 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Language Grounding with Implicit 3D Visual Feature Representations
Paper and Code
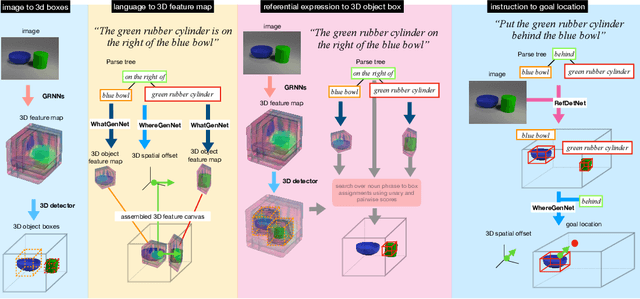



Consider the utterance "the tomato is to the left of the pot." Humans can answer numerous questions about the situation described, as well as reason through counterfactuals and alternatives, such as, "is the pot larger than the tomato ?", "can we move to a viewpoint from which the tomato is completely hidden behind the pot ?", "can we have an object that is both to the left of the tomato and to the right of the pot ?", "would the tomato fit inside the pot ?", and so on. Such reasoning capability remains elusive from current computational models of language understanding. To link language processing with spatial reasoning, we propose associating natural language utterances to a mental workspace of their meaning, encoded as 3-dimensional visual feature representations of the world scenes they describe. We learn such 3-dimensional visual representations---we call them visual imaginations--- by predicting images a mobile agent sees while moving around in the 3D world. The input image streams the agent collects are unprojected into egomotion-stable 3D scene feature maps of the scene, and projected from novel viewpoints to match the observed RGB image views in an end-to-end differentiable manner. We then train modular neural models to generate such 3D feature representations given language utterances, to localize the objects an utterance mentions in the 3D feature representation inferred from an image, and to predict the desired 3D object locations given a manipulation instruction. We empirically show the proposed models outperform by a large margin existing 2D models in spatial reasoning, referential object detection and instruction following, and generalize better across camera viewpoints and object arrangements.