 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Incremental Learning Techniques for Semantic Segmentation
Sep 17, 2019
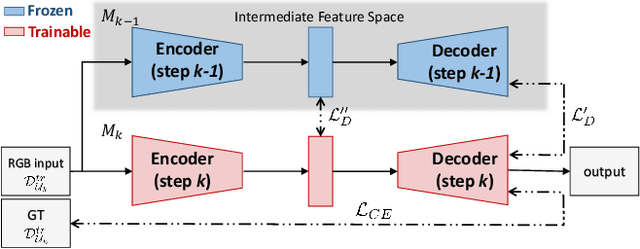
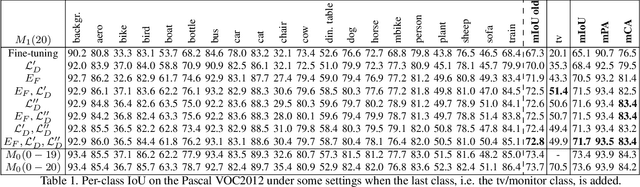
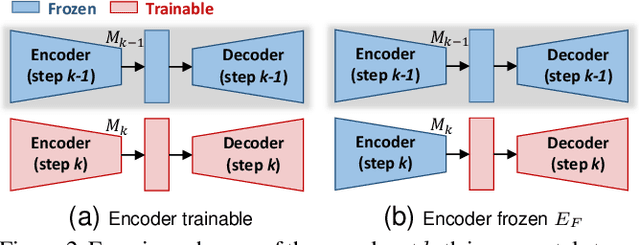
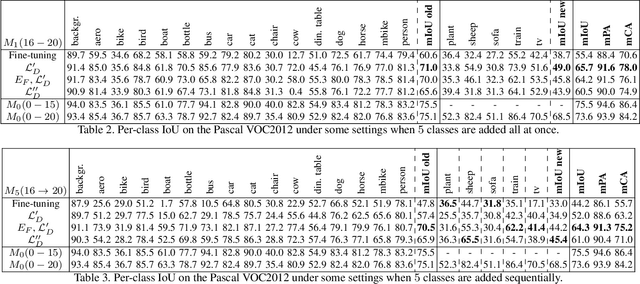
Deep learning architectures exhibit a critical drop of performance due to catastrophic forgetting when they are required to incrementally learn new tasks. Contemporary incremental learning frameworks focus on image classification and object detection while in this work we formally introduce the incremental learning problem for semantic segmentation in which a pixel-wise labeling is considered. To tackle this task we propose to distill the knowledge of the previous model to retain the information about previously learned classes, whilst updating the current model to learn the new ones. We propose various approaches working both on the output logits and on intermediate features. In opposition to some recent frameworks, we do not store any image from previously learned classes and only the last model is needed to preserve high accuracy on these classes. The experimental evaluation on the Pascal VOC2012 dataset shows the effectiveness of the proposed approaches.
* 8 pages, 3 figures, 4 tables
Deep Unsupervised Common Representation Learning for LiDAR and Camera Data using Double Siamese Networks
Jan 03, 2020
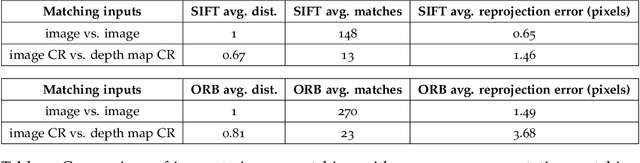

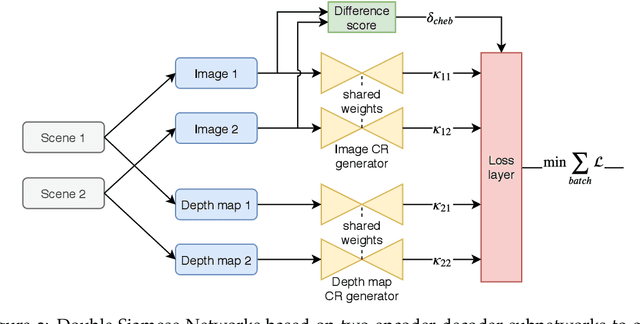
Domain gaps of sensor modalities pose a challenge for the design of autonomous robots. Taking a step towards closing this gap, we propose two unsupervised training frameworks for finding a common representation of LiDAR and camera data. The first method utilizes a double Siamese training structure to ensure consistency in the results. The second method uses a Canny edge image guiding the networks towards a desired representation. All networks are trained in an unsupervised manner, leaving room for scalability. The results are evaluated using common computer vision applications, and the limitations of the proposed approaches are outlined.
