 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Image Understanding through Delimiter Token Scaling
Feb 02, 2026Large Vision-Language Models (LVLMs) achieve strong performance on single-image tasks, but their performance declines when multiple images are provided as input. One major reason is the cross-image information leakage, where the model struggles to distinguish information across different images. Existing LVLMs already employ delimiter tokens to mark the start and end of each image, yet our analysis reveals that these tokens fail to effectively block cross-image information leakage. To enhance their effectiveness, we propose a method that scales the hidden states of delimiter tokens. This enhances the model's ability to preserve image-specific information by reinforcing intra-image interaction and limiting undesired cross-image interactions. Consequently, the model is better able to distinguish between images and reason over them more accurately. Experiments show performance gains on multi-image benchmarks such as Mantis, MuirBench, MIRB, and QBench2. We further evaluate our method on text-only tasks that require clear distinction. The method improves performance on multi-document and multi-table understanding benchmarks, including TQABench, MultiNews, and WCEP-10. Notably, our method requires no additional training or inference cost.
Knowledge Vector Weakening: Efficient Training-free Unlearning for Large Vision-Language Models
Jan 29, 2026Large Vision-Language Models (LVLMs) are widely adopted for their strong multimodal capabilities, yet they raise serious concerns such as privacy leakage and harmful content generation. Machine unlearning has emerged as a promising solution for removing the influence of specific data from trained models. However, existing approaches largely rely on gradient-based optimization, incurring substantial computational costs for large-scale LVLMs. To address this limitation, we propose Knowledge Vector Weakening (KVW), a training-free unlearning method that directly intervenes in the full model without gradient computation. KVW identifies knowledge vectors that are activated during the model's output generation on the forget set and progressively weakens their contributions, thereby preventing the model from exploiting undesirable knowledge. Experiments on the MLLMU and CLEAR benchmarks demonstrate that KVW achieves a stable forget-retain trade-off while significantly improving computational efficiency over gradient-based and LoRA-based unlearning methods.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
Sampling Bag of Views for Open-Vocabulary Object Detection
Dec 24, 2024



Existing open-vocabulary object detection (OVD) develops methods for testing unseen categories by aligning object region embeddings with corresponding VLM features. A recent study leverages the idea that VLMs implicitly learn compositional structures of semantic concepts within the image. Instead of using an individual region embedding, it utilizes a bag of region embeddings as a new representation to incorporate compositional structures into the OVD task. However, this approach often fails to capture the contextual concepts of each region, leading to noisy compositional structures. This results in only marginal performance improvements and reduced efficiency. To address this, we propose a novel concept-based alignment method that samples a more powerful and efficient compositional structure. Our approach groups contextually related ``concepts'' into a bag and adjusts the scale of concepts within the bag for more effective embedding alignment. Combined with Faster R-CNN, our method achieves improvements of 2.6 box AP50 and 0.5 mask AP over prior work on novel categories in the open-vocabulary COCO and LVIS benchmarks. Furthermore, our method reduces CLIP computation in FLOPs by 80.3% compared to previous research, significantly enhancing efficiency. Experimental results demonstrate that the proposed method outperforms previous state-of-the-art models on the OVD datasets.
Overcoming Domain Limitations in Open-vocabulary Segmentation
Oct 15, 2024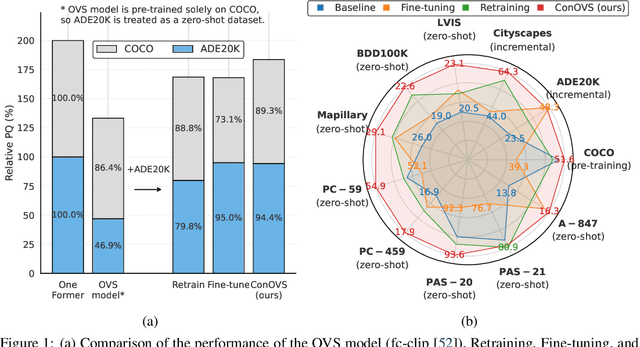
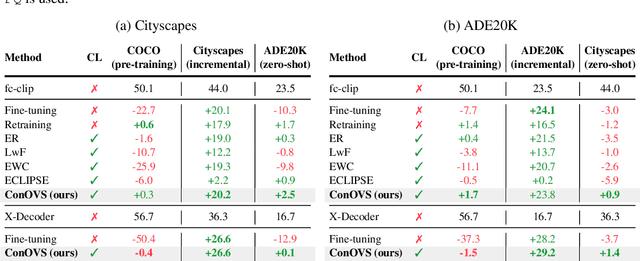
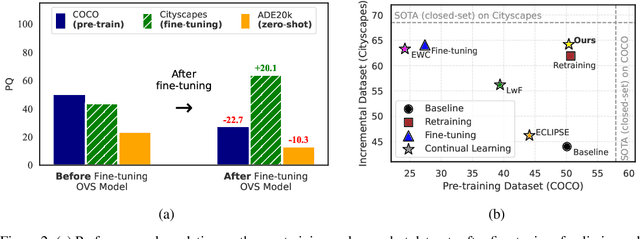
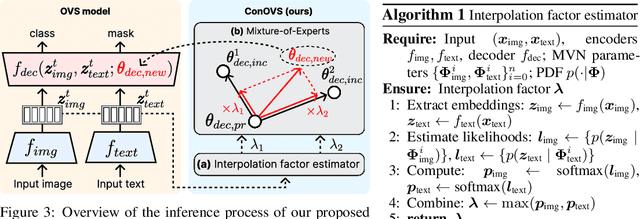
Open-vocabulary segmentation (OVS) has gained attention for its ability to recognize a broader range of classes. However, OVS models show significant performance drops when applied to unseen domains beyond the previous training dataset. Fine-tuning these models on new datasets can improve performance, but often leads to the catastrophic forgetting of previously learned knowledge. To address this issue, we propose a method that allows OVS models to learn information from new domains while preserving prior knowledge. Our approach begins by evaluating the input sample's proximity to multiple domains, using precomputed multivariate normal distributions for each domain. Based on this prediction, we dynamically interpolate between the weights of the pre-trained decoder and the fine-tuned decoders. Extensive experiments demonstrate that this approach allows OVS models to adapt to new domains while maintaining performance on the previous training dataset. The source code is available at https://github.com/dongjunhwang/dwi.
NegMerge: Consensual Weight Negation for Strong Machine Unlearning
Oct 08, 2024Machine unlearning aims to selectively remove specific knowledge from a model. Current methods, such as task arithmetic, rely on fine-tuning models on the forget set, generating a task vector, and subtracting it from the original model. However, we argue the effectiveness of this approach is highly sensitive to hyperparameter selection, necessitating careful validation to identify the best model among many fine-tuned candidates. In this paper, we propose a novel method that leverages all given fine-tuned models rather than selecting a single one. By constructing task vectors from models trained with varied hyperparameters and merging only the components of the task vectors with consistent signs, we perform unlearning by negating the merged task vector from the original model. Given that existing methods also utilize multiple fine-tuned models, our approach delivers more effective unlearning without incurring additional computational costs. We demonstrate the effectiveness of our method on both vision-language models and standard image classification models, showing improved unlearning performance with minimal degradation on the retain set, outperforming state-of-the-art techniques.
LMLT: Low-to-high Multi-Level Vision Transformer for Image Super-Resolution
Sep 05, 2024



