 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCKNN: Cleansed k-Nearest Neighbor for Unsupervised Video Anomaly Detection
Aug 06, 2024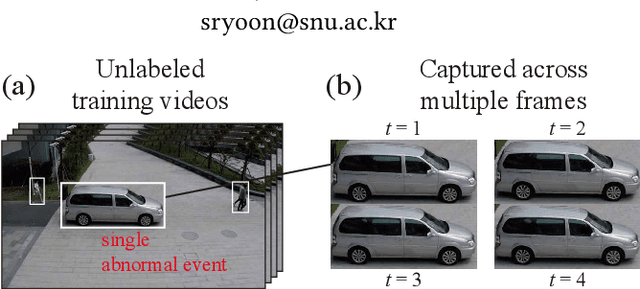
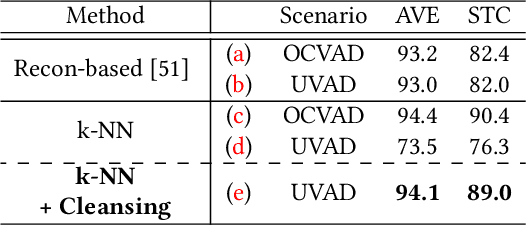
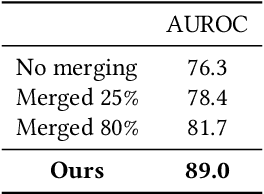
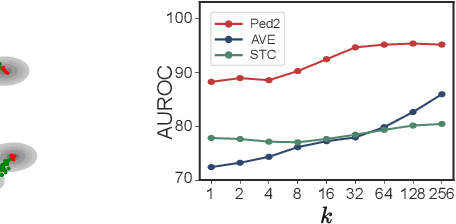
In this paper, we address the problem of unsupervised video anomaly detection (UVAD). The task aims to detect abnormal events in test video using unlabeled videos as training data. The presence of anomalies in the training data poses a significant challenge in this task, particularly because they form clusters in the feature space. We refer to this property as the "Anomaly Cluster" issue. The condensed nature of these anomalies makes it difficult to distinguish between normal and abnormal data in the training set. Consequently, training conventional anomaly detection techniques using an unlabeled dataset often leads to sub-optimal results. To tackle this difficulty, we propose a new method called Cleansed k-Nearest Neighbor (CKNN), which explicitly filters out the Anomaly Clusters by cleansing the training dataset. Following the k-nearest neighbor algorithm in the feature space provides powerful anomaly detection capability. Although the identified Anomaly Cluster issue presents a significant challenge to applying k-nearest neighbor in UVAD, our proposed cleansing scheme effectively addresses this problem. We evaluate the proposed method on various benchmark datasets and demonstrate that CKNN outperforms the previous state-of-the-art UVAD method by up to 8.5% (from 82.0 to 89.0) in terms of AUROC. Moreover, we emphasize that the performance of the proposed method is comparable to that of the state-of-the-art method trained using anomaly-free data.
Normality Addition via Normality Detection in Industrial Image Anomaly Detection Models
Jul 29, 2024



The task of image anomaly detection (IAD) aims to identify deviations from normality in image data. These anomalies are patterns that deviate significantly from what the IAD model has learned from the data during training. However, in real-world scenarios, the criteria for what constitutes normality often change, necessitating the reclassification of previously anomalous instances as normal. To address this challenge, we propose a new scenario termed "normality addition," involving the post-training adjustment of decision boundaries to incorporate new normalities. To address this challenge, we propose a method called Normality Addition via Normality Detection (NAND), leveraging a vision-language model. NAND performs normality detection which detect patterns related to the intended normality within images based on textual descriptions. We then modify the results of a pre-trained IAD model to implement this normality addition. Using the benchmark dataset in IAD, MVTec AD, we establish an evaluation protocol for the normality addition task and empirically demonstrate the effectiveness of the NAND method.
Self-Supervised Time-Series Anomaly Detection Using Learnable Data Augmentation
Jun 18, 2024Continuous efforts are being made to advance anomaly detection in various manufacturing processes to increase the productivity and safety of industrial sites. Deep learning replaced rule-based methods and recently emerged as a promising method for anomaly detection in diverse industries. However, in the real world, the scarcity of abnormal data and difficulties in obtaining labeled data create limitations in the training of detection models. In this study, we addressed these shortcomings by proposing a learnable data augmentation-based time-series anomaly detection (LATAD) technique that is trained in a self-supervised manner. LATAD extracts discriminative features from time-series data through contrastive learning. At the same time, learnable data augmentation produces challenging negative samples to enhance learning efficiency. We measured anomaly scores of the proposed technique based on latent feature similarities. As per the results, LATAD exhibited comparable or improved performance to the state-of-the-art anomaly detection assessments on several benchmark datasets and provided a gradient-based diagnosis technique to help identify root causes.
Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach
Jun 05, 2024



In this paper, we primarily address the issue of dialogue-form context query within the interactive text-to-image retrieval task. Our methodology, PlugIR, actively utilizes the general instruction-following capability of LLMs in two ways. First, by reformulating the dialogue-form context, we eliminate the necessity of fine-tuning a retrieval model on existing visual dialogue data, thereby enabling the use of any arbitrary black-box model. Second, we construct the LLM questioner to generate non-redundant questions about the attributes of the target image, based on the information of retrieval candidate images in the current context. This approach mitigates the issues of noisiness and redundancy in the generated questions. Beyond our methodology, we propose a novel evaluation metric, Best log Rank Integral (BRI), for a comprehensive assessment of the interactive retrieval system. PlugIR demonstrates superior performance compared to both zero-shot and fine-tuned baselines in various benchmarks. Additionally, the two methodologies comprising PlugIR can be flexibly applied together or separately in various situations. Our codes are available at https://github.com/Saehyung-Lee/PlugIR.
BBAM: Bounding Box Attribution Map for Weakly Supervised Semantic and Instance Segmentation
Mar 16, 2021
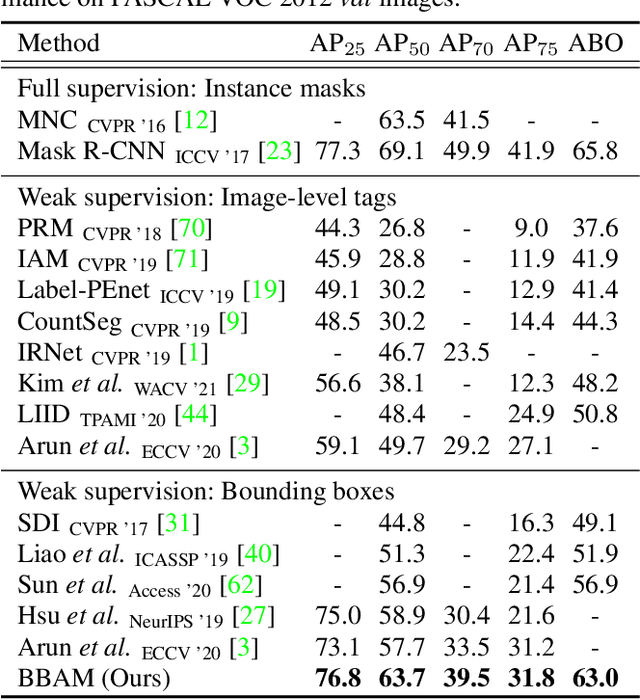
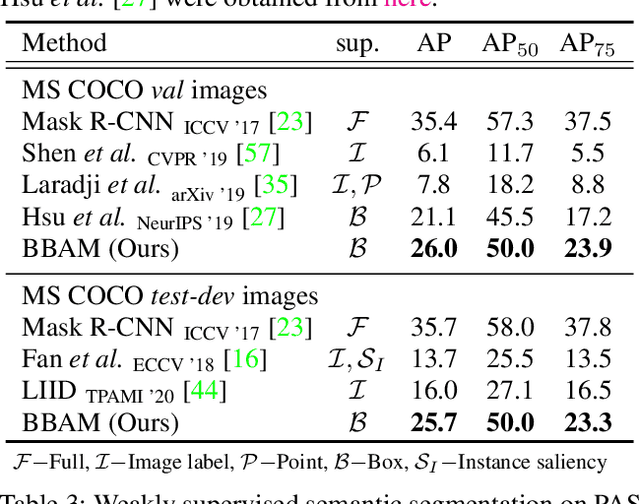

Weakly supervised segmentation methods using bounding box annotations focus on obtaining a pixel-level mask from each box containing an object. Existing methods typically depend on a class-agnostic mask generator, which operates on the low-level information intrinsic to an image. In this work, we utilize higher-level information from the behavior of a trained object detector, by seeking the smallest areas of the image from which the object detector produces almost the same result as it does from the whole image. These areas constitute a bounding-box attribution map (BBAM), which identifies the target object in its bounding box and thus serves as pseudo ground-truth for weakly supervised semantic and instance segmentation. This approach significantly outperforms recent comparable techniques on both the PASCAL VOC and MS COCO benchmarks in weakly supervised semantic and instance segmentation. In addition, we provide a detailed analysis of our method, offering deeper insight into the behavior of the BBAM.
