 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
All-Day Object Tracking for Unmanned Aerial Vehicle
Jan 24, 2021
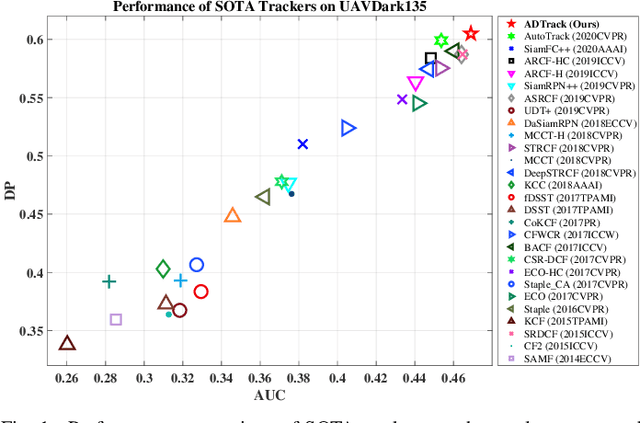
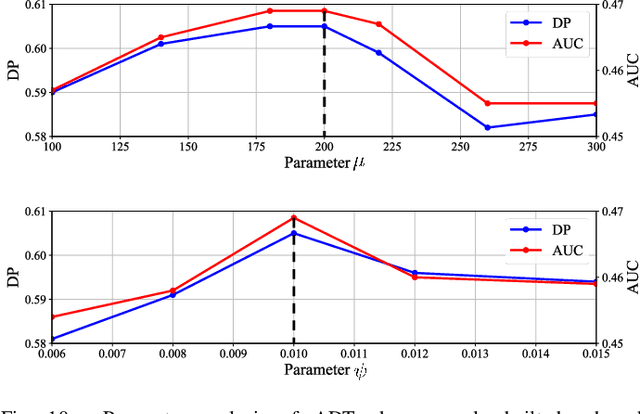

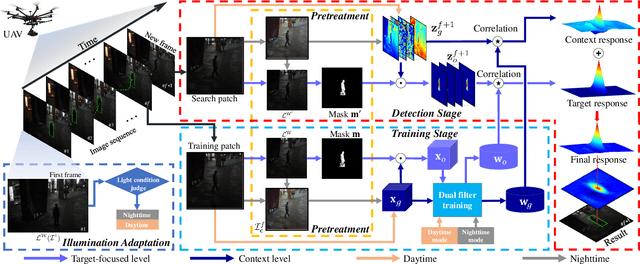
Visual object tracking, which is representing a major interest in image processing field, has facilitated numerous real world applications. Among them, equipping unmanned aerial vehicle (UAV) with real time robust visual trackers for all day aerial maneuver, is currently attracting incremental attention and has remarkably broadened the scope of applications of object tracking. However, prior tracking methods have merely focused on robust tracking in the well-illuminated scenes, while ignoring trackers' capabilities to be deployed in the dark. In darkness, the conditions can be more complex and harsh, easily posing inferior robust tracking or even tracking failure. To this end, this work proposed a novel discriminative correlation filter based tracker with illumination adaptive and anti dark capability, namely ADTrack. ADTrack firstly exploits image illuminance information to enable adaptability of the model to the given light condition. Then, by virtue of an efficient and effective image enhancer, ADTrack carries out image pretreatment, where a target aware mask is generated. Benefiting from the mask, ADTrack aims to solve a dual regression problem where dual filters, i.e., the context filter and target focused filter, are trained with mutual constraint. Thus ADTrack is able to maintain continuously favorable performance in all-day conditions. Besides, this work also constructed one UAV nighttime tracking benchmark UAVDark135, comprising of more than 125k manually annotated frames, which is also very first UAV nighttime tracking benchmark. Exhaustive experiments are extended on authoritative daytime benchmarks, i.e., UAV123 10fps, DTB70, and the newly built dark benchmark UAVDark135, which have validated the superiority of ADTrack in both bright and dark conditions on a single CPU.
