 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Algebraic Tensors: Provably-optimal Equivariant Learning and Physical Symmetry Discovery
May 19, 2026We introduce the $\star_G$ tensor algebra, in which any finite group $G$ defines the multiplication rule, making equivariance an intrinsic algebraic property rather than an architectural constraint. The framework rests on three machine-verified theoretical pillars: (i)~an Eckart-Young optimality guarantee for the $\star_G$-SVD: the first such result for symmetry-preserving tensor approximation, exact and polynomial-time; (ii)~a Kronecker factorization that composes multiple symmetries by replacing $F_G$ with $F_{G_1} \otimes F_{G_2}$ with no architectural redesign; and (iii)~a 600-line Lean~4 formalization of the $\star_G$ algebra. The framework provides capabilities that equivariant neural networks (ENNs) structurally cannot: a closed-form per-irreducible-representation decomposition of every prediction, and data-driven discovery of the symmetry group that best fits a dataset. As a non-trivial empirical demonstration, decomposing QM9 molecular geometry over the chiral octahedral subgroup of SO(3) recovers the Wigner--Eckart selection rules of angular momentum from data alone, with no quantum mechanical input: scalar properties are A$_1$-dominated, dipole components are T$_1$-dominated, the isotropic polarizability is uniquely insensitive to $l\!=\!1$ as the rank-2-trace decomposition $l\!=\!0 \oplus l\!=\!2$ requires, and the T$_1$/A$_1$ predictive-power ratio separates vector observables from scalar observables by a factor of five. On full QM9 (130{,}831 molecules), $\star_G$-SVD with ridge regression provides closed form predictions at $\sim50-90\times$ fewer parameters than parameter-matched MLPs. Algebraic equivariance thus complements architectural equivariance not as a faster-better-cheaper alternative but as a different mathematical affordance: provably-optimal symmetry-preserving compression, per-irrep interpretability, and data-driven physical discovery.
Higher Order Reduced Rank Regression
Mar 09, 2025


Reduced Rank Regression (RRR) is a widely used method for multi-response regression. However, RRR assumes a linear relationship between features and responses. While linear models are useful and often provide a good approximation, many real-world problems involve more complex relationships that cannot be adequately captured by simple linear interactions. One way to model such relationships is via multilinear transformations. This paper introduces Higher Order Reduced Rank Regression (HORRR), an extension of RRR that leverages multi-linear transformations, and as such is capable of capturing nonlinear interactions in multi-response regression. HORRR employs tensor representations for the coefficients and a Tucker decomposition to impose multilinear rank constraints as regularization akin to the rank constraints in RRR. Encoding these constraints as a manifold allows us to use Riemannian optimization to solve this HORRR problems. We theoretically and empirically analyze the use of Riemannian optimization for solving HORRR problems.
Multivariate trace estimation using quantum state space linear algebra
May 02, 2024In this paper, we present a quantum algorithm for approximating multivariate traces, i.e. the traces of matrix products. Our research is motivated by the extensive utility of multivariate traces in elucidating spectral characteristics of matrices, as well as by recent advancements in leveraging quantum computing for faster numerical linear algebra. Central to our approach is a direct translation of a multivariate trace formula into a quantum circuit, achieved through a sequence of low-level circuit construction operations. To facilitate this translation, we introduce \emph{quantum Matrix States Linear Algebra} (qMSLA), a framework tailored for the efficient generation of state preparation circuits via primitive matrix algebra operations. Our algorithm relies on sets of state preparation circuits for input matrices as its primary inputs and yields two state preparation circuits encoding the multivariate trace as output. These circuits are constructed utilizing qMSLA operations, which enact the aforementioned multivariate trace formula. We emphasize that our algorithm's inputs consist solely of state preparation circuits, eschewing harder to synthesize constructs such as Block Encodings. Furthermore, our approach operates independently of the availability of specialized hardware like QRAM, underscoring its versatility and practicality.
On the Role of Initialization on the Implicit Bias in Deep Linear Networks
Feb 04, 2024Despite Deep Learning's (DL) empirical success, our theoretical understanding of its efficacy remains limited. One notable paradox is that while conventional wisdom discourages perfect data fitting, deep neural networks are designed to do just that, yet they generalize effectively. This study focuses on exploring this phenomenon attributed to the implicit bias at play. Various sources of implicit bias have been identified, such as step size, weight initialization, optimization algorithm, and number of parameters. In this work, we focus on investigating the implicit bias originating from weight initialization. To this end, we examine the problem of solving underdetermined linear systems in various contexts, scrutinizing the impact of initialization on the implicit regularization when using deep networks to solve such systems. Our findings elucidate the role of initialization in the optimization and generalization paradoxes, contributing to a more comprehensive understanding of DL's performance characteristics.
