 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Oct 08, 2023



Despite significant results achieved by Contrastive Language-Image Pretraining (CLIP) in zero-shot image recognition, limited effort has been made exploring its potential for zero-shot video recognition. This paper presents Open-VCLIP++, a simple yet effective framework that adapts CLIP to a strong zero-shot video classifier, capable of identifying novel actions and events during testing. Open-VCLIP++ minimally modifies CLIP to capture spatial-temporal relationships in videos, thereby creating a specialized video classifier while striving for generalization. We formally demonstrate that training Open-VCLIP++ is tantamount to continual learning with zero historical data. To address this problem, we introduce Interpolated Weight Optimization, a technique that leverages the advantages of weight interpolation during both training and testing. Furthermore, we build upon large language models to produce fine-grained video descriptions. These detailed descriptions are further aligned with video features, facilitating a better transfer of CLIP to the video domain. Our approach is evaluated on three widely used action recognition datasets, following a variety of zero-shot evaluation protocols. The results demonstrate that our method surpasses existing state-of-the-art techniques by significant margins. Specifically, we achieve zero-shot accuracy scores of 88.1%, 58.7%, and 81.2% on UCF, HMDB, and Kinetics-600 datasets respectively, outpacing the best-performing alternative methods by 8.5%, 8.2%, and 12.3%. We also evaluate our approach on the MSR-VTT video-text retrieval dataset, where it delivers competitive video-to-text and text-to-video retrieval performance, while utilizing substantially less fine-tuning data compared to other methods. Code is released at https://github.com/wengzejia1/Open-VCLIP.
FlexNeRF: Photorealistic Free-viewpoint Rendering of Moving Humans from Sparse Views
Mar 25, 2023



We present FlexNeRF, a method for photorealistic freeviewpoint rendering of humans in motion from monocular videos. Our approach works well with sparse views, which is a challenging scenario when the subject is exhibiting fast/complex motions. We propose a novel approach which jointly optimizes a canonical time and pose configuration, with a pose-dependent motion field and pose-independent temporal deformations complementing each other. Thanks to our novel temporal and cyclic consistency constraints along with additional losses on intermediate representation such as segmentation, our approach provides high quality outputs as the observed views become sparser. We empirically demonstrate that our method significantly outperforms the state-of-the-art on public benchmark datasets as well as a self-captured fashion dataset. The project page is available at: https://flex-nerf.github.io/
Fighting Malicious Media Data: A Survey on Tampering Detection and Deepfake Detection
Dec 12, 2022Online media data, in the forms of images and videos, are becoming mainstream communication channels. However, recent advances in deep learning, particularly deep generative models, open the doors for producing perceptually convincing images and videos at a low cost, which not only poses a serious threat to the trustworthiness of digital information but also has severe societal implications. This motivates a growing interest of research in media tampering detection, i.e., using deep learning techniques to examine whether media data have been maliciously manipulated. Depending on the content of the targeted images, media forgery could be divided into image tampering and Deepfake techniques. The former typically moves or erases the visual elements in ordinary images, while the latter manipulates the expressions and even the identity of human faces. Accordingly, the means of defense include image tampering detection and Deepfake detection, which share a wide variety of properties. In this paper, we provide a comprehensive review of the current media tampering detection approaches, and discuss the challenges and trends in this field for future research.
TAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 14, 2022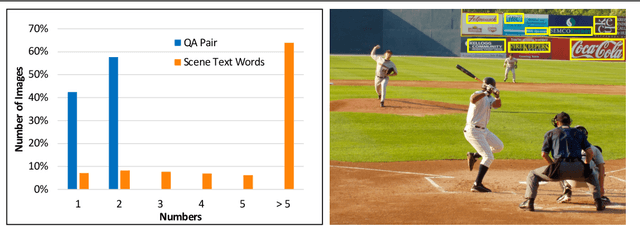
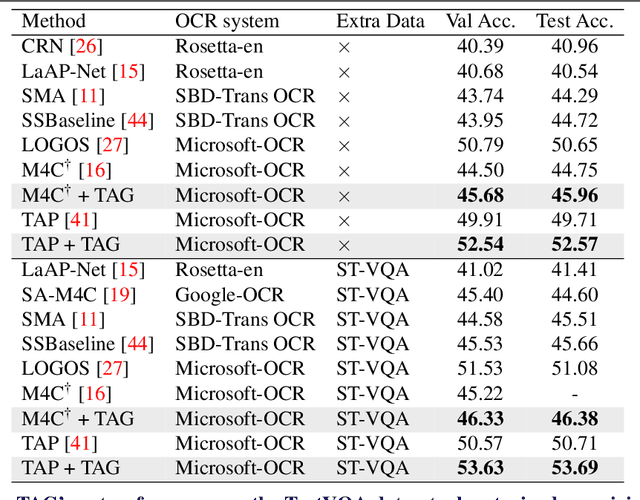

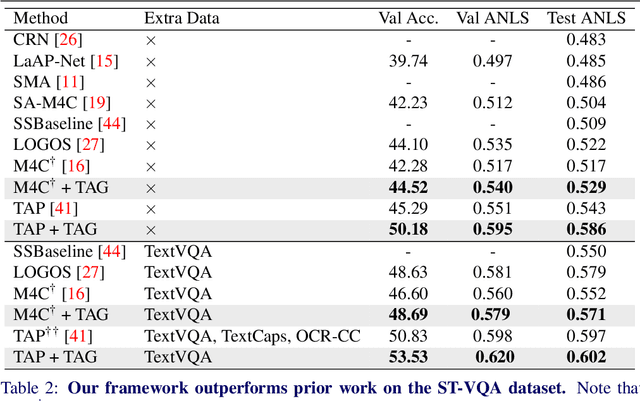
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.
