 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FPGA based Parallelized Architecture of Efficient Graph based Image Segmentation Algorithm
Oct 06, 2017



Efficient and real time segmentation of color images has a variety of importance in many fields of computer vision such as image compression, medical imaging, mapping and autonomous navigation. Being one of the most computationally expensive operation, it is usually done through software imple- mentation using high-performance processors. In robotic systems, however, with the constrained platform dimensions and the need for portability, low power consumption and simultaneously the need for real time image segmentation, we envision hardware parallelism as the way forward to achieve higher acceleration. Field-programmable gate arrays (FPGAs) are among the best suited for this task as they provide high computing power in a small physical area. They exceed the computing speed of software based implementations by breaking the paradigm of sequential execution and accomplishing more per clock cycle operations by enabling hardware level parallelization at an architectural level. In this paper, we propose three novel architectures of a well known Efficient Graph based Image Segmentation algorithm. These proposed implementations optimizes time and power consumption when compared to software implementations. The hybrid design proposed, has notable furtherance of acceleration capabilities delivering atleast 2X speed gain over other implemen- tations, which henceforth allows real time image segmentation that can be deployed on Mobile Robotic systems.
Disentangle Perceptual Learning through Online Contrastive Learning
Jun 24, 2020
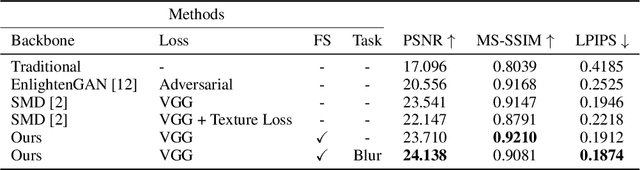

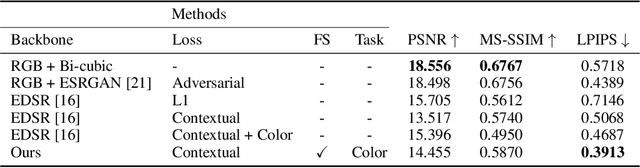
Pursuing realistic results according to human visual perception is the central concern in the image transformation tasks. Perceptual learning approaches like perceptual loss are empirically powerful for such tasks but they usually rely on the pre-trained classification network to provide features, which are not necessarily optimal in terms of visual perception of image transformation. In this paper, we argue that, among the features representation from the pre-trained classification network, only limited dimensions are related to human visual perception, while others are irrelevant, although both will affect the final image transformation results. Under such an assumption, we try to disentangle the perception-relevant dimensions from the representation through our proposed online contrastive