Manifold Free Riemannian Optimization
Sep 07, 2022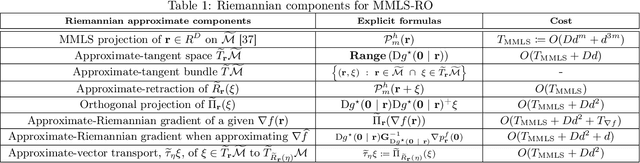
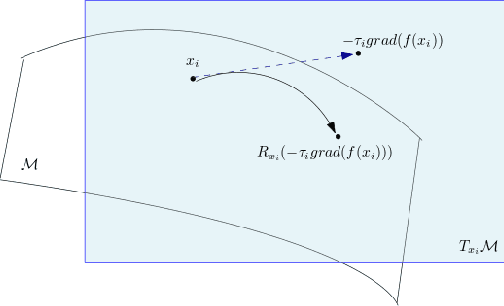
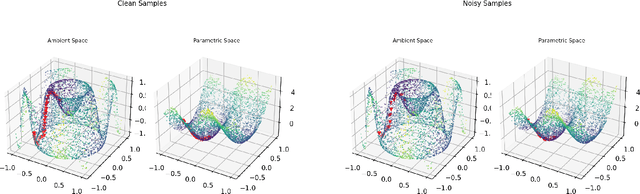
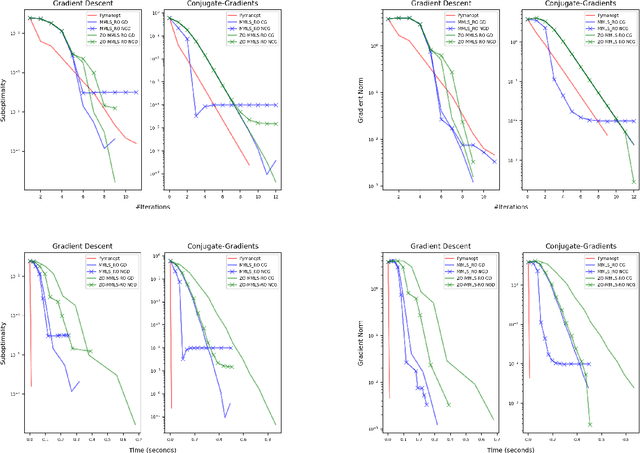
Riemannian optimization is a principled framework for solving optimization problems where the desired optimum is constrained to a smooth manifold $\mathcal{M}$. Algorithms designed in this framework usually require some geometrical description of the manifold, which typically includes tangent spaces, retractions, and gradients of the cost function. However, in many cases, only a subset (or none at all) of these elements can be accessed due to lack of information or intractability. In this paper, we propose a novel approach that can perform approximate Riemannian optimization in such cases, where the constraining manifold is a submanifold of $\R^{D}$. At the bare minimum, our method requires only a noiseless sample set of the cost function $(\x_{i}, y_{i})\in {\mathcal{M}} \times \mathbb{R}$ and the intrinsic dimension of the manifold $\mathcal{M}$. Using the samples, and utilizing the Manifold-MLS framework (Sober and Levin 2020), we construct approximations of the missing components entertaining provable guarantees and analyze their computational costs. In case some of the components are given analytically (e.g., if the cost function and its gradient are given explicitly, or if the tangent spaces can be computed), the algorithm can be easily adapted to use the accurate expressions instead of the approximations. We analyze the global convergence of Riemannian gradient-based methods using our approach, and we demonstrate empirically the strength of this method, together with a conjugate-gradients type method based upon similar principles.
Near Optimal Reconstruction of Spherical Harmonic Expansions
Feb 25, 2022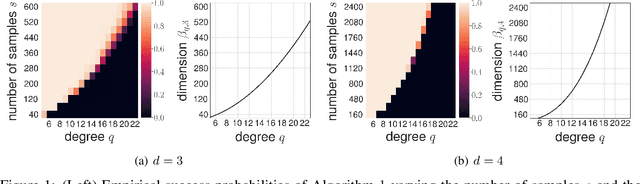
We propose an algorithm for robust recovery of the spherical harmonic expansion of functions defined on the d-dimensional unit sphere $\mathbb{S}^{d-1}$ using a near-optimal number of function evaluations. We show that for any $f \in L^2(\mathbb{S}^{d-1})$, the number of evaluations of $f$ needed to recover its degree-$q$ spherical harmonic expansion equals the dimension of the space of spherical harmonics of degree at most $q$ up to a logarithmic factor. Moreover, we develop a simple yet efficient algorithm to recover degree-$q$ expansion of $f$ by only evaluating the function on uniformly sampled points on $\mathbb{S}^{d-1}$. Our algorithm is based on the connections between spherical harmonics and Gegenbauer polynomials and leverage score sampling methods. Unlike the prior results on fast spherical harmonic transform, our proposed algorithm works efficiently using a nearly optimal number of samples in any dimension d. We further illustrate the empirical performance of our algorithm on numerical examples.