InvGAN: Invertible GANs
Dec 10, 2021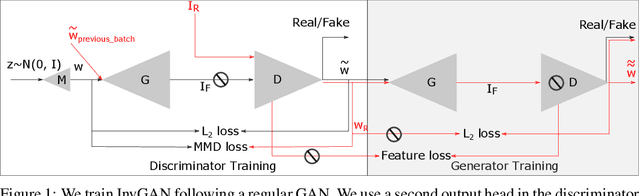
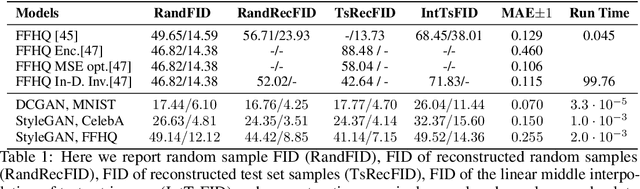


Generation of photo-realistic images, semantic editing and representation learning are a few of many potential applications of high resolution generative models. Recent progress in GANs have established them as an excellent choice for such tasks. However, since they do not provide an inference model, image editing or downstream tasks such as classification can not be done on real images using the GAN latent space. Despite numerous efforts to train an inference model or design an iterative method to invert a pre-trained generator, previous methods are dataset (e.g. human face images) and architecture (e.g. StyleGAN) specific. These methods are nontrivial to extend to novel datasets or architectures. We propose a general framework that is agnostic to architecture and datasets. Our key insight is that, by training the inference and the generative model together, we allow them to adapt to each other and to converge to a better quality model. Our \textbf{InvGAN}, short for Invertible GAN, successfully embeds real images to the latent space of a high quality generative model. This allows us to perform image inpainting, merging, interpolation and online data augmentation. We demonstrate this with extensive qualitative and quantitative experiments.
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
Jun 05, 2021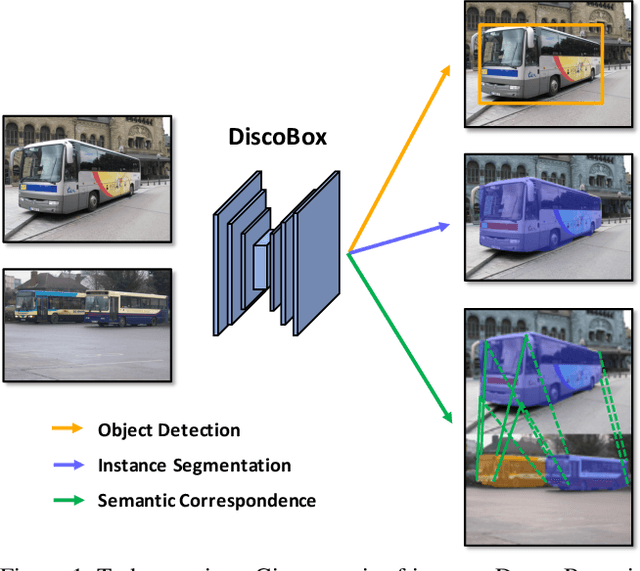
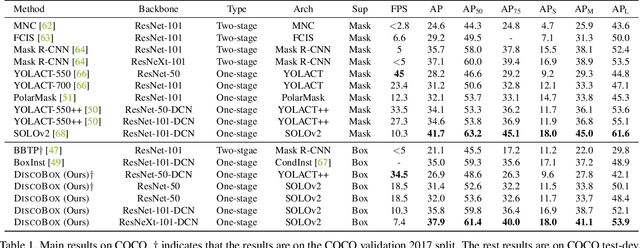
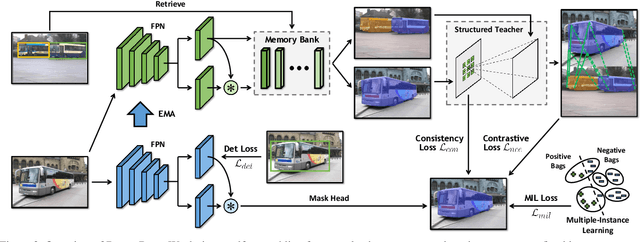
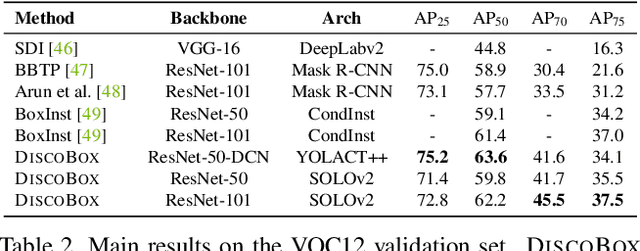
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision. The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes. Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning. We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods. We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.