Resolution Enhancement of Range Images via Color-Image Segmentation
Oct 28, 2012


We report a method for super-resolution of range images. Our approach leverages the interpretation of LR image as sparse samples on the HR grid. Based on this interpretation, we demonstrate that our recently reported approach, which reconstructs dense range images from sparse range data by exploiting a registered colour image, can be applied for the task of resolution enhancement of range images. Our method only uses a single colour image in addition to the range observation in the super-resolution process. Using the proposed approach, we demonstrate super-resolution results for large factors (e.g. 4) with good localization accuracy.
Embodied Language Grounding with Implicit 3D Visual Feature Representations
Oct 02, 2019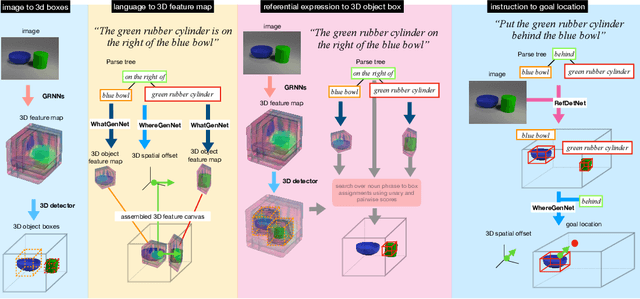



Consider the utterance "the tomato is to the left of the pot." Humans can answer numerous questions about the situation described, as well as reason through counterfactuals and alternatives, such as, "is the pot larger than the tomato ?", "can we move to a viewpoint from which the tomato is completely hidden behind the pot ?", "can we have an object that is both to the left of the tomato and to the right of the pot ?", "would the tomato fit inside the pot ?", and so on. Such reasoning capability remains elusive from current computational models of language understanding. To link language processing with spatial reasoning, we propose associating natural language utterances to a mental workspace of their meaning, encoded as 3-dimensional visual feature representations of the world scenes they describe. We learn such 3-dimensional visual representations---we call them visual imaginations--- by predicting images a mobile agent sees while moving around in the 3D world. The input image streams the agent collects are unprojected into egomotion-stable 3D scene feature maps of the scene, and projected from novel viewpoints to match the observed RGB image views in an end-to-end differentiable manner. We then train modular neural models to generate such 3D feature representations given language utterances, to localize the objects an utterance mentions in the 3D feature representation inferred from an image, and to predict the desired 3D object locations given a manipulation instruction. We empirically show the proposed models outperform by a large margin existing 2D models in spatial reasoning, referential object detection and instruction following, and generalize better across camera viewpoints and object arrangements.