Removing Undesirable Feature Contributions Using Out-of-Distribution Data
Jan 17, 2021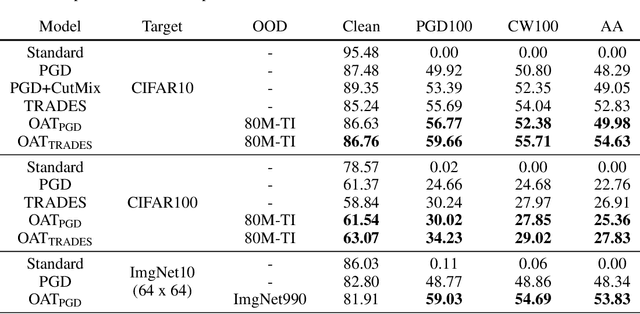
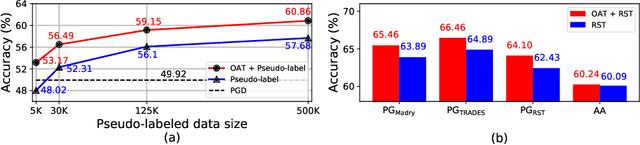

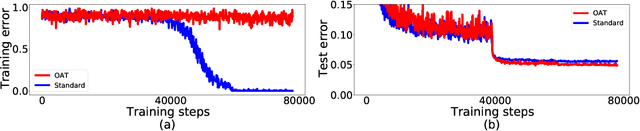
Several data augmentation methods deploy unlabeled-in-distribution (UID) data to bridge the gap between the training and inference of neural networks. However, these methods have clear limitations in terms of availability of UID data and dependence of algorithms on pseudo-labels. Herein, we propose a data augmentation method to improve generalization in both adversarial and standard learning by using out-of-distribution (OOD) data that are devoid of the abovementioned issues. We show how to improve generalization theoretically using OOD data in each learning scenario and complement our theoretical analysis with experiments on CIFAR-10, CIFAR-100, and a subset of ImageNet. The results indicate that undesirable features are shared even among image data that seem to have little correlation from a human point of view. We also present the advantages of the proposed method through comparison with other data augmentation methods, which can be used in the absence of UID data. Furthermore, we demonstrate that the proposed method can further improve the existing state-of-the-art adversarial training.
Interpretation of NLP models through input marginalization
Oct 27, 2020
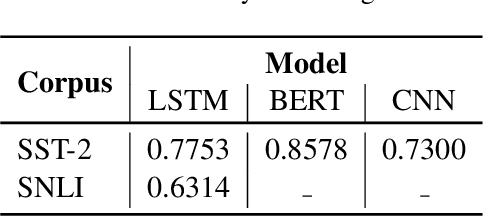

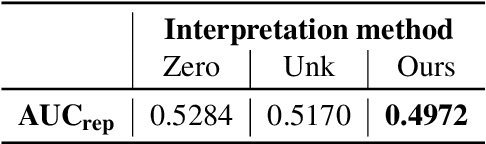
To demystify the "black box" property of deep neural networks for natural language processing (NLP), several methods have been proposed to interpret their predictions by measuring the change in prediction probability after erasing each token of an input. Since existing methods replace each token with a predefined value (i.e., zero), the resulting sentence lies out of the training data distribution, yielding misleading interpretations. In this study, we raise the out-of-distribution problem induced by the existing interpretation methods and present a remedy; we propose to marginalize each token out. We interpret various NLP models trained for sentiment analysis and natural language inference using the proposed method.
