 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECO: Quantized Training without Full-Precision Master Weights
Jan 29, 2026Quantization has significantly improved the compute and memory efficiency of Large Language Model (LLM) training. However, existing approaches still rely on accumulating their updates in high-precision: concretely, gradient updates must be applied to a high-precision weight buffer, known as $\textit{master weights}$. This buffer introduces substantial memory overhead, particularly for Sparse Mixture of Experts (SMoE) models, where model parameters and optimizer states dominate memory usage. To address this, we introduce the Error-Compensating Optimizer (ECO), which eliminates master weights by applying updates directly to quantized parameters. ECO quantizes weights after each step and carefully injects the resulting quantization error into the optimizer momentum, forming an error-feedback loop with no additional memory. We prove that, under standard assumptions and a decaying learning rate, ECO converges to a constant-radius neighborhood of the optimum, while naive master-weight removal can incur an error that is inversely proportional to the learning rate. We show empirical results for pretraining small Transformers (30-800M), a Gemma-3 1B model, and a 2.1B parameter Sparse MoE model with FP8 quantization, and fine-tuning DeepSeek-MoE-16B in INT4 precision. Throughout, ECO matches baselines with master weights up to near-lossless accuracy, significantly shifting the static memory vs validation loss Pareto frontier.
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Apr 28, 2025



Vector quantization, a problem rooted in Shannon's source coding theory, aims to quantize high-dimensional Euclidean vectors while minimizing distortion in their geometric structure. We propose TurboQuant to address both mean-squared error (MSE) and inner product distortion, overcoming limitations of existing methods that fail to achieve optimal distortion rates. Our data-oblivious algorithms, suitable for online applications, achieve near-optimal distortion rates (within a small constant factor) across all bit-widths and dimensions. TurboQuant achieves this by randomly rotating input vectors, inducing a concentrated Beta distribution on coordinates, and leveraging the near-independence property of distinct coordinates in high dimensions to simply apply optimal scalar quantizers per each coordinate. Recognizing that MSE-optimal quantizers introduce bias in inner product estimation, we propose a two-stage approach: applying an MSE quantizer followed by a 1-bit Quantized JL (QJL) transform on the residual, resulting in an unbiased inner product quantizer. We also provide a formal proof of the information-theoretic lower bounds on best achievable distortion rate by any vector quantizer, demonstrating that TurboQuant closely matches these bounds, differing only by a small constant ($\approx 2.7$) factor. Experimental results validate our theoretical findings, showing that for KV cache quantization, we achieve absolute quality neutrality with 3.5 bits per channel and marginal quality degradation with 2.5 bits per channel. Furthermore, in nearest neighbor search tasks, our method outperforms existing product quantization techniques in recall while reducing indexing time to virtually zero.
BalanceKV: KV Cache Compression through Discrepancy Theory
Feb 11, 2025



Large language models (LLMs) have achieved impressive success, but their high memory requirements present challenges for long-context token generation. The memory complexity of long-context LLMs is primarily due to the need to store Key-Value (KV) embeddings in their KV cache. We present BalanceKV, a KV cache compression method based on geometric sampling process stemming from Banaszczyk's vector balancing theory, which introduces dependencies informed by the geometry of keys and value tokens, and improves precision. BalanceKV offers both theoretically proven and empirically validated performance improvements over existing methods.
PolarQuant: Quantizing KV Caches with Polar Transformation
Feb 04, 2025Large language models (LLMs) require significant memory to store Key-Value (KV) embeddings in their KV cache, especially when handling long-range contexts. Quantization of these KV embeddings is a common technique to reduce memory consumption. This work introduces PolarQuant, a novel quantization method employing random preconditioning and polar transformation. Our method transforms the KV embeddings into polar coordinates using an efficient recursive algorithm and then quantizes resulting angles. Our key insight is that, after random preconditioning, the angles in the polar representation exhibit a tightly bounded and highly concentrated distribution with an analytically computable form. This nice distribution eliminates the need for explicit normalization, a step required by traditional quantization methods which introduces significant memory overhead because quantization parameters (e.g., zero point and scale) must be stored in full precision per each data block. PolarQuant bypasses this normalization step, enabling substantial memory savings. The long-context evaluation demonstrates that PolarQuant compresses the KV cache by over x4.2 while achieving the best quality scores compared to the state-of-the-art methods.
QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead
Jun 05, 2024