MiniNet: An extremely lightweight convolutional neural network for real-time unsupervised monocular depth estimation
Jun 27, 2020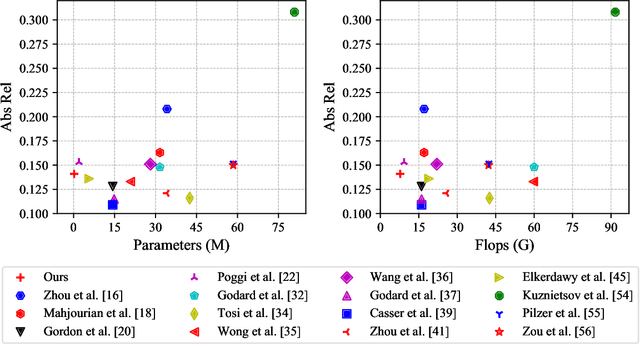
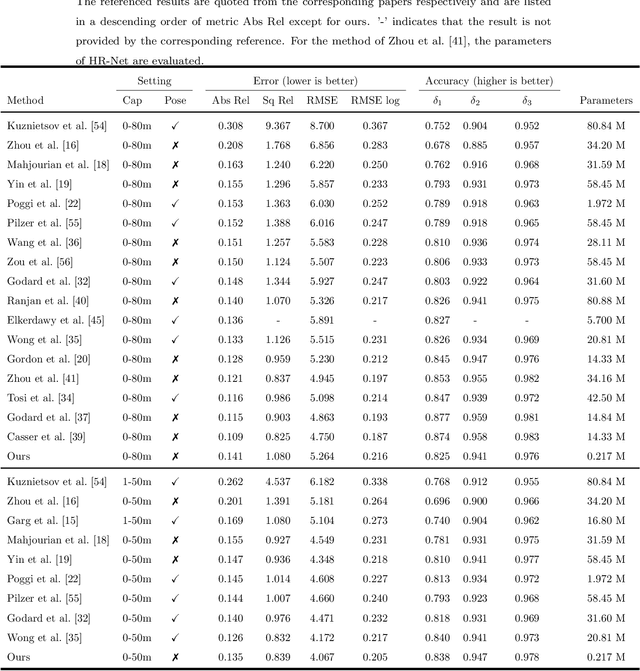
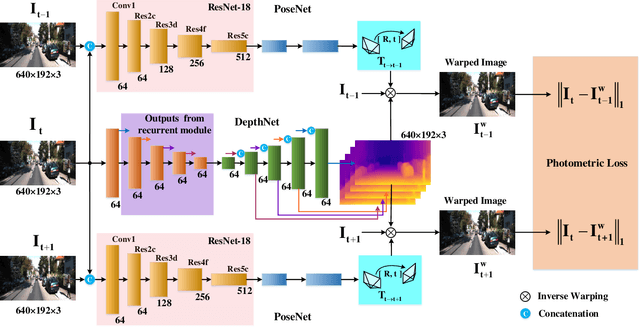
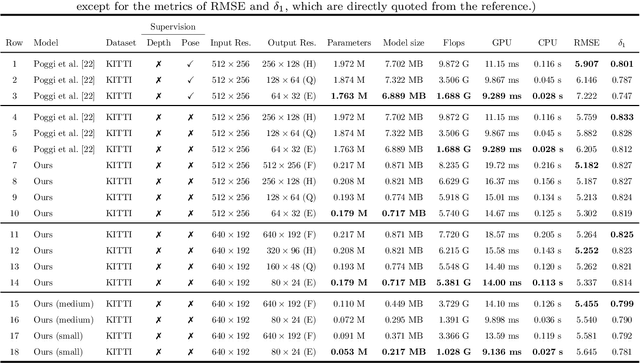
Predicting depth from a single image is an attractive research topic since it provides one more dimension of information to enable machines to better perceive the world. Recently, deep learning has emerged as an effective approach to monocular depth estimation. As obtaining labeled data is costly, there is a recent trend to move from supervised learning to unsupervised learning to obtain monocular depth. However, most unsupervised learning methods capable of achieving high depth prediction accuracy will require a deep network architecture which will be too heavy and complex to run on embedded devices with limited storage and memory spaces. To address this issue, we propose a new powerful network with a recurrent module to achieve the capability of a deep network while at the same time maintaining an extremely lightweight size for real-time high performance unsupervised monocular depth prediction from video sequences. Besides, a novel efficient upsample block is proposed to fuse the features from the associated encoder layer and recover the spatial size of features with the small number of model parameters. We validate the effectiveness of our approach via extensive experiments on the KITTI dataset. Our new model can run at a speed of about 110 frames per second (fps) on a single GPU, 37 fps on a single CPU, and 2 fps on a Raspberry Pi 3. Moreover, it achieves higher depth accuracy with nearly 33 times fewer model parameters than state-of-the-art models. To the best of our knowledge, this work is the first extremely lightweight neural network trained on monocular video sequences for real-time unsupervised monocular depth estimation, which opens up the possibility of implementing deep learning-based real-time unsupervised monocular depth prediction on low-cost embedded devices.