Information-Theoretic Visual Explanation for Black-Box Classifiers
Sep 23, 2020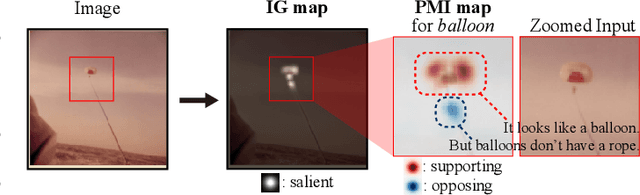
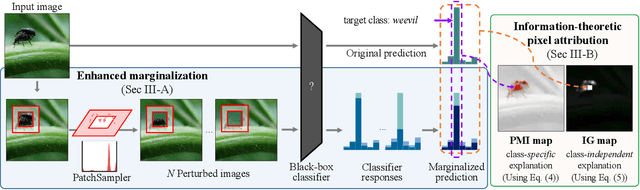
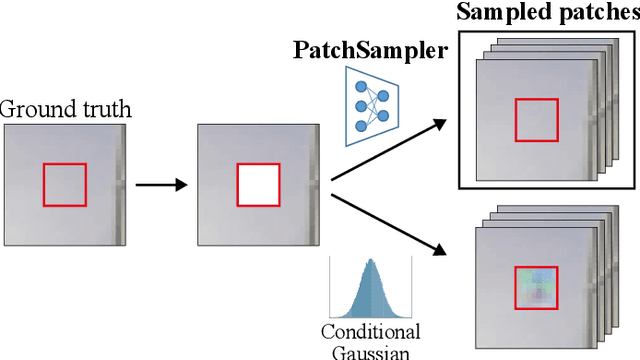
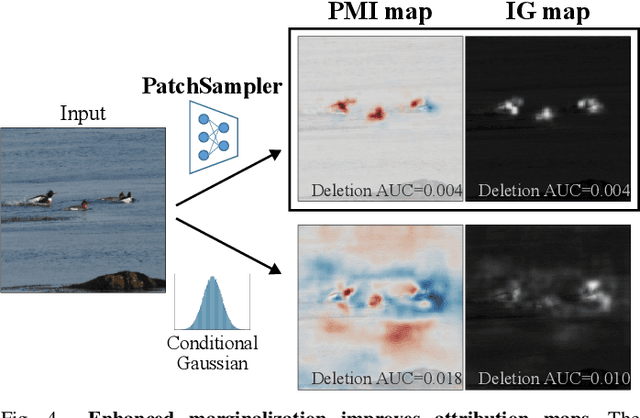
In this work, we attempt to explain the prediction of any black-box classifier from an information-theoretic perspective. For this purpose, we propose two attribution maps: an information gain (IG) map and a point-wise mutual information (PMI) map. IG map provides a class-independent answer to "How informative is each pixel?", and PMI map offers a class-specific explanation by answering "How much does each pixel support a specific class?" In this manner, we propose (i) a theory-backed attribution method. The attribution (ii) provides both supporting and opposing explanations for each class and (iii) pinpoints most decisive parts in the image, not just the relevant objects. In addition, the method (iv) offers a complementary class-independent explanation. Lastly, the algorithmic enhancement in our method (v) improves faithfulness of the explanation in terms of a quantitative evaluation metric. We showed the five strengths of our method through various experiments on the ImageNet dataset. The code of the proposed method is available online.
iCaps: An Interpretable Classifier via Disentangled Capsule Networks
Aug 20, 2020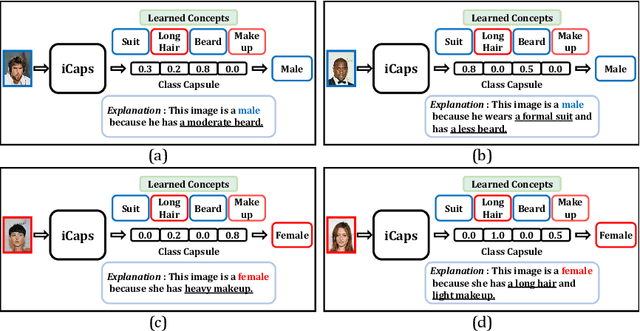
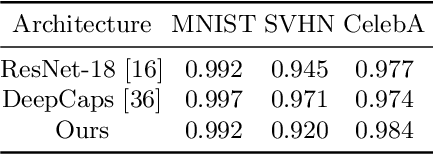
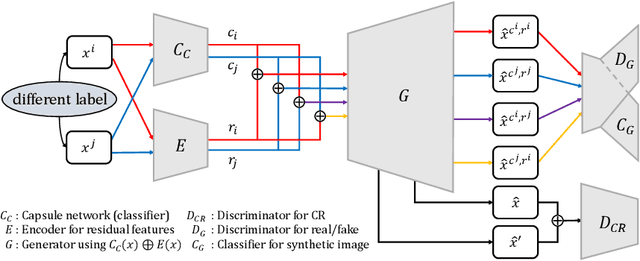
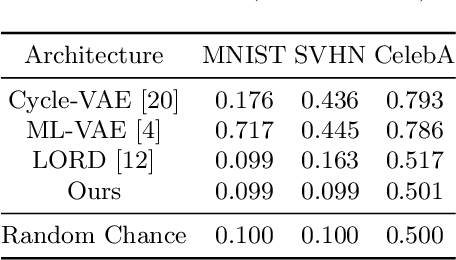
We propose an interpretable Capsule Network, iCaps, for image classification. A capsule is a group of neurons nested inside each layer, and the one in the last layer is called a class capsule, which is a vector whose norm indicates a predicted probability for the class. Using the class capsule, existing Capsule Networks already provide some level of interpretability. However, there are two limitations which degrade its interpretability: 1) the class capsule also includes classification-irrelevant information, and 2) entities represented by the class capsule overlap. In this work, we address these two limitations using a novel class-supervised disentanglement algorithm and an additional regularizer, respectively. Through quantitative and qualitative evaluations on three datasets, we demonstrate that the resulting classifier, iCaps, provides a prediction along with clear rationales behind it with no performance degradation.