learning. The resulted network includes the pre-training part and a feature selection layer, followed by the contrastive learning module, which utilizes the transformed results, target images, and task-oriented distorted images as the positive, negative, and anchor samples, respectively. The contrastive learning aims at activating the perception-relevant dimensions and suppressing the irrelevant ones by using the triplet loss, so that the original representation can be disentangled for better perceptual quality. Experiments on various image transformation tasks demonstrate the superiority of our framework, in terms of human visual perception, to the existing approaches using pre-trained networks and empirically designed losses.
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Jun 04, 2020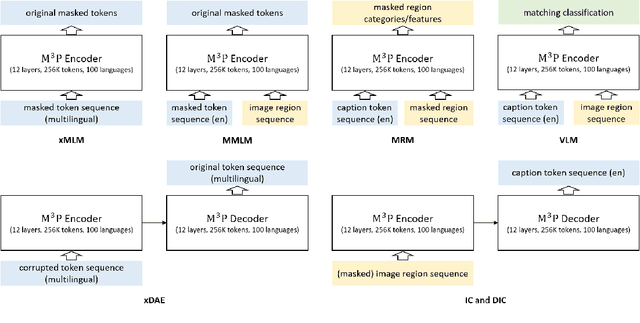


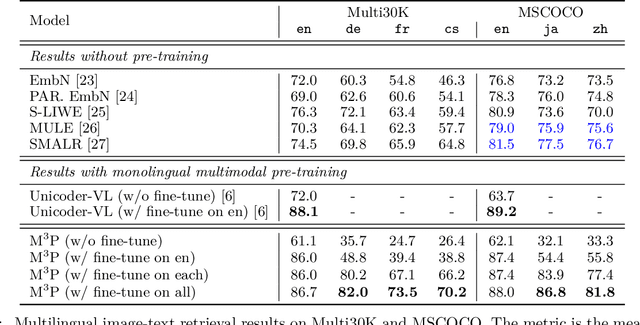
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine
CQ-VAE: Coordinate Quantized VAE for Uncertainty Estimation with Application to Disk Shape Analysis from Lumbar Spine MRI Images
Oct 17, 2020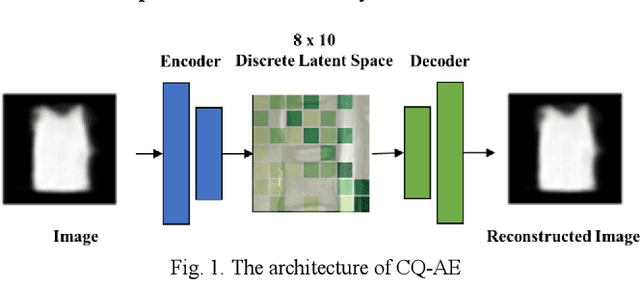
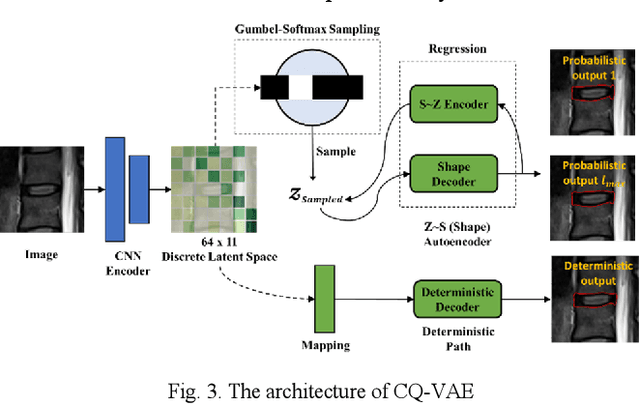
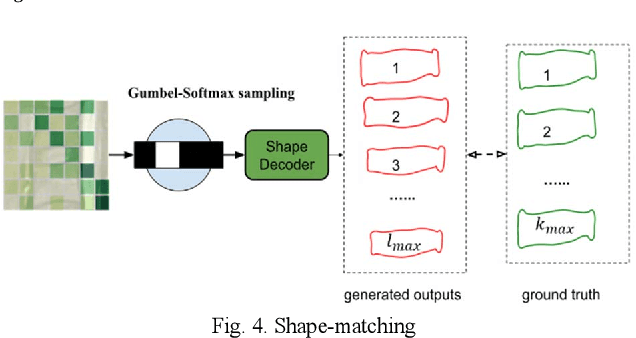
Ambiguity is inevitable in medical images, which often results in different image interpretations (e.g. object boundaries or segmentation maps) from different human experts. Thus, a model that learns the ambiguity and outputs a probability distribution of the target, would be valuable for medical applications to assess the uncertainty of diagnosis. In this paper, we propose a powerful generative model to learn a representation of ambiguity and to generate probabilistic outputs. Our model, named Coordinate Quantization Variational Autoencoder (CQ-VAE) employs a discrete latent space with an internal discrete probability distribution by quantizing the coordinates of a continuous latent space. As a result, the output distribution from CQ-VAE is discrete. During training, Gumbel-Softmax sampling is used to enable backpropagation through the discrete latent space. A matching algorithm is used to establish the correspondence between model-generated samples and "ground-truth" samples, which makes a trade-off between the ability to generate new samples and the ability to represent training samples. Besides these probabilistic components to generate possible outputs, our model has a deterministic path to output the best estimation. We demonstrated our method on a lumbar disk image dataset, and the results show that our CQ-VAE can learn lumbar disk shape variation and uncertainty.