Rethinking Pseudo Labels for Semi-Supervised Object Detection
Jun 01, 2021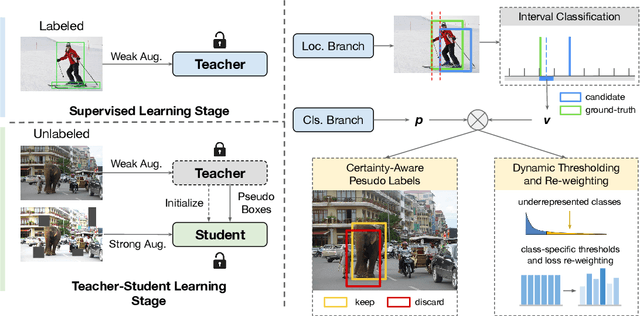
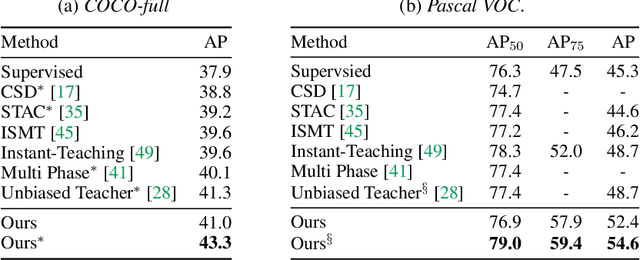
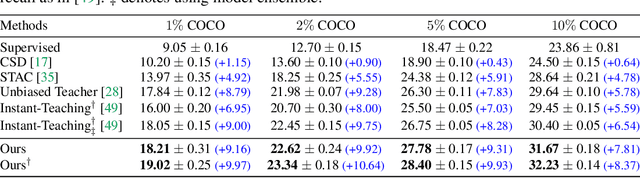
Recent advances in semi-supervised object detection (SSOD) are largely driven by consistency-based pseudo-labeling methods for image classification tasks, producing pseudo labels as supervisory signals. However, when using pseudo labels, there is a lack of consideration in localization precision and amplified class imbalance, both of which are critical for detection tasks. In this paper, we introduce certainty-aware pseudo labels tailored for object detection, which can effectively estimate the classification and localization quality of derived pseudo labels. This is achieved by converting conventional localization as a classification task followed by refinement. Conditioned on classification and localization quality scores, we dynamically adjust the thresholds used to generate pseudo labels and reweight loss functions for each category to alleviate the class imbalance problem. Extensive experiments demonstrate that our method improves state-of-the-art SSOD performance by 1-2% and 4-6% AP on COCO and PASCAL VOC, respectively. In the limited-annotation regime, our approach improves supervised baselines by up to 10% AP using only 1-10% labeled data from COCO.