Scaling Neural Tangent Kernels via Sketching and Random Features
Jun 15, 2021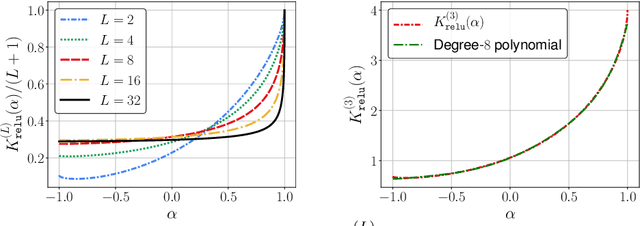

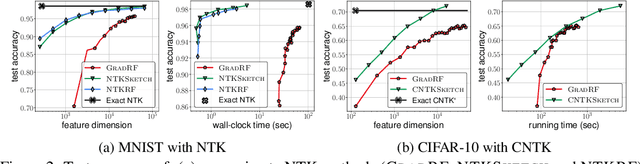
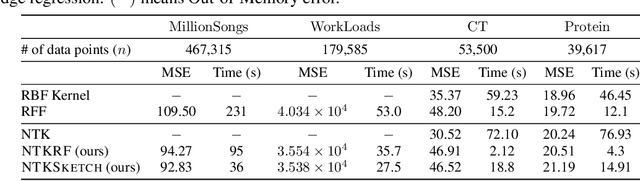
The Neural Tangent Kernel (NTK) characterizes the behavior of infinitely-wide neural networks trained under least squares loss by gradient descent. Recent works also report that NTK regression can outperform finitely-wide neural networks trained on small-scale datasets. However, the computational complexity of kernel methods has limited its use in large-scale learning tasks. To accelerate learning with NTK, we design a near input-sparsity time approximation algorithm for NTK, by sketching the polynomial expansions of arc-cosine kernels: our sketch for the convolutional counterpart of NTK (CNTK) can transform any image using a linear runtime in the number of pixels. Furthermore, we prove a spectral approximation guarantee for the NTK matrix, by combining random features (based on leverage score sampling) of the arc-cosine kernels with a sketching algorithm. We benchmark our methods on various large-scale regression and classification tasks and show that a linear regressor trained on our CNTK features matches the accuracy of exact CNTK on CIFAR-10 dataset while achieving 150x speedup.
FetalNet: Multi-task deep learning framework for fetal ultrasound biometric measurements
Jul 14, 2021



In this paper, we propose an end-to-end multi-task neural network called FetalNet with an attention mechanism and stacked module for spatio-temporal fetal ultrasound scan video analysis. Fetal biometric measurement is a standard examination during pregnancy used for the fetus growth monitoring and estimation of gestational age and fetal weight. The main goal in fetal ultrasound scan video analysis is to find proper standard planes to measure the fetal head, abdomen and femur. Due to natural high speckle noise and shadows in ultrasound data, medical expertise and sonographic experience are required to find the appropriate acquisition plane and perform accurate measurements of the fetus. In addition, existing computer-aided methods for fetal US biometric measurement address only one single image frame without considering temporal features. To address these shortcomings, we propose an end-to-end multi-task neural network for spatio-temporal ultrasound scan video analysis to simultaneously localize, classify and measure the fetal body parts. We propose a new encoder-decoder segmentation architecture that incorporates a classification branch. Additionally, we employ an attention mechanism with a stacked module to learn salient maps to suppress irrelevant US regions and efficient scan plane localization. We trained on the fetal ultrasound video comes from routine examinations of 700 different patients. Our method called FetalNet outperforms existing state-of-the-art methods in both classification and segmentation in fetal ultrasound video recordings.
