 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Paper and Code
Jun 04, 2020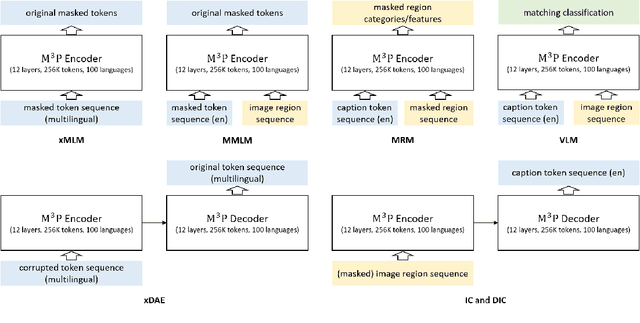


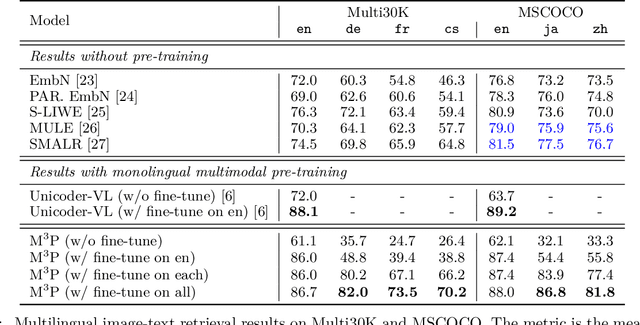
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine