 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
May 18, 2026Large Reasoning Models (LRMs) introduce new opportunities for safety monitoring through their Chain of Thought (CoT) reasoning. However, CoT is not always faithful to the model's final output, undermining its reliability as a monitoring tool. To address this, we investigate the hidden representations of LRMs to determine whether future behavior can be predicted from prompt and CoT representations. By evaluating a probe at each generated token, we construct a probe trajectory, the continuous evolution of a concept's probability across the reasoning process. We find that future model behavior is more distinguishable when examined over the full trajectory than from a single static prediction. To characterize these temporal dynamics, we extract signal-processing features that capture volatility, trend, and steady-state behavior, significantly improving the separation of future model states. We also present two methodological insights. First, template-based training data achieves near-parity with dynamically generated model responses, eliminating the need for a costly initial inference and labeling. Second, the choice of pooling operation is critical: average-pooling and last-token methods collapse to near-random performance, while max-pooling achieves up to 95% AUROC and yields stable probe trajectories. Using four datasets and four reasoning models across the domains of safety and mathematics, we demonstrate that trajectory features encode task-specific dynamics that improve outcome separability. These findings establish probe trajectories as a complementary framework for monitoring LRM behavior. Warning: This article contains potentially harmful content.
LumiMotion: Improving Gaussian Relighting with Scene Dynamics
Apr 13, 2026In 3D reconstruction, the problem of inverse rendering, namely recovering the illumination of the scene and the material properties, is fundamental. Existing Gaussian Splatting-based methods primarily target static scenes and often assume simplified or moderate lighting to avoid entangling shadows with surface appearance. This limits their ability to accurately separate lighting effects from material properties, particularly in real-world conditions. We address this limitation by leveraging dynamic elements - regions of the scene that undergo motion - as a supervisory signal for inverse rendering. Motion reveals the same surfaces under varying lighting conditions, providing stronger cues for disentangling material and illumination. This thesis is supported by our experimental results which show we improve LPIPS by 23% for albedo estimation and by 15% for scene relighting relative to next-best baseline. To this end, we introduce LumiMotion, the first Gaussian-based approach that leverages dynamics for inverse rendering and operates in arbitrary dynamic scenes. Our method learns a dynamic 2D Gaussian Splatting representation that employs a set of novel constraints which encourage the dynamic regions of the scene to deform, while keeping static regions stable. As we demonstrate, this separation is crucial for correct optimization of the albedo. Finally, we release a new synthetic benchmark comprising five scenes under four lighting conditions, each in both static and dynamic variants, for the first time enabling systematic evaluation of inverse rendering methods in dynamic environments and challenging lighting. Link to project page: https://joaxkal.github.io/LumiMotion/
Conditioned Activation Transport for T2I Safety Steering
Mar 03, 2026Despite their impressive capabilities, current Text-to-Image (T2I) models remain prone to generating unsafe and toxic content. While activation steering offers a promising inference-time intervention, we observe that linear activation steering frequently degrades image quality when applied to benign prompts. To address this trade-off, we first construct SafeSteerDataset, a contrastive dataset containing 2300 safe and unsafe prompt pairs with high cosine similarity. Leveraging this data, we propose Conditioned Activation Transport (CAT), a framework that employs a geometry-based conditioning mechanism and nonlinear transport maps. By conditioning transport maps to activate only within unsafe activation regions, we minimize interference with benign queries. We validate our approach on two state-of-the-art architectures: Z-Image and Infinity. Experiments demonstrate that CAT generalizes effectively across these backbones, significantly reducing Attack Success Rate while maintaining image fidelity compared to unsteered generations. Warning: This paper contains potentially offensive text and images.
Reducing Estimation Uncertainty Using Normalizing Flows and Stratification
Feb 16, 2026Estimating the expectation of a real-valued function of a random variable from sample data is a critical aspect of statistical analysis, with far-reaching implications in various applications. Current methodologies typically assume (semi-)parametric distributions such as Gaussian or mixed Gaussian, leading to significant estimation uncertainty if these assumptions do not hold. We propose a flow-based model, integrated with stratified sampling, that leverages a parametrized neural network to offer greater flexibility in modeling unknown data distributions, thereby mitigating this limitation. Our model shows a marked reduction in estimation uncertainty across multiple datasets, including high-dimensional (30 and 128) ones, outperforming crude Monte Carlo estimators and Gaussian mixture models. Reproducible code is available at https://github.com/rnoxy/flowstrat.
ELROND: Exploring and decomposing intrinsic capabilities of diffusion models
Feb 10, 2026A single text prompt passed to a diffusion model often yields a wide range of visual outputs determined solely by stochastic process, leaving users with no direct control over which specific semantic variations appear in the image. While existing unsupervised methods attempt to analyze these variations via output features, they omit the underlying generative process. In this work, we propose a framework to disentangle these semantic directions directly within the input embedding space. To that end, we collect a set of gradients obtained by backpropagating the differences between stochastic realizations of a fixed prompt that we later decompose into meaningful steering directions with either Principal Components Analysis or Sparse Autoencoder. Our approach yields three key contributions: (1) it isolates interpretable, steerable directions for precise, fine-grained control over a single concept; (2) it effectively mitigates mode collapse in distilled models by reintroducing lost diversity; and (3) it establishes a novel estimator for concept complexity under a specific model, based on the dimensionality of the discovered subspace.
ExpertSim: Fast Particle Detector Simulation Using Mixture-of-Generative-Experts
Aug 28, 2025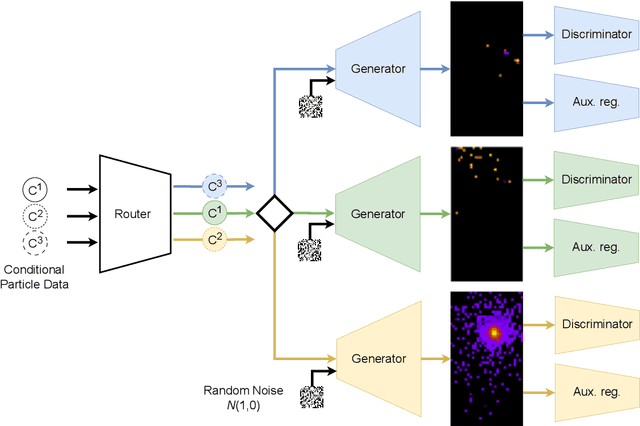
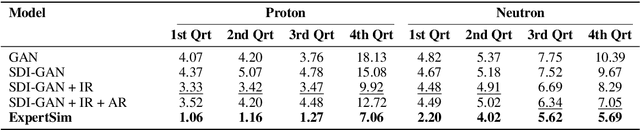
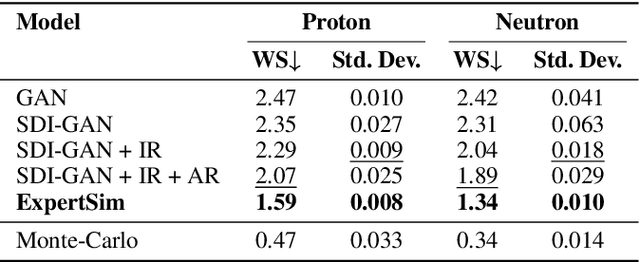
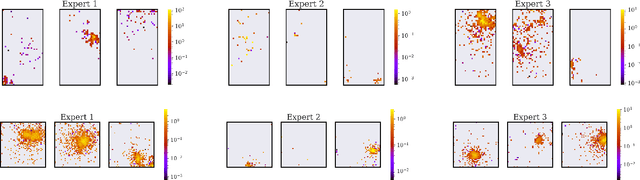
Simulating detector responses is a crucial part of understanding the inner workings of particle collisions in the Large Hadron Collider at CERN. Such simulations are currently performed with statistical Monte Carlo methods, which are computationally expensive and put a significant strain on CERN's computational grid. Therefore, recent proposals advocate for generative machine learning methods to enable more efficient simulations. However, the distribution of the data varies significantly across the simulations, which is hard to capture with out-of-the-box methods. In this study, we present ExpertSim - a deep learning simulation approach tailored for the Zero Degree Calorimeter in the ALICE experiment. Our method utilizes a Mixture-of-Generative-Experts architecture, where each expert specializes in simulating a different subset of the data. This allows for a more precise and efficient generation process, as each expert focuses on a specific aspect of the calorimeter response. ExpertSim not only improves accuracy, but also provides a significant speedup compared to the traditional Monte-Carlo methods, offering a promising solution for high-efficiency detector simulations in particle physics experiments at CERN. We make the code available at https://github.com/patrick-bedkowski/expertsim-mix-of-generative-experts.
GEPAR3D: Geometry Prior-Assisted Learning for 3D Tooth Segmentation
Jul 31, 2025Tooth segmentation in Cone-Beam Computed Tomography (CBCT) remains challenging, especially for fine structures like root apices, which is critical for assessing root resorption in orthodontics. We introduce GEPAR3D, a novel approach that unifies instance detection and multi-class segmentation into a single step tailored to improve root segmentation. Our method integrates a Statistical Shape Model of dentition as a geometric prior, capturing anatomical context and morphological consistency without enforcing restrictive adjacency constraints. We leverage a deep watershed method, modeling each tooth as a continuous 3D energy basin encoding voxel distances to boundaries. This instance-aware representation ensures accurate segmentation of narrow, complex root apices. Trained on publicly available CBCT scans from a single center, our method is evaluated on external test sets from two in-house and two public medical centers. GEPAR3D achieves the highest overall segmentation performance, averaging a Dice Similarity Coefficient (DSC) of 95.0% (+2.8% over the second-best method) and increasing recall to 95.2% (+9.5%) across all test sets. Qualitative analyses demonstrated substantial improvements in root segmentation quality, indicating significant potential for more accurate root resorption assessment and enhanced clinical decision-making in orthodontics. We provide the implementation and dataset at https://github.com/tomek1911/GEPAR3D.