Removing Undesirable Feature Contributions Using Out-of-Distribution Data
Jan 17, 2021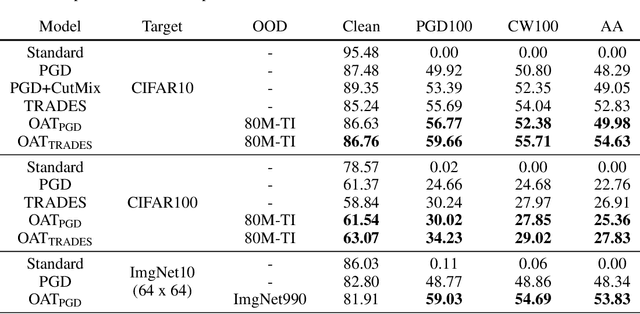
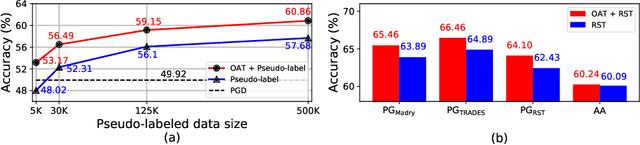

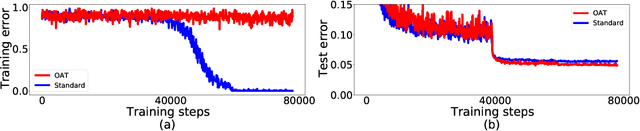
Several data augmentation methods deploy unlabeled-in-distribution (UID) data to bridge the gap between the training and inference of neural networks. However, these methods have clear limitations in terms of availability of UID data and dependence of algorithms on pseudo-labels. Herein, we propose a data augmentation method to improve generalization in both adversarial and standard learning by using out-of-distribution (OOD) data that are devoid of the abovementioned issues. We show how to improve generalization theoretically using OOD data in each learning scenario and complement our theoretical analysis with experiments on CIFAR-10, CIFAR-100, and a subset of ImageNet. The results indicate that undesirable features are shared even among image data that seem to have little correlation from a human point of view. We also present the advantages of the proposed method through comparison with other data augmentation methods, which can be used in the absence of UID data. Furthermore, we demonstrate that the proposed method can further improve the existing state-of-the-art adversarial training.
3D-Aided Data Augmentation for Robust Face Understanding
Oct 06, 2020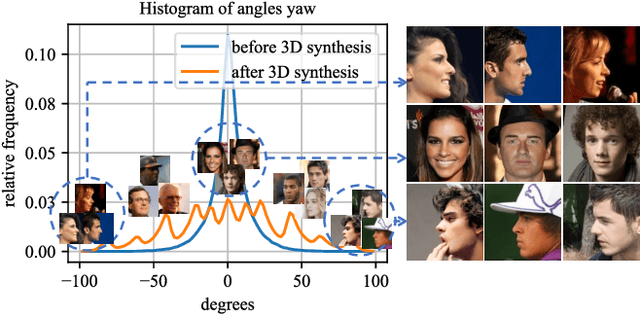

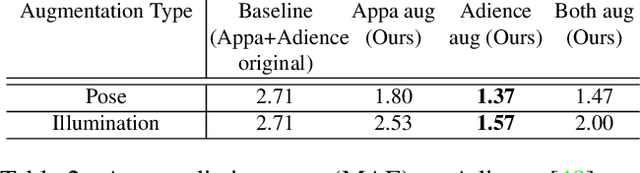
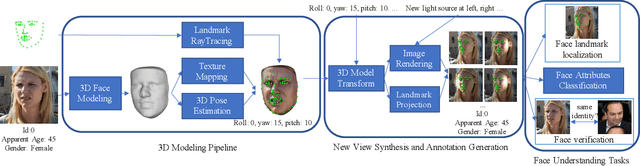
Data augmentation has been highly effective in narrowing the data gap and reducing the cost for human annotation, especially for tasks where ground truth labels are difficult and expensive to acquire. In face recognition, large pose and illumination variation of face images has been a key factor for performance degradation. However, human annotation for the various face understanding tasks including face landmark localization, face attributes classification and face recognition under these challenging scenarios are highly costly to acquire. Therefore, it would be desirable to perform data augmentation for these cases. But simple 2D data augmentation techniques on the image domain are not able to satisfy the requirement of these challenging cases. As such, 3D face modeling, in particular, single image 3D face modeling, stands a feasible solution for these challenging conditions beyond 2D based data augmentation. To this end, we propose a method that produces realistic 3D augmented images from multiple viewpoints with different illumination conditions through 3D face modeling, each associated with geometrically accurate face landmarks, attributes and identity information. Experiments demonstrate that the proposed 3D data augmentation method significantly improves the performance and robustness of various face understanding tasks while achieving state-of-arts on multiple benchmarks.
