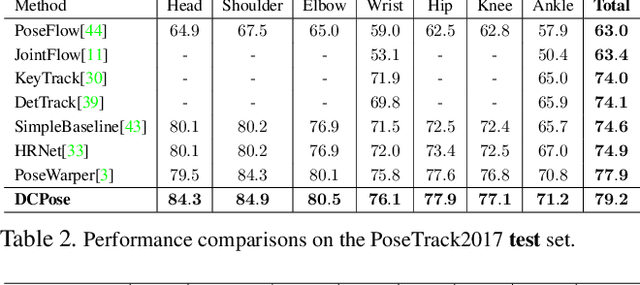
Multi-frame human pose estimation in complicated situations is challenging. Although state-of-the-art human joints detectors have demonstrated remarkable results for static images, their performances come short when we apply these models to video sequences. Prevalent shortcomings include the failure to handle motion blur, video defocus, or pose occlusions, arising from the inability in capturing the temporal dependency among video frames. On the other hand, directly employing conventional recurrent neural networks incurs empirical difficulties in modeling spatial contexts, especially for dealing with pose occlusions. In this paper, we propose a novel multi-frame human pose estimation framework, leveraging abundant temporal cues between video frames to facilitate keypoint detection. Three modular components are designed in our framework. A Pose Temporal Merger encodes keypoint spatiotemporal context to generate effective searching scopes while a Pose Residual Fusion module computes weighted pose residuals in dual directions. These are then processed via our Pose Correction Network for efficient refining of pose estimations. Our method ranks No.1 in the Multi-frame Person Pose Estimation Challenge on the large-scale benchmark datasets PoseTrack2017 and PoseTrack2018. We have released our code, hoping to inspire future research.