 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: Goal-Initialized Directional Understanding for End-to-End Visual Navigation
Jun 09, 2026Learning-based visual navigation for legged robots typically relies on continuous goal updates from hierarchical state estimation to provide a persistent directional reference. This reliance incurs additional sensory and computational overhead and deviates from fully end-to-end mobile autonomy. Furthermore, under partial observability, policies are prone to learn myopic behaviors, easily becoming trapped in dead ends and complex structural layouts. To address these limitations, we investigate a goal-initialized navigation setting, where the target is provided only once at the beginning of an episode, requiring the robot to operate based on intrinsic spatial memory without subsequent goal updates from external modules. In this work, we propose GUIDE, a fully end-to-end reinforcement learning framework designed to cultivate internal directional awareness. Specifically, GUIDE incorporates a spatial anchor predictor that leverages multi-frequency proprioceptive history to extract egomotion representations, thereby maintaining a persistent long-horizon spatial context for navigation. Concurrently, it utilizes raw depth streams to perceive local environmental geometry. We evaluate the proposed framework across both simulation and real-world scenarios on a quadruped robot. Experiments show that GUIDE learns reliable egomotion and directional awareness, enabling a fully end-to-end deployed policy to safely navigate through dense clutter and structured mazes without subsequent goal guidance or prior maps.
Physion-Eval: Evaluating Physical Realism in Generated Video via Human Reasoning
Mar 20, 2026Video generation models are increasingly used as world simulators for storytelling, simulation, and embodied AI. As these models advance, a key question arises: do generated videos obey the physical laws of the real world? Existing evaluations largely rely on automated metrics or coarse human judgments such as preferences or rubric-based checks. While useful for assessing perceptual quality, these methods provide limited insight into when and why generated dynamics violate real-world physical constraints. We introduce Physion-Eval, a large-scale benchmark of expert human reasoning for diagnosing physical realism failures in videos generated by five state-of-the-art models across egocentric and exocentric views, containing 10,990 expert reasoning traces spanning 22 fine-grained physical categories. Each generated video is derived from a corresponding real-world reference video depicting a clear physical process, and annotated with temporally localized glitches, structured failure categories, and natural-language explanations of the violated physical behavior. Using this dataset, we reveal a striking limitation of current video generation models: in physics-critical scenarios, 83.3% of exocentric and 93.5% of egocentric generated videos exhibit at least one human-identifiable physical glitch. We hope Physion-Eval will set a new standard for physical realism evaluation and guide the development of physics-grounded video generation. The benchmark is publicly available at https://huggingface.co/datasets/PhysionLabs/Physion-Eval.
Seeking Physics in Diffusion Noise
Mar 15, 2026Do video diffusion models encode signals predictive of physical plausibility? We probe intermediate denoising representations