Patch SVDD: Patch-level SVDD for Anomaly Detection and Segmentation
Jul 13, 2020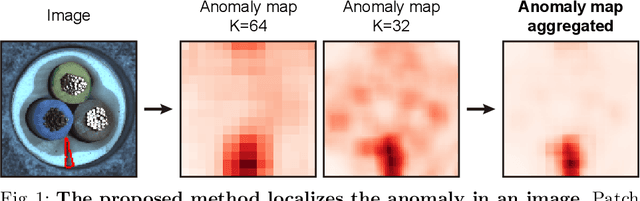
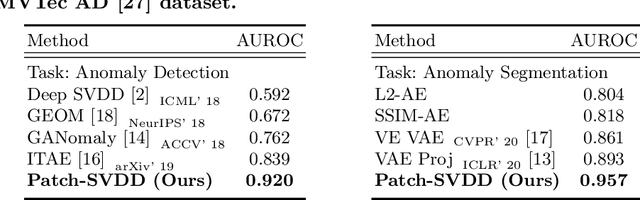
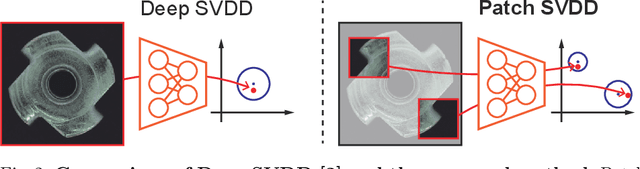
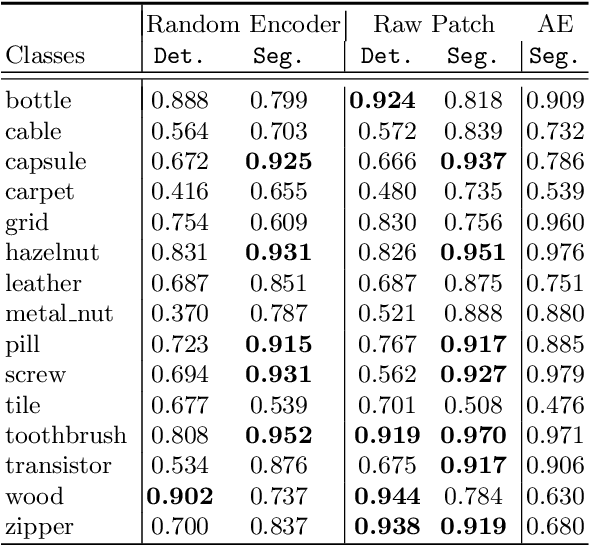
In this paper, we address the problem of image anomaly detection and segmentation. Anomaly detection involves making a binary decision as to whether an input image contains an anomaly, and anomaly segmentation aims to locate the anomaly on the pixel level. Support vector data description (SVDD) is a long-standing algorithm used for an anomaly detection, and we extend its deep learning variant to the patch-based method using self-supervised learning. This extension enables anomaly segmentation and improves detection performance. As a result, anomaly detection and segmentation performances measured in AUROC on MVTec AD dataset increased by 9.8% and 7.0%, respectively, compared to the previous state-of-the-art methods. Our results indicate the efficacy of the proposed method and its potential for industrial application. Detailed analysis of the proposed method offers insights regarding its behavior, and the code is available online.