Serving LLMs requires substantial memory due to the storage requirements of Key-Value (KV) embeddings in the KV cache, which grows with sequence length. An effective approach to compress KV cache is quantization. However, traditional quantization methods face significant memory overhead due to the need to store quantization constants (at least a zero point and a scale) in full precision per data block. Depending on the block size, this overhead can add 1 or 2 bits per quantized number. We introduce QJL, a new quantization approach that consists of a Johnson-Lindenstrauss (JL) transform followed by sign-bit quantization. In contrast to existing methods, QJL eliminates memory overheads by removing the need for storing quantization constants. We propose an asymmetric estimator for the inner product of two vectors and demonstrate that applying QJL to one vector and a standard JL transform without quantization to the other provides an unbiased estimator with minimal distortion. We have developed an efficient implementation of the QJL sketch and its corresponding inner product estimator, incorporating a lightweight CUDA kernel for optimized computation. When applied across various LLMs and NLP tasks to quantize the KV cache to only 3 bits, QJL demonstrates a more than fivefold reduction in KV cache memory usage without compromising accuracy, all while achieving faster runtime. Codes are available at \url{https://github.com/amirzandieh/QJL}.
SubGen: Token Generation in Sublinear Time and Memory
Feb 08, 2024

Despite the significant success of large language models (LLMs), their extensive memory requirements pose challenges for deploying them in long-context token generation. The substantial memory footprint of LLM decoders arises from the necessity to store all previous tokens in the attention module, a requirement imposed by key-value (KV) caching. In this work, our focus is on developing an efficient compression technique for the KV cache. Empirical evidence indicates a significant clustering tendency within key embeddings in the attention module. Building on this key insight, we have devised a novel caching method with sublinear complexity, employing online clustering on key tokens and online $\ell_2$ sampling on values. The result is a provably accurate and efficient attention decoding algorithm, termed SubGen. Not only does this algorithm ensure a sublinear memory footprint and sublinear time complexity, but we also establish a tight error bound for our approach. Empirical evaluations on long-context question-answering tasks demonstrate that SubGen significantly outperforms existing and state-of-the-art KV cache compression methods in terms of performance and efficiency.
HyperAttention: Long-context Attention in Near-Linear Time
Oct 11, 2023



We present an approximate attention mechanism named HyperAttention to address the computational challenges posed by the growing complexity of long contexts used in Large Language Models (LLMs). Recent work suggests that in the worst-case scenario, quadratic time is necessary unless the entries of the attention matrix are bounded or the matrix has low stable rank. We introduce two parameters which measure: (1) the max column norm in the normalized attention matrix, and (2) the ratio of row norms in the unnormalized attention matrix after detecting and removing large entries. We use these fine-grained parameters to capture the hardness of the problem. Despite previous lower bounds, we are able to achieve a linear time sampling algorithm even when the matrix has unbounded entries or a large stable rank, provided the above parameters are small. HyperAttention features a modular design that easily accommodates integration of other fast low-level implementations, particularly FlashAttention. Empirically, employing Locality Sensitive Hashing (LSH) to identify large entries, HyperAttention outperforms existing methods, giving significant speed improvements compared to state-of-the-art solutions like FlashAttention. We validate the empirical performance of HyperAttention on a variety of different long-context length datasets. For example, HyperAttention makes the inference time of ChatGLM2 50\% faster on 32k context length while perplexity increases from 5.6 to 6.3. On larger context length, e.g., 131k, with causal masking, HyperAttention offers 5-fold speedup on a single attention layer.
KDEformer: Accelerating Transformers via Kernel Density Estimation
Feb 05, 2023