Keep CALM and Improve Visual Feature Attribution
Jun 15, 2021
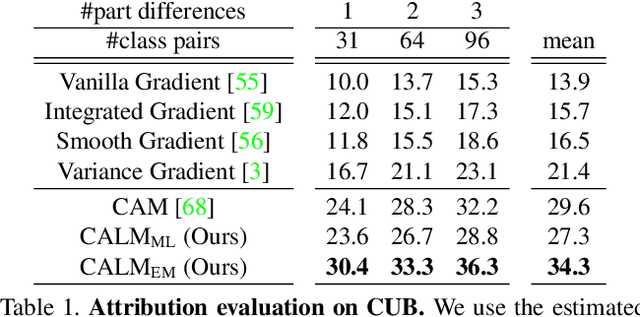
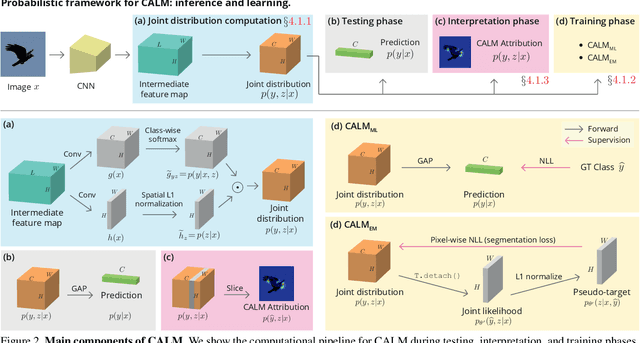

The class activation mapping, or CAM, has been the cornerstone of feature attribution methods for multiple vision tasks. Its simplicity and effectiveness have led to wide applications in the explanation of visual predictions and weakly-supervised localization tasks. However, CAM has its own shortcomings. The computation of attribution maps relies on ad-hoc calibration steps that are not part of the training computational graph, making it difficult for us to understand the real meaning of the attribution values. In this paper, we improve CAM by explicitly incorporating a latent variable encoding the location of the cue for recognition in the formulation, thereby subsuming the attribution map into the training computational graph. The resulting model, class activation latent mapping, or CALM, is trained with the expectation-maximization algorithm. Our experiments show that CALM identifies discriminative attributes for image classifiers more accurately than CAM and other visual attribution baselines. CALM also shows performance improvements over prior arts on the weakly-supervised object localization benchmarks. Our code is available at https://github.com/naver-ai/calm.
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
Jun 05, 2021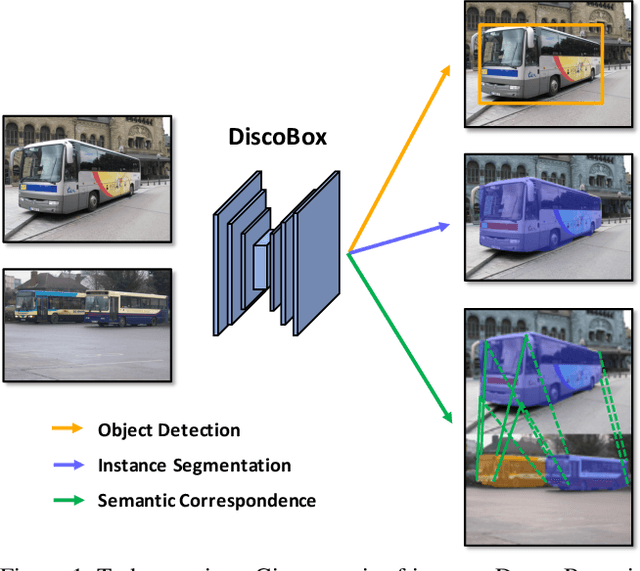
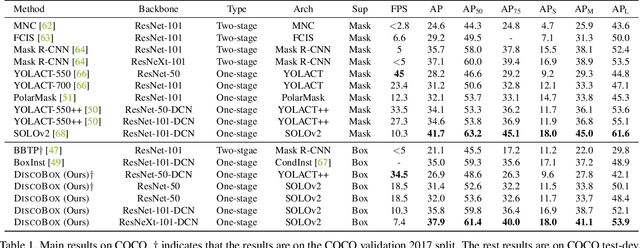
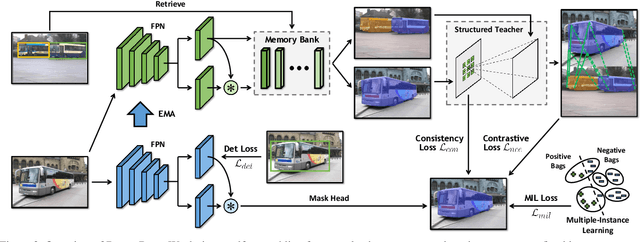
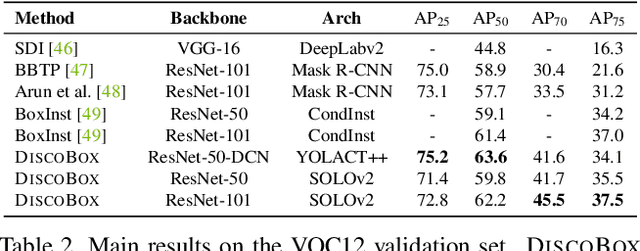
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision. The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes. Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning. We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods. We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.