PCENet: High Dimensional Surrogate Modeling for Learning Uncertainty
Feb 11, 2022
Learning data representations under uncertainty is an important task that emerges in numerous machine learning applications. However, uncertainty quantification (UQ) techniques are computationally intensive and become prohibitively expensive for high-dimensional data. In this paper, we present a novel surrogate model for representation learning and uncertainty quantification, which aims to deal with data of moderate to high dimensions. The proposed model combines a neural network approach for dimensionality reduction of the (potentially high-dimensional) data, with a surrogate model method for learning the data distribution. We first employ a variational autoencoder (VAE) to learn a low-dimensional representation of the data distribution. We then propose to harness polynomial chaos expansion (PCE) formulation to map this distribution to the output target. The coefficients of PCE are learned from the distribution representation of the training data using a maximum mean discrepancy (MMD) approach. Our model enables us to (a) learn a representation of the data, (b) estimate uncertainty in the high-dimensional data system, and (c) match high order moments of the output distribution; without any prior statistical assumptions on the data. Numerical experimental results are presented to illustrate the performance of the proposed method.
Random Gegenbauer Features for Scalable Kernel Methods
Feb 07, 2022
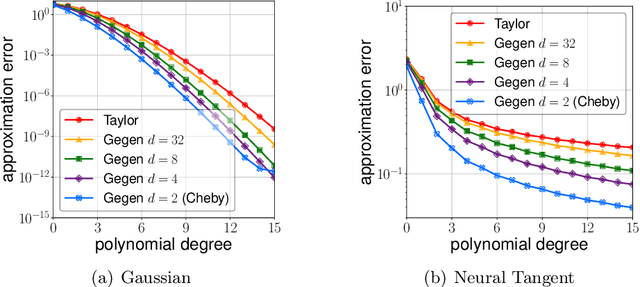
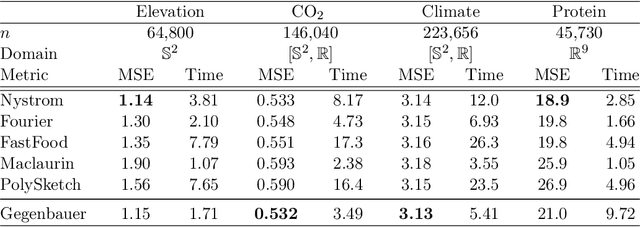
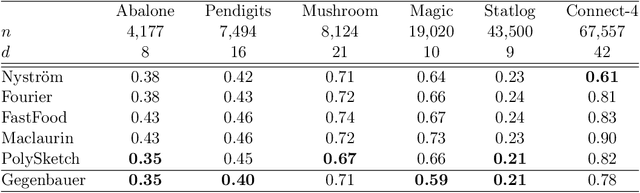
We propose efficient random features for approximating a new and rich class of kernel functions that we refer to as Generalized Zonal Kernels (GZK). Our proposed GZK family, generalizes the zonal kernels (i.e., dot-product kernels on the unit sphere) by introducing radial factors in their Gegenbauer series expansion, and includes a wide range of ubiquitous kernel functions such as the entirety of dot-product kernels as well as the Gaussian and the recently introduced Neural Tangent kernels. Interestingly, by exploiting the reproducing property of the Gegenbauer polynomials, we can construct efficient random features for the GZK family based on randomly oriented Gegenbauer kernels. We prove subspace embedding guarantees for our Gegenbauer features which ensures that our features can be used for approximately solving learning problems such as kernel k-means clustering, kernel ridge regression, etc. Empirical results show that our proposed features outperform recent kernel approximation methods.
Low-Rank Updates of Matrix Square Roots
Jan 31, 2022Models in which the covariance matrix has the structure of a sparse matrix plus a low rank perturbation are ubiquitous in machine learning applications. It is often desirable for learning algorithms to take advantage of such structures, avoiding costly matrix computations that often require cubic time and quadratic storage. This is often accomplished by performing operations that maintain such structures, e.g. matrix inversion via the Sherman-Morrison-Woodbury formula. In this paper we consider the matrix square root and inverse square root operations. Given a low rank perturbation to a matrix, we argue that a low-rank approximate correction to the (inverse) square root exists. We do so by establishing a geometric decay bound on the true correction's eigenvalues. We then proceed to frame the correction has the solution of an algebraic Ricatti equation, and discuss how a low-rank solution to that equation can be computed. We analyze the approximation error incurred when approximately solving the algebraic Ricatti equation, providing spectral and Frobenius norm forward and backward error bounds. Finally, we describe several applications of our algorithms, and demonstrate their utility in numerical experiments.