PrimA6D: Rotational Primitive Reconstruction for Enhanced and Robust 6D Pose Estimation
Jun 14, 2020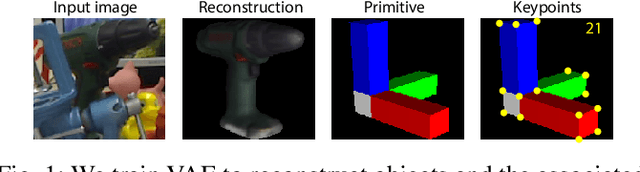
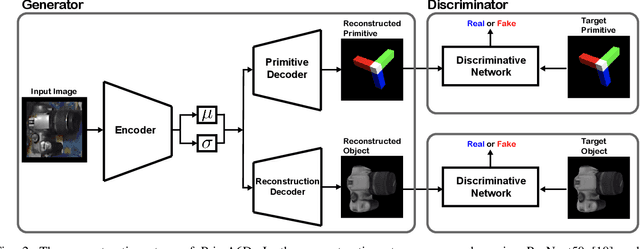
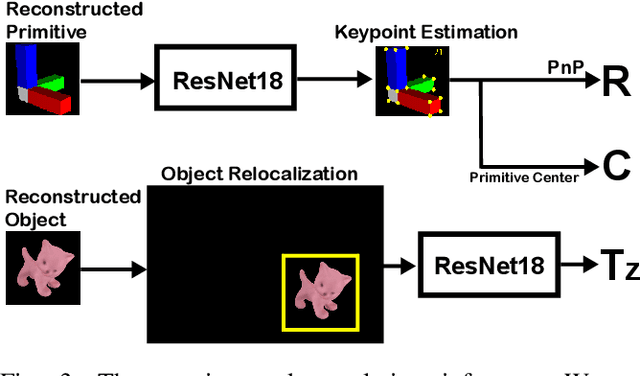

In this paper, we introduce a rotational primitive prediction based 6D object pose estimation using a single image as an input. We solve for the 6D object pose of a known object relative to the camera using a single image with occlusion. Many recent state-of-the-art (SOTA) two-step approaches have exploited image keypoints extraction followed by PnP regression for pose estimation. Instead of relying on bounding box or keypoints on the object, we propose to learn orientation-induced primitive so as to achieve the pose estimation accuracy regardless of the object size. We leverage a Variational AutoEncoder (VAE) to learn this underlying primitive and its associated keypoints. The keypoints inferred from the reconstructed primitive image are then used to regress the rotation using PnP. Lastly, we compute the translation in a separate localization module to complete the entire 6D pose estimation. When evaluated over public datasets, the proposed method yields a notable improvement over the LINEMOD, the Occlusion LINEMOD, and the YCB-Video dataset. We further provide a synthetic-only trained case presenting comparable performance to the existing methods which require real images in the training phase.
OntoZSL: Ontology-enhanced Zero-shot Learning
Feb 15, 2021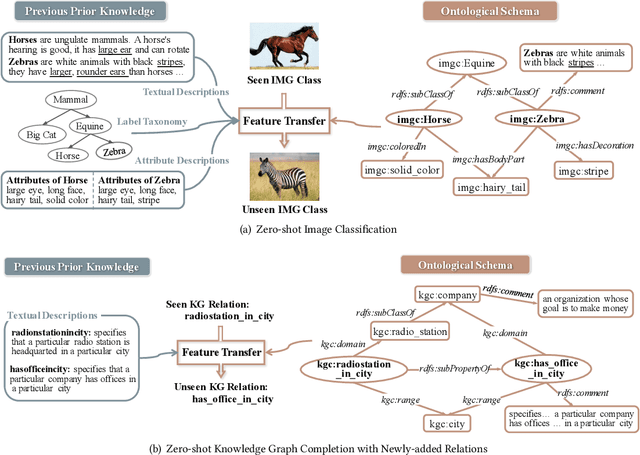

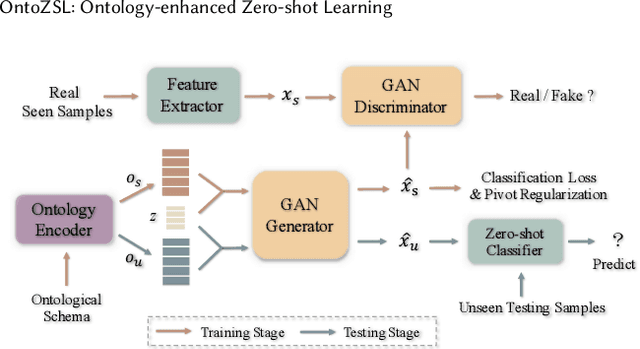
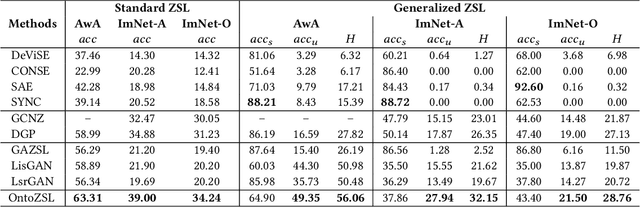
Zero-shot Learning (ZSL), which aims to predict for those classes that have never appeared in the training data, has arisen hot research interests. The key of implementing ZSL is to leverage the prior knowledge of classes which builds the semantic relationship between classes and enables the transfer of the learned models (e.g., features) from training classes (i.e., seen classes) to unseen classes. However, the priors adopted by the existing methods are relatively limited with incomplete semantics. In this paper, we explore richer and more competitive prior knowledge to model the inter-class relationship for ZSL via ontology-based knowledge representation and semantic embedding. Meanwhile, to address the data imbalance between seen classes and unseen classes, we developed a generative ZSL framework with Generative Adversarial Networks (GANs). Our main findings include: (i) an ontology-enhanced ZSL framework that can be applied to different domains, such as image classification (IMGC) and knowledge graph completion (KGC); (ii) a comprehensive evaluation with multiple zero-shot datasets from different domains, where our method often achieves better performance than the state-of-the-art models. In particular, on four representative ZSL baselines of IMGC, the ontology-based class semantics outperform the previous priors e.g., the word embeddings of classes by an average of 12.4 accuracy points in the standard ZSL across two example datasets (see Figure 4).