LADN: Local Adversarial Disentangling Network for Facial Makeup and De-Makeup
Apr 25, 2019

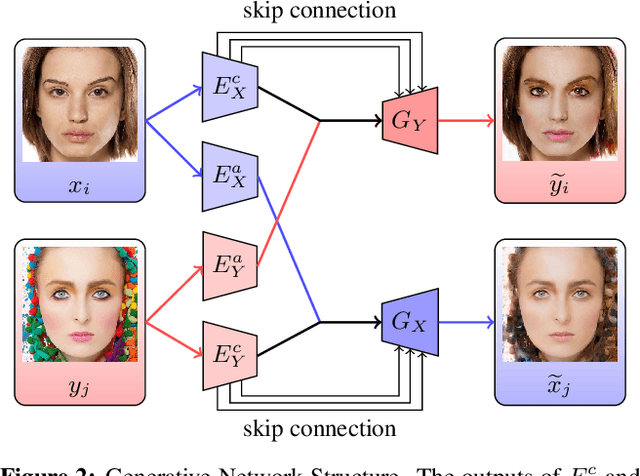
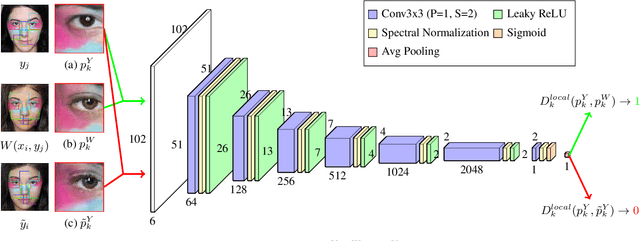
We propose a local adversarial disentangling network (LADN) for facial makeup and de-makeup. Central to our method are multiple and overlapping local adversarial discriminators in a content-style disentangling network for achieving local detail transfer between facial images, with the use of asymmetric loss functions for dramatic makeup styles with high-frequency details. Existing techniques do not demonstrate or fail to transfer high-frequency details in a global adversarial setting, or train a single local discriminator only to ensure image structure consistency and thus work only for relatively simple styles. Unlike others, our proposed local adversarial discriminators can distinguish whether the generated local image details are consistent with the corresponding regions in the given reference image in cross-image style transfer in an unsupervised setting. Incorporating these technical contributions, we achieve not only state-of-the-art results on conventional styles but also novel results involving complex and dramatic styles with high-frequency details covering large areas across multiple facial features. A carefully designed dataset of unpaired before and after makeup images will be released.
Multi-organ Segmentation over Partially Labeled Datasets with Multi-scale Feature Abstraction
Jan 01, 2020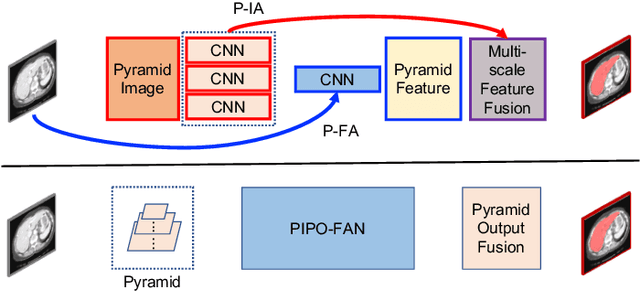
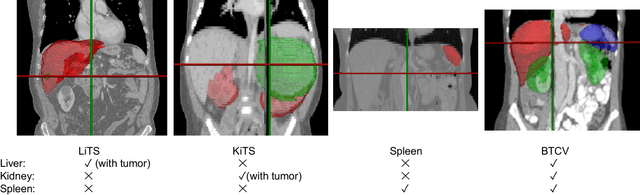
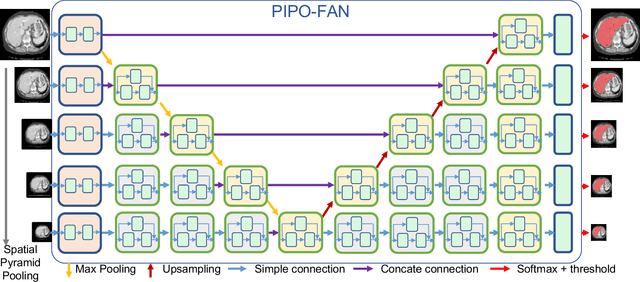
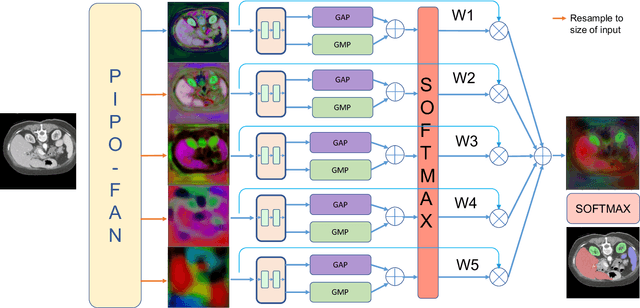
This paper presents a unified training strategy that enables a novel multi-scale deep neural network to be trained on multiple partially labeled datasets for multi-organ segmentation. Multi-scale contextual information is effective for pixel-level label prediction, i.e. image segmentation. However, such important information is only partially exploited by the existing methods. In this paper, we propose a new network architecture for multi-scale feature abstraction, which integrates pyramid feature analysis into an image segmentation model. To bridge the semantic gap caused by directly merging features from different scales, an equal