Learning to Aggregate and Personalize 3D Face from In-the-Wild Photo Collection
Jun 15, 2021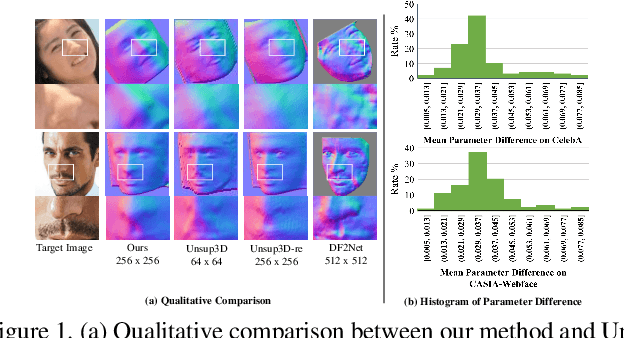
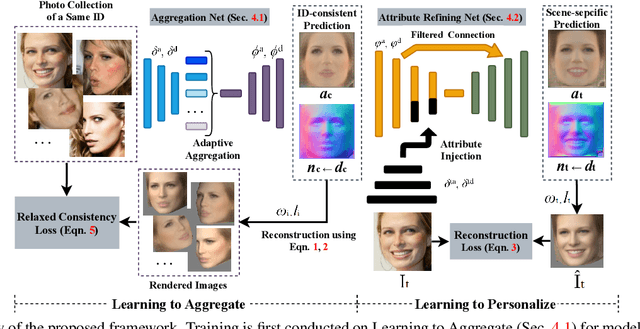
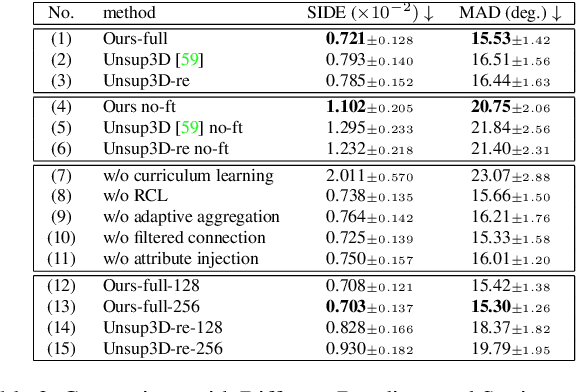
Non-parametric face modeling aims to reconstruct 3D face only from images without shape assumptions. While plausible facial details are predicted, the models tend to over-depend on local color appearance and suffer from ambiguous noise. To address such problem, this paper presents a novel Learning to Aggregate and Personalize (LAP) framework for unsupervised robust 3D face modeling. Instead of using controlled environment, the proposed method implicitly disentangles ID-consistent and scene-specific face from unconstrained photo set. Specifically, to learn ID-consistent face, LAP adaptively aggregates intrinsic face factors of an identity based on a novel curriculum learning approach with relaxed consistency loss. To adapt the face for a personalized scene, we propose a novel attribute-refining network to modify ID-consistent face with target attribute and details. Based on the proposed method, we make unsupervised 3D face modeling benefit from meaningful image facial structure and possibly higher resolutions. Extensive experiments on benchmarks show LAP recovers superior or competitive face shape and texture, compared with state-of-the-art (SOTA) methods with or without prior and supervision.
Multi-frame Collaboration for Effective Endoscopic Video Polyp Detection via Spatial-Temporal Feature Transformation
Jul 08, 2021
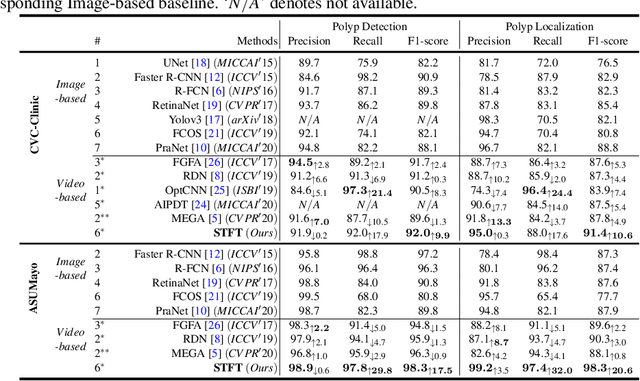
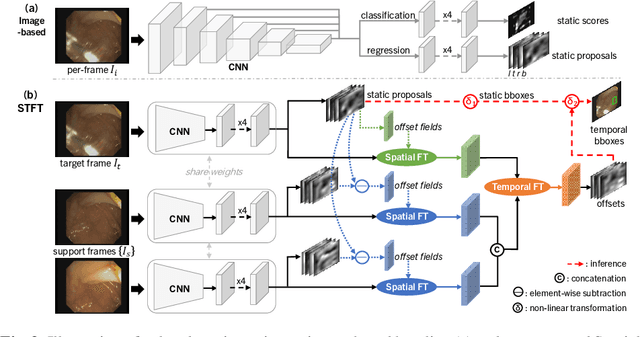

Precise localization of polyp is crucial for early cancer screening in gastrointestinal endoscopy. Videos given by endoscopy bring both richer contextual information as well as more challenges than still images. The camera-moving situation, instead of the common camera-fixed-object-moving one, leads to significant background variation between frames. Severe internal artifacts (e.g. water flow in the human body, specular reflection by tissues) can make the quality of adjacent frames vary considerately. These factors hinder a video-based model to effectively aggregate features from neighborhood frames and give better predictions. In this paper, we present Spatial-Temporal Feature Transformation (STFT), a multi-frame collaborative framework to address these issues. Spatially, STFT mitigates inter-frame variations in the camera-moving situation with feature alignment by proposal-guided deformable convolutions. Temporally, STFT proposes a channel-aware attention module to simultaneously estimate the quality and correlation of adjacent frames for adaptive feature aggregation. Empirical studies and superior results demonstrate the effectiveness and stability of our method. For example, STFT improves the still image baseline FCOS by 10.6% and 20.6% on the comprehensive F1-score of the polyp localization task in CVC-Clinic and ASUMayo datasets, respectively, and outperforms the state-of-the-art video-based method by 3.6% and 8.0%, respectively. Code is available at \url{https://github.com/lingyunwu14/STFT}.
Image Specificity
Apr 16, 2015
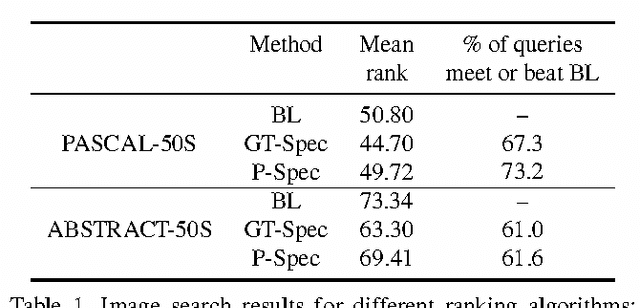

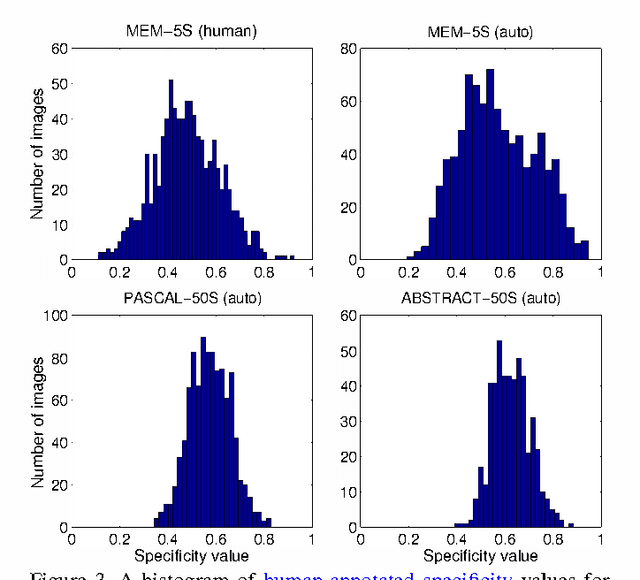
For some images, descriptions written by multiple people are consistent with each other. But for other images, descriptions across people vary considerably. In other words, some images are specific $-$ they elicit consistent descriptions from different people $-$ while other images are ambiguous. Applications involving images and text can benefit from an understanding of which images are specific and which ones are ambiguous. For instance, consider text-based image retrieval. If a query description is moderately similar to the caption (or reference description) of an ambiguous image, that query may be considered a decent match to the image. But if the image is very specific, a moderate similarity between the query and the reference description may not be sufficient to retrieve the image. In this paper, we introduce the notion of image specificity. We present two mechanisms to measure specificity given multiple descriptions of an image: an automated measure and a measure that relies on human judgement. We analyze image specificity with respect to image content and properties to better understand what makes an image specific. We then train models to automatically predict the specificity of an image from image features alone without requiring textual descriptions of the image. Finally, we show that modeling image specificity leads to improvements in a text-based image retrieval application.
Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting
Mar 25, 2021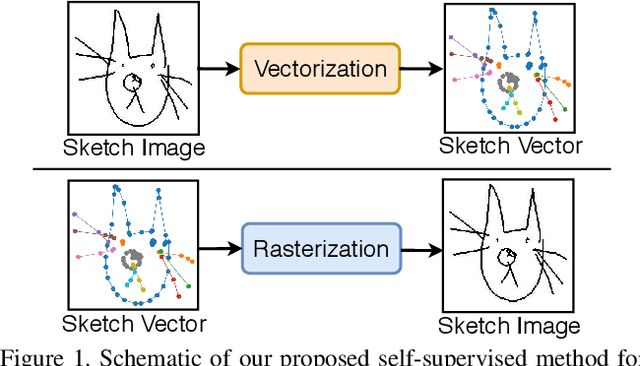
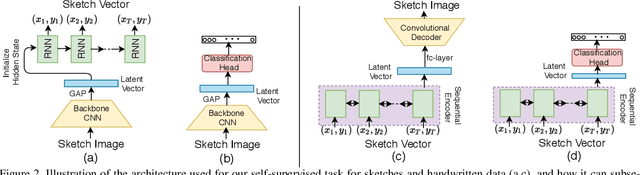
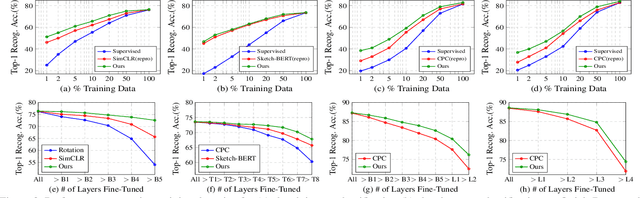
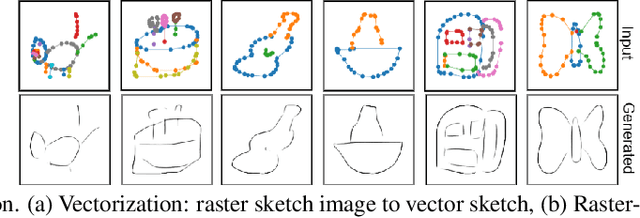
Self-supervised learning has gained prominence due to its efficacy at learning powerful representations from unlabelled data that achieve excellent performance on many challenging downstream tasks. However supervision-free pre-text tasks are challenging to design and usually modality specific. Although there is a rich literature of self-supervised methods for either spatial (such as images) or temporal data (sound or text) modalities, a common pre-text task that benefits both modalities is largely missing. In this paper, we are interested in defining a self-supervised pre-text task for sketches and handwriting data. This data is uniquely characterised by its existence in dual modalities of rasterized images and vector coordinate sequences. We address and exploit this dual representation by proposing two novel cross-modal translation pre-text tasks for self-supervised feature learning: Vectorization and Rasterization. Vectorization learns to map image space to vector coordinates and rasterization maps vector coordinates to image space. We show that the our learned encoder modules benefit both raster-based and vector-based downstream approaches to analysing hand-drawn data. Empirical evidence shows that our novel pre-text tasks surpass existing single and multi-modal self-supervision methods.