Learned Spatial Representations for Few-shot Talking-Head Synthesis
Apr 29, 2021
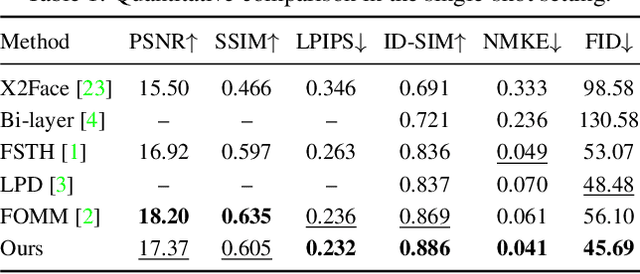
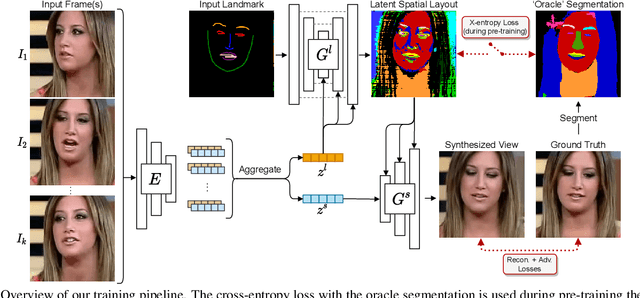
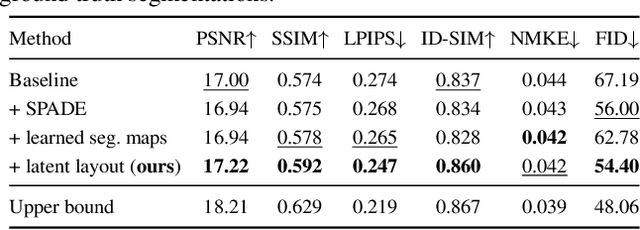
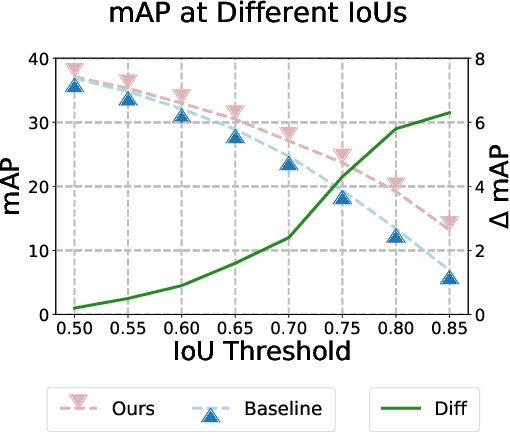
We propose a novel approach for few-shot talking-head synthesis. While recent works in neural talking heads have produced promising results, they can still produce images that do not preserve the identity of the subject in source images. We posit this is a result of the entangled representation of each subject in a single latent code that models 3D shape information, identity cues, colors, lighting and even background details. In contrast, we propose to factorize the representation of a subject into its spatial and style components. Our method generates a target frame in two steps. First, it predicts a dense spatial layout for the target image. Second, an image generator utilizes the predicted layout for spatial denormalization and synthesizes the target frame. We experimentally show that this disentangled representation leads to a significant improvement over previous methods, both quantitatively and qualitatively.
THAT: Two Head Adversarial Training for Improving Robustness at Scale
Mar 25, 2021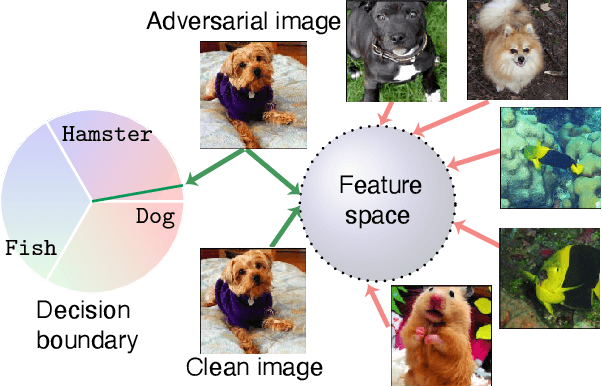
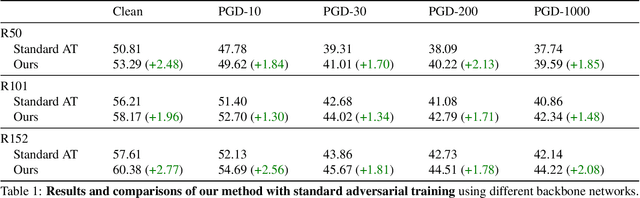
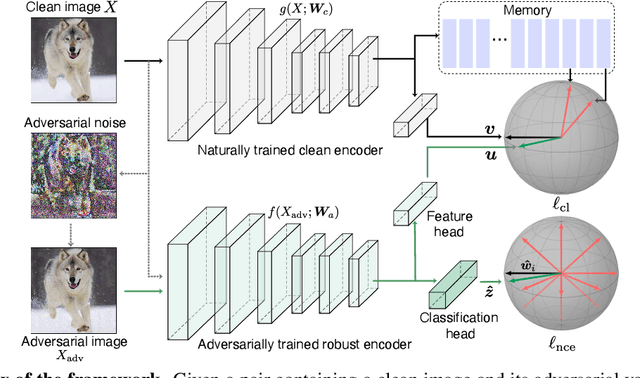
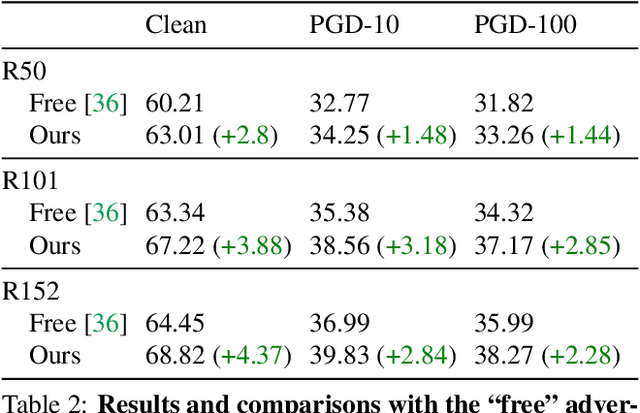
Many variants of adversarial training have been proposed, with most research focusing on problems with relatively few classes. In this paper, we propose Two Head Adversarial Training (THAT), a two-stream adversarial learning network that is designed to handle the large-scale many-class ImageNet dataset. The proposed method trains a network with two heads and two loss functions; one to minimize feature-space domain shift between natural and adversarial images, and one to promote high classification