convolutional depth mechanism is proposed. In addition, we develop a deep supervision mechanism for refining outputs in different scales. To fully leverage the segmentation features from different scales, we design an adaptive weighting layer to fuse the outputs in an automatic fashion. All these features together integrate into a pyramid-input pyramid-output network for efficient feature extraction. Last but not least, to alleviate the hunger for fully annotated data in training deep segmentation models, a unified training strategy is proposed to train one segmentation model on multiple partially labeled datasets for multi-organ segmentation with a novel target adaptive loss. Our proposed method was evaluated on four publicly available datasets, including BTCV, LiTS, KiTS and Spleen, where very promising performance has been achieved. The source code of this work is publicly shared at https://github.com/DIAL-RPI/PIPO-FAN for others to easily reproduce the work and build their own models with the introduced mechanisms.
On adversarial patches: real-world attack on ArcFace-100 face recognition system
Oct 15, 2019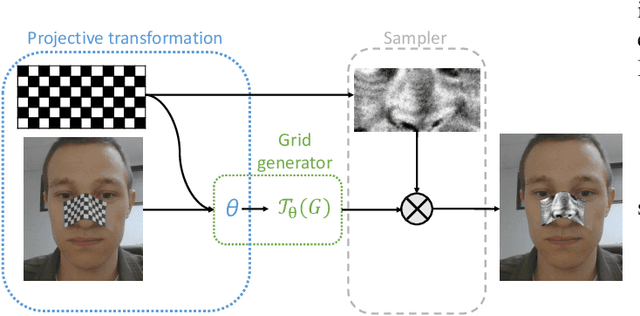
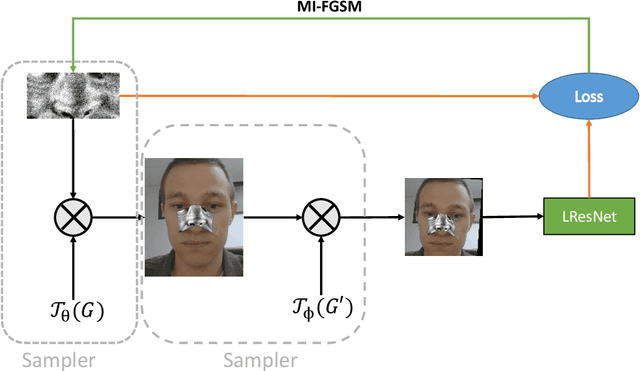


Recent works showed the vulnerability of image classifiers to adversarial attacks in the digital domain. However, the majority of attacks involve adding small perturbation to an image to fool the classifier. Unfortunately, such procedures can not be used to conduct a real-world attack, where adding an adversarial attribute to the photo is a more practical approach. In this paper, we study the problem of real-world attacks on face recognition systems. We examine security of one of the best public face recognition systems, LResNet100E-IR with ArcFace loss, and propose a simple method to attack it in the physical world. The method suggests creating an adversarial patch that can be printed, added as a face attribute and photographed; the photo of a person with such attribute is then passed to the classifier such that the classifier's recognized class changes from correct to the desired one. Proposed generating procedure allows projecting adversarial patches not only on different areas of the face, such as nose or forehead but also on some wearable accessory, such as eyeglasses.