1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
Mar 19, 2025Scaling up self-supervised learning has driven breakthroughs in language and vision, yet comparable progress has remained elusive in reinforcement learning (RL). In this paper, we study building blocks for self-supervised RL that unlock substantial improvements in scalability, with network depth serving as a critical factor. Whereas most RL papers in recent years have relied on shallow architectures (around 2 - 5 layers), we demonstrate that increasing the depth up to 1024 layers can significantly boost performance. Our experiments are conducted in an unsupervised goal-conditioned setting, where no demonstrations or rewards are provided, so an agent must explore (from scratch) and learn how to maximize the likelihood of reaching commanded goals. Evaluated on simulated locomotion and manipulation tasks, our approach increases performance by $2\times$ - $50\times$. Increasing the model depth not only increases success rates but also qualitatively changes the behaviors learned.
Maybe I Should Not Answer That, but... Do LLMs Understand The Safety of Their Inputs?
Feb 22, 2025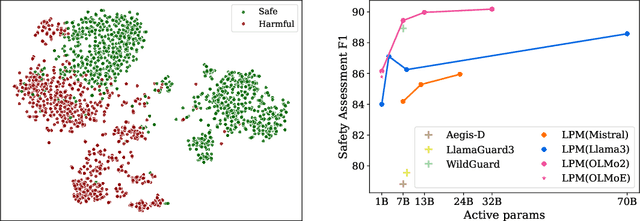
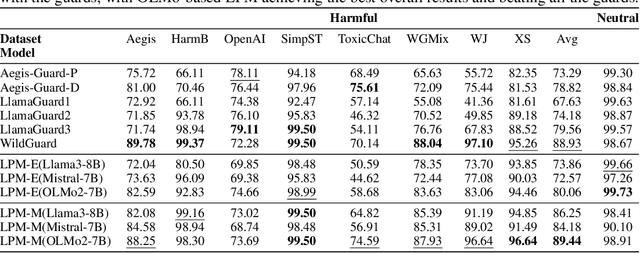

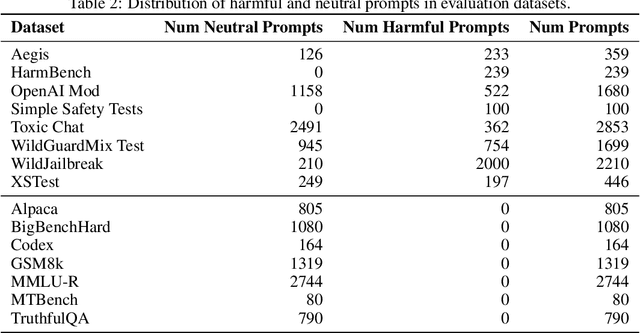
Ensuring the safety of the Large Language Model (LLM) is critical, but currently used methods in most cases sacrifice the model performance to obtain increased safety or perform poorly on data outside of their adaptation distribution. We investigate existing methods for such generalization and find them insufficient. Surprisingly, while even plain LLMs recognize unsafe prompts, they may still generate unsafe responses. To avoid performance degradation and preserve safe performance, we advocate for a two-step framework, where we first identify unsafe prompts via a lightweight classifier, and apply a "safe" model only to such prompts. In particular, we explore the design of the safety detector in more detail, investigating the use of different classifier architectures and prompting techniques. Interestingly, we find that the final hidden state for the last token is enough to provide robust performance, minimizing false positives on benign data while performing well on malicious prompt detection. Additionally, we show that classifiers trained on the representations from different model layers perform comparably on the latest model layers, indicating that safety representation is present in the LLMs' hidden states at most model stages. Our work is a step towards efficient, representation-based safety mechanisms for LLMs.
Exploring the Stability Gap in Continual Learning: The Role of the Classification Head
Nov 06, 2024



Continual learning (CL) has emerged as a critical area in machine learning, enabling neural networks to learn from evolving data distributions while mitigating catastrophic forgetting. However, recent research has identified the stability gap -- a phenomenon where models initially lose performance on previously learned tasks before partially recovering during training. Such learning dynamics are contradictory to the intuitive understanding of stability in continual learning where one would expect the performance to degrade gradually instead of rapidly decreasing and then partially recovering later. To better understand and alleviate the stability gap, we investigate it at different levels of the neural network architecture, particularly focusing on the role of the classification head. We introduce the nearest-mean classifier (NMC) as a tool to attribute the influence of the backbone and the classification head on the stability gap. Our experiments demonstrate that NMC not only improves final performance, but also significantly enhances training stability across various continual learning benchmarks, including CIFAR100, ImageNet100, CUB-200, and FGVC Aircrafts. Moreover, we find that NMC also reduces task-recency bias. Our analysis provides new insights into the stability gap and suggests that the primary contributor to this phenomenon is the linear head, rather than the insufficient representation learning.