MCTSteg: A Monte Carlo Tree Search-based Reinforcement Learning Framework for Universal Non-additive Steganography
Mar 25, 2021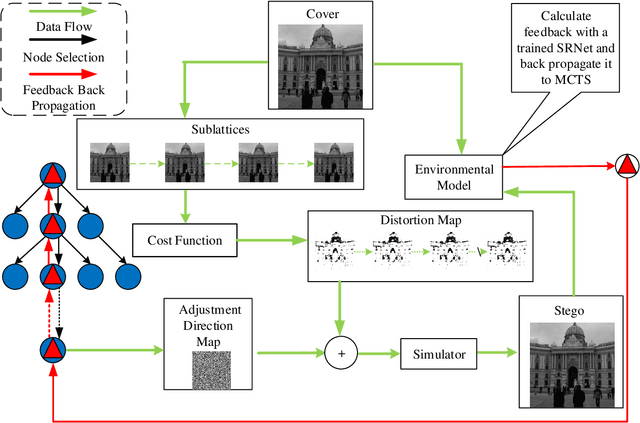
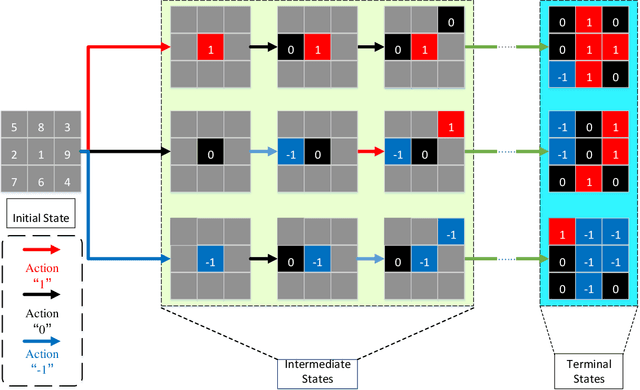
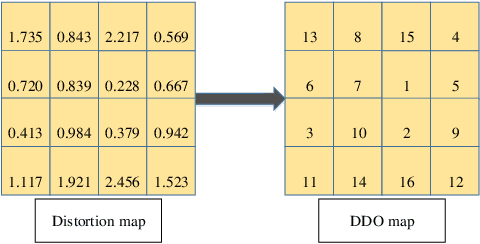
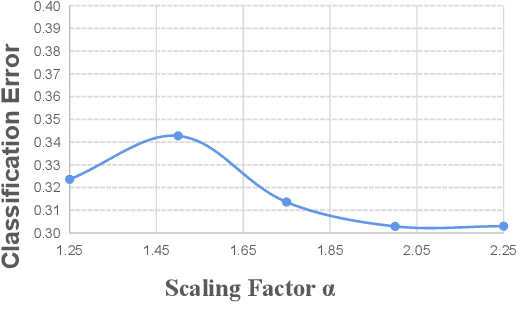
Recent research has shown that non-additive image steganographic frameworks effectively improve security performance through adjusting distortion distribution. However, as far as we know, all of the existing non-additive proposals are based on handcrafted policies, and can only be applied to a specific image domain, which heavily prevent non-additive steganography from releasing its full potentiality. In this paper, we propose an automatic non-additive steganographic distortion learning framework called MCTSteg to remove the above restrictions. Guided by the reinforcement learning paradigm, we combine Monte Carlo Tree Search (MCTS) and steganalyzer-based environmental model to build MCTSteg. MCTS makes sequential decisions to adjust distortion distribution without human intervention. Our proposed environmental model is used to obtain feedbacks from each decision. Due to its self-learning characteristic and domain-independent reward function, MCTSteg has become the first reported universal non-additive steganographic framework which can work in both spatial and JPEG domains. Extensive experimental results show that MCTSteg can effectively withstand the detection of both hand-crafted feature-based and deep-learning-based steganalyzers. In both spatial and JPEG domains, the security performance of MCTSteg steadily outperforms the state of the art by a clear margin under different scenarios.