Plug and play methods for magnetic resonance imaging
Mar 20, 2019
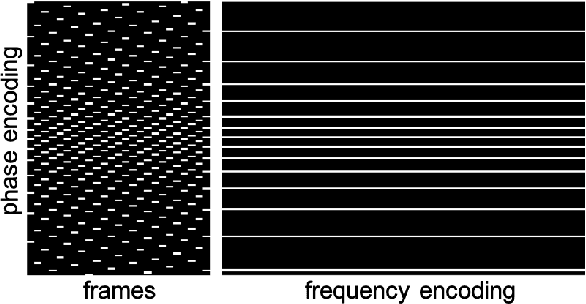
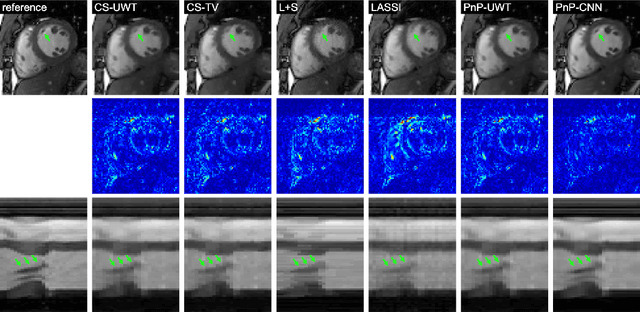
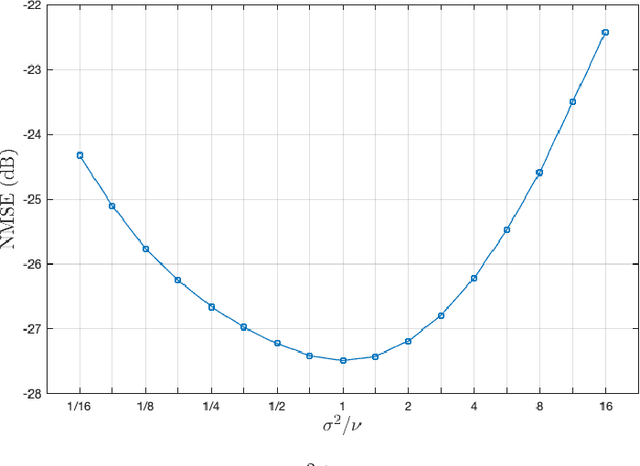
Magnetic Resonance Imaging (MRI) is a non-invasive diagnostic tool that provides excellent soft-tissue contrast without the use of ionizing radiation. But, compared to other clinical imaging modalities (e.g., CT or ultrasound), the data acquisition process for MRI is inherently slow. Furthermore, dynamic applications demand collecting a series of images in quick succession. As a result, reducing acquisition time and improving imaging quality for undersampled datasets have been active areas of research for the last two decades. The combination of parallel imaging and compressive sensing (CS) has been shown to benefit a wide range of MRI applications. More recently, deep learning techniques have been shown to outperform CS methods. Some of these techniques pose the MRI reconstruction as a direct inversion problem and tackle it by training a deep neural network (DNN) to map from the measured Fourier samples and the final image. Considering that the forward model in MRI changes from one dataset to the next, such methods have to be either trained over a large and diverse corpus of data or limited to a specific application, and even then they cannot ensure data consistency. An alternative is to use "plug-and-play" (PnP) algorithms, which iterate image denoising with forward-model based signal recovery. PnP algorithms are an excellent fit for compressive MRI because they decouple image modeling from the forward model, which can change significantly among different scans due to variations in the coil sensitivity maps, sampling patterns, and image resolution. Consequently, with PnP, state-of-the-art image-denoising techniques, such as those based on DNNs, can be directly exploited for compressive MRI image reconstruction. The objective of this article is two-fold: i) to review recent advances in plug-and-play methods, and ii) to discuss their application to compressive MRI image reconstruction.