Non-Convex Structured Phase Retrieval
Jun 23, 2020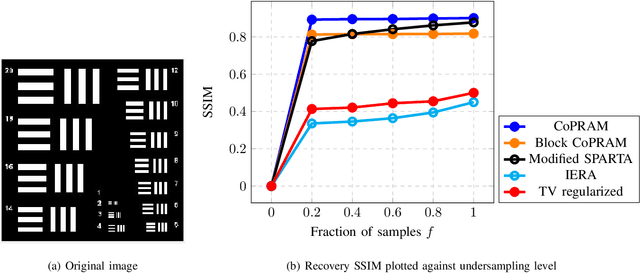
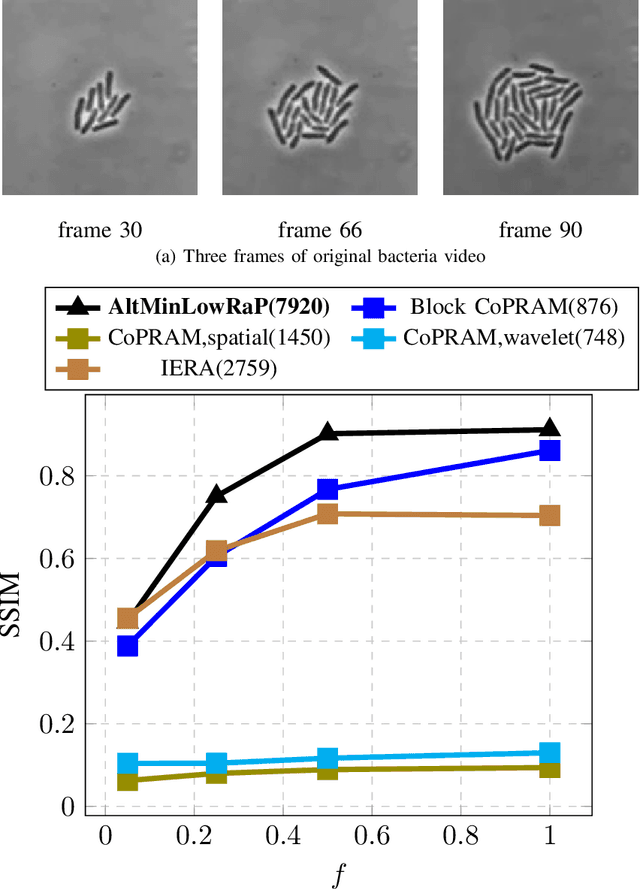
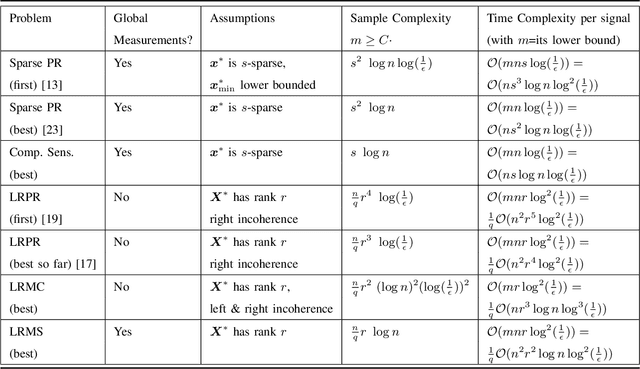
Phase retrieval (PR), also sometimes referred to as quadratic sensing, is a problem that occurs in numerous signal and image acquisition domains ranging from optics, X-ray crystallography, Fourier ptychography, sub-diffraction imaging, and astronomy. In each of these domains, the physics of the acquisition system dictates that only the magnitude (intensity) of certain linear projections of the signal or image can be measured. Without any assumptions on the unknown signal, accurate recovery necessarily requires an over-complete set of measurements. The only way to reduce the measurements/sample complexity is to place extra assumptions on the unknown signal/image. A simple and practically valid set of assumptions is obtained by exploiting the structure inherently present in many natural signals or sequences of signals. Two commonly used structural assumptions are (i) sparsity of a given signal/image or (ii) a low rank model on the matrix formed by a set, e.g., a time sequence, of signals/images. Both have been explored for solving the PR problem in a sample-efficient fashion. This article describes this work, with a focus on non-convex approaches that come with sample complexity guarantees under simple assumptions. We also briefly describe other different types of structural assumptions that have been used in recent literature.