accuracy. This combination delivers a hardened network that achieves state of the art robust accuracy while maintaining high natural accuracy on ImageNet. Through extensive experiments, we demonstrate that the proposed framework outperforms alternative methods under both standard and "free" adversarial training settings.
Scale Normalized Image Pyramids with AutoFocus for Object Detection
Feb 10, 2021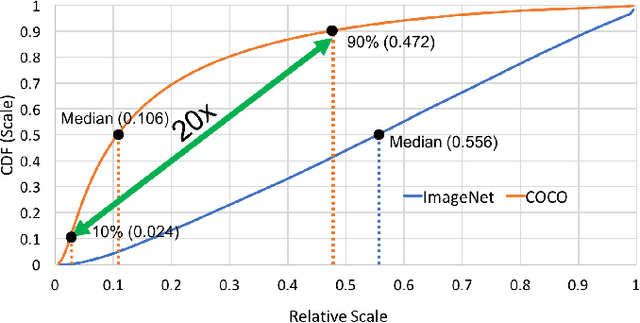

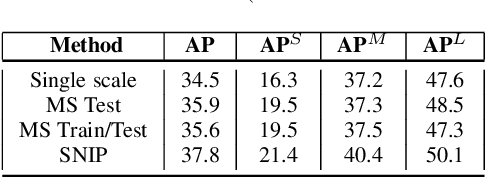
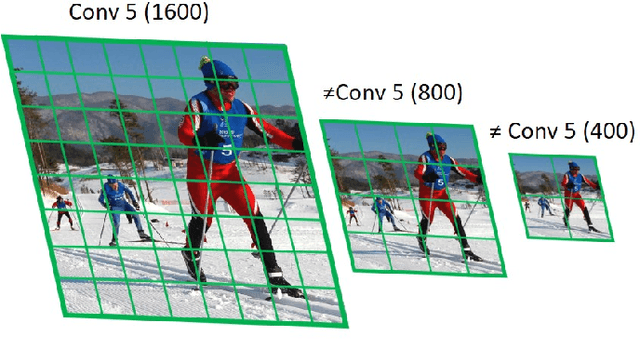
We present an efficient foveal framework to perform object detection. A scale normalized image pyramid (SNIP) is generated that, like human vision, only attends to objects within a fixed size range at different scales. Such a restriction of objects' size during training affords better learning of object-sensitive filters, and therefore, results in better accuracy. However, the use of an image pyramid increases the computational cost. Hence, we propose an efficient spatial sub-sampling scheme which only operates on fixed-size sub-regions likely to contain objects (as object locations are known during training). The resulting approach, referred to as Scale Normalized Image Pyramid with Efficient Resampling or SNIPER, yields up to 3 times speed-up during training. Unfortunately, as object locations are unknown during inference, the entire image pyramid still needs processing. To this end, we adopt a coarse-to-fine approach, and predict the locations and extent of object-like regions which will be processed in successive scales of the image pyramid. Intuitively, it's akin to our active human-vision that first skims over the field-of-view to spot interesting regions for further processing and only recognizes objects at the right resolution. The resulting algorithm is referred to as AutoFocus and results in a 2.5-5 times speed-up during inference when used with SNIP.