Dot-product attention mechanism plays a crucial role in modern deep architectures (e.g., Transformer) for sequence modeling, however, na\"ive exact computation of this model incurs quadratic time and memory complexities in sequence length, hindering the training of long-sequence models. Critical bottlenecks are due to the computation of partition functions in the denominator of softmax function as well as the multiplication of the softmax matrix with the matrix of values. Our key observation is that the former can be reduced to a variant of the kernel density estimation (KDE) problem, and an efficient KDE solver can be further utilized to accelerate the latter via subsampling-based fast matrix products. Our proposed KDEformer can approximate the attention in sub-quadratic time with provable spectral norm bounds, while all prior results merely provide entry-wise error bounds. Empirically, we verify that KDEformer outperforms other attention approximations in terms of accuracy, memory, and runtime on various pre-trained models. On BigGAN image generation, we achieve better generative scores than the exact computation with over $4\times$ speedup. For ImageNet classification with T2T-ViT, KDEformer shows over $18\times$ speedup while the accuracy drop is less than $0.5\%$.
Fast Neural Kernel Embeddings for General Activations
Sep 09, 2022
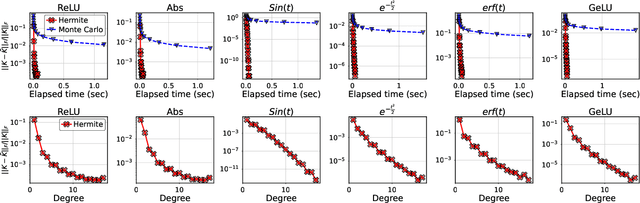
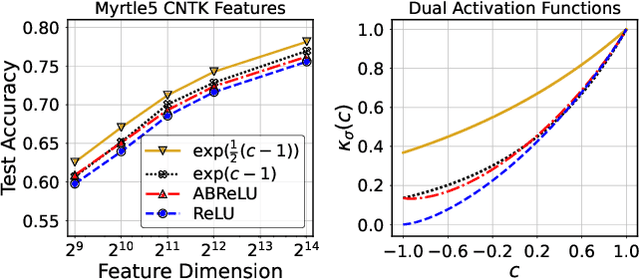
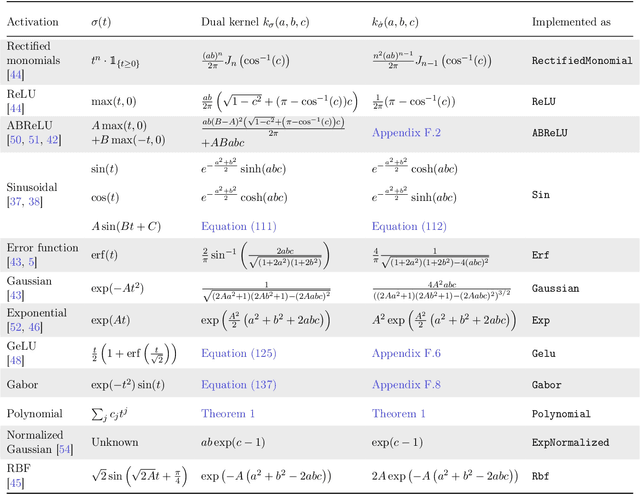
Infinite width limit has shed light on generalization and optimization aspects of deep learning by establishing connections between neural networks and kernel methods. Despite their importance, the utility of these kernel methods was limited in large-scale learning settings due to their (super-)quadratic runtime and memory complexities. Moreover, most prior works on neural kernels have focused on the ReLU activation, mainly due to its popularity but also due to the difficulty of computing such kernels for general activations. In this work, we overcome such difficulties by providing methods to work with general activations. First, we compile and expand the list of activation functions admitting exact dual activation expressions to compute neural kernels. When the exact computation is unknown, we present methods to effectively approximate them. We propose a fast sketching method that approximates any multi-layered Neural Network Gaussian Process (NNGP) kernel and Neural Tangent Kernel (NTK) matrices for a wide range of activation functions, going beyond the commonly analyzed ReLU activation. This is done by showing how to approximate the neural kernels using the truncated Hermite expansion of any desired activation functions. While most prior works require data points on the unit sphere, our methods do not suffer from such limitations and are applicable to any dataset of points in $\mathbb{R}^d$. Furthermore, we provide a subspace embedding for NNGP and NTK matrices with near input-sparsity runtime and near-optimal target dimension which applies to any \emph{homogeneous} dual activation functions with rapidly convergent Taylor expansion. Empirically, with respect to exact convolutional NTK (CNTK) computation, our method achieves $106\times$ speedup for approximate CNTK of a 5-layer Myrtle network on CIFAR-10 dataset.
Near Optimal Reconstruction of Spherical Harmonic Expansions
Feb 25, 2022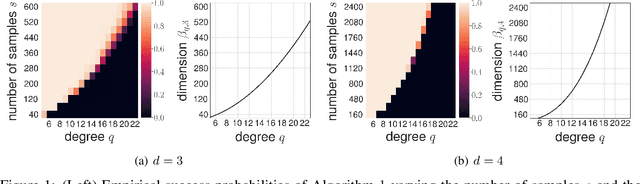
We propose an algorithm for robust recovery of the spherical harmonic expansion of functions defined on the d-dimensional unit sphere $\mathbb{S}^{d-1}$ using a near-optimal number of function evaluations. We show that for any $f \in L^2(\mathbb{S}^{d-1})$, the number of evaluations of $f$ needed to recover its degree-$q$ spherical harmonic expansion equals the dimension of the space of spherical harmonics of degree at most $q$ up to a logarithmic factor. Moreover, we develop a simple yet efficient algorithm to recover degree-$q$ expansion of $f$ by only evaluating the function on uniformly sampled points on $\mathbb{S}^{d-1}$. Our algorithm is based on the connections between spherical harmonics and Gegenbauer polynomials and leverage score sampling methods. Unlike the prior results on fast spherical harmonic transform, our proposed algorithm works efficiently using a nearly optimal number of samples in any dimension d. We further illustrate the empirical performance of our algorithm on numerical examples.