Scalable image coding based on epitomes
Jun 28, 2016
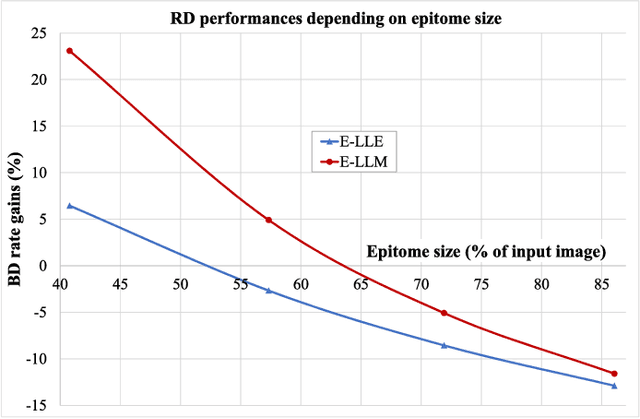
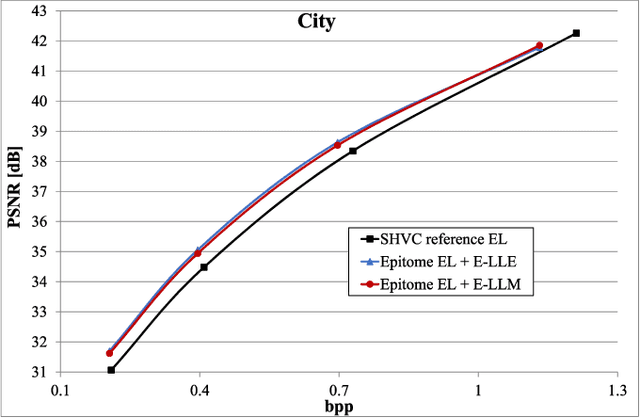
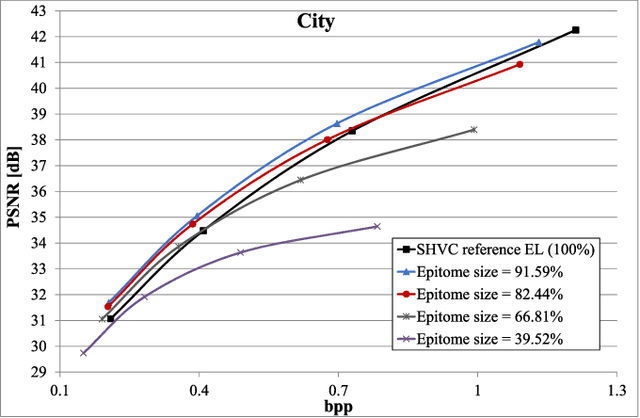
In this paper, we propose a novel scheme for scalable image coding based on the concept of epitome. An epitome can be seen as a factorized representation of an image. Focusing on spatial scalability, the enhancement layer of the proposed scheme contains only the epitome of the input image. The pixels of the enhancement layer not contained in the epitome are then restored using two approaches inspired from local learning-based super-resolution methods. In the first method, a locally linear embedding model is learned on base layer patches and then applied to the corresponding epitome patches to reconstruct the enhancement layer. The second approach learns linear mappings between pairs of co-located base layer and epitome patches. Experiments have shown that significant improvement of the rate-distortion performances can be achieved compared to an SHVC reference.