Dimensionality Reduction of Longitudinal 'Omics Data using Modern Tensor Factorization
Nov 28, 2021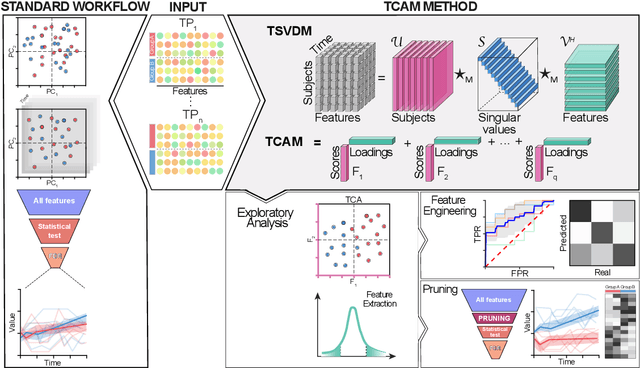
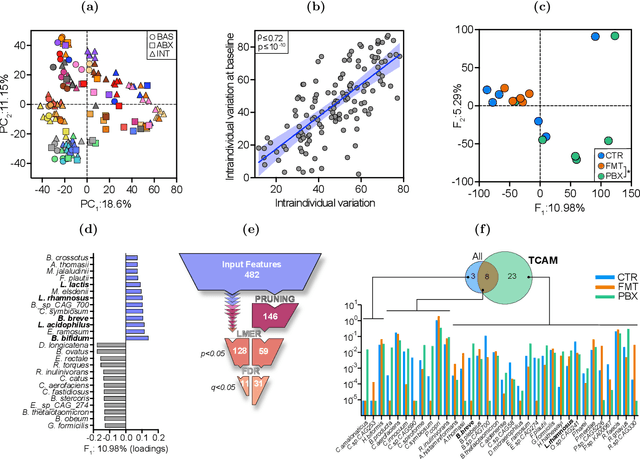
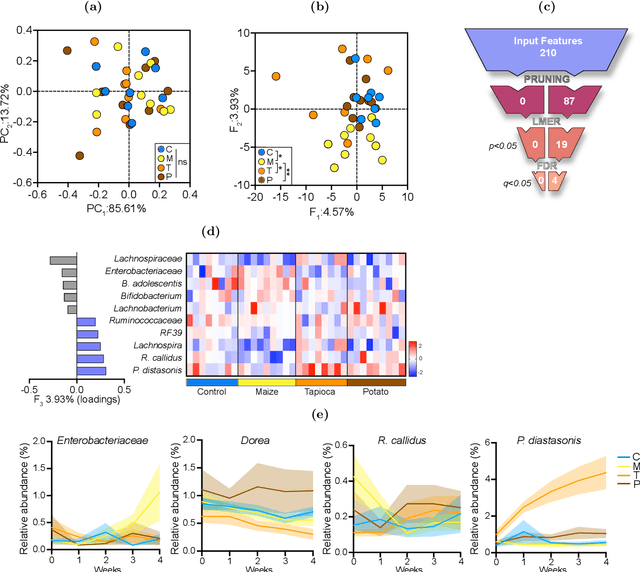
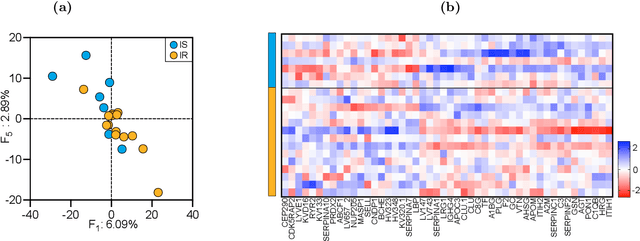
Precision medicine is a clinical approach for disease prevention, detection and treatment, which considers each individual's genetic background, environment and lifestyle. The development of this tailored avenue has been driven by the increased availability of omics methods, large cohorts of temporal samples, and their integration with clinical data. Despite the immense progression, existing computational methods for data analysis fail to provide appropriate solutions for this complex, high-dimensional and longitudinal data. In this work we have developed a new method termed TCAM, a dimensionality reduction technique for multi-way data, that overcomes major limitations when doing trajectory analysis of longitudinal omics data. Using real-world data, we show that TCAM outperforms traditional methods, as well as state-of-the-art tensor-based approaches for longitudinal microbiome data analysis. Moreover, we demonstrate the versatility of TCAM by applying it to several different omics datasets, and the applicability of it as a drop-in replacement within straightforward ML tasks.