Detecting Scatteredly-Distributed, Small, andCritically Important Objects in 3D OncologyImaging via Decision Stratification
May 27, 2020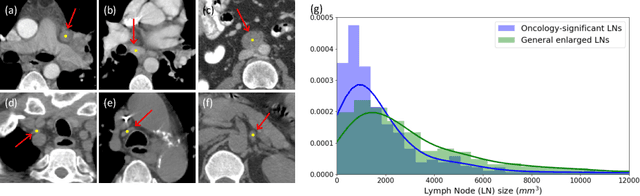
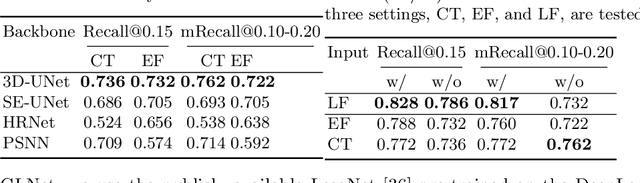
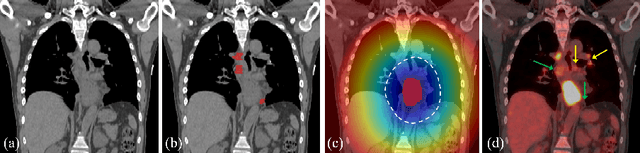
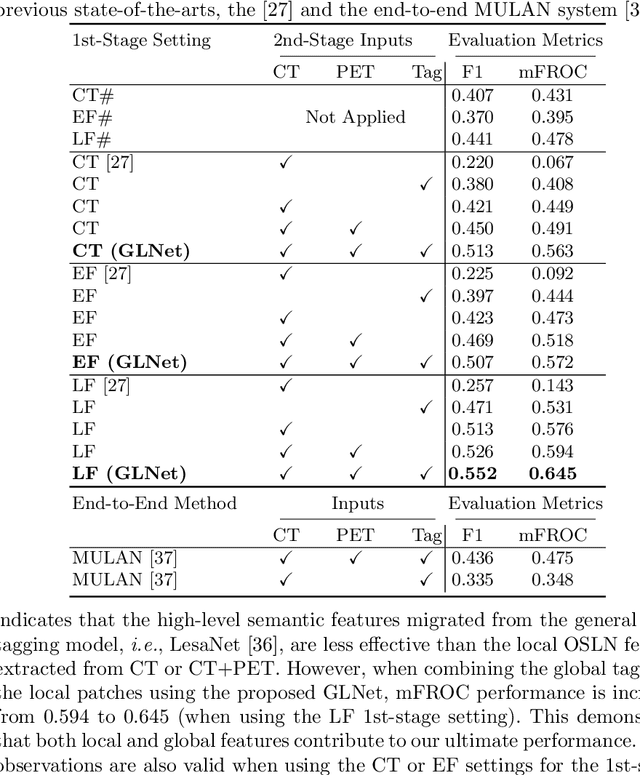
Finding and identifying scatteredly-distributed, small, and critically important objects in 3D oncology images is very challenging. We focus on the detection and segmentation of oncology-significant (or suspicious cancer metastasized) lymph nodes (OSLNs), which has not been studied before as a computational task. Determining and delineating the spread of OSLNs is essential in defining the corresponding resection/irradiating regions for the downstream workflows of surgical resection and radiotherapy of various cancers. For patients who are treated with radiotherapy, this task is performed by experienced radiation oncologists that involves high-level reasoning on whether LNs are metastasized, which is subject to high inter-observer variations. In this work, we propose a divide-and-conquer decision stratification approach that divides OSLNs into tumor-proximal and tumor-distal categories. This is motivated by the observation that each category has its own different underlying distributions in appearance, size and other characteristics. Two separate detection-by-segmentation networks are trained per category and fused. To further reduce false positives (FP), we present a novel global-local network (GLNet) that combines high-level lesion characteristics with features learned from localized 3D image patches. Our method is evaluated on a dataset of 141 esophageal cancer patients with PET and CT modalities (the largest to-date). Our results significantly improve the recall from $45\%$ to $67\%$ at $3$ FPs per patient as compared to previous state-of-the-art methods. The highest achieved OSLN recall of $0.828$ is clinically relevant and valuable.