Recent Vision Transformer (ViT)-based methods for Image Super-Resolution have demonstrated impressive performance. However, they suffer from significant complexity, resulting in high inference times and memory usage. Additionally, ViT models using Window Self-Attention (WSA) face challenges in processing regions outside their windows. To address these issues, we propose the Low-to-high Multi-Level Transformer (LMLT), which employs attention with varying feature sizes for each head. LMLT divides image features along the channel dimension, gradually reduces spatial size for lower heads, and applies self-attention to each head. This approach effectively captures both local and global information. By integrating the results from lower heads into higher heads, LMLT overcomes the window boundary issues in self-attention. Extensive experiments show that our model significantly reduces inference time and GPU memory usage while maintaining or even surpassing the performance of state-of-the-art ViT-based Image Super-Resolution methods. Our codes are availiable at https://github.com/jwgdmkj/LMLT.
ConVis: Contrastive Decoding with Hallucination Visualization for Mitigating Hallucinations in Multimodal Large Language Models
Aug 25, 2024



Hallucinations in Multimodal Large Language Models (MLLMs) where generated responses fail to accurately reflect the given image pose a significant challenge to their reliability. To address this, we introduce ConVis, a novel training-free contrastive decoding method. ConVis leverages a text-to-image (T2I) generation model to semantically reconstruct the given image from hallucinated captions. By comparing the contrasting probability distributions produced by the original and reconstructed images, ConVis enables MLLMs to capture visual contrastive signals that penalize hallucination generation. Notably, this method operates purely within the decoding process, eliminating the need for additional data or model updates. Our extensive experiments on five popular benchmarks demonstrate that ConVis effectively reduces hallucinations across various MLLMs, highlighting its potential to enhance model reliability.
Weakly Supervised Semantic Segmentation for Driving Scenes
Dec 22, 2023State-of-the-art techniques in weakly-supervised semantic segmentation (WSSS) using image-level labels exhibit severe performance degradation on driving scene datasets such as Cityscapes. To address this challenge, we develop a new WSSS framework tailored to driving scene datasets. Based on extensive analysis of dataset characteristics, we employ Contrastive Language-Image Pre-training (CLIP) as our baseline to obtain pseudo-masks. However, CLIP introduces two key challenges: (1) pseudo-masks from CLIP lack in representing small object classes, and (2) these masks contain notable noise. We propose solutions for each issue as follows. (1) We devise Global-Local View Training that seamlessly incorporates small-scale patches during model training, thereby enhancing the model's capability to handle small-sized yet critical objects in driving scenes (e.g., traffic light). (2) We introduce Consistency-Aware Region Balancing (CARB), a novel technique that discerns reliable and noisy regions through evaluating the consistency between CLIP masks and segmentation predictions. It prioritizes reliable pixels over noisy pixels via adaptive loss weighting. Notably, the proposed method achieves 51.8\% mIoU on the Cityscapes test dataset, showcasing its potential as a strong WSSS baseline on driving scene datasets. Experimental results on CamVid and WildDash2 demonstrate the effectiveness of our method across diverse datasets, even with small-scale datasets or visually challenging conditions. The code is available at https://github.com/k0u-id/CARB.
Small Objects Matters in Weakly-supervised Semantic Segmentation
Sep 25, 2023Weakly-supervised semantic segmentation (WSSS) performs pixel-wise classification given only image-level labels for training. Despite the difficulty of this task, the research community has achieved promising results over the last five years. Still, current WSSS literature misses the detailed sense of how well the methods perform on different sizes of objects. Thus we propose a novel evaluation metric to provide a comprehensive assessment across different object sizes and collect a size-balanced evaluation set to complement PASCAL VOC. With these two gadgets, we reveal that the existing WSSS methods struggle in capturing small objects. Furthermore, we propose a size-balanced cross-entropy loss coupled with a proper training strategy. It generally improves existing WSSS methods as validated upon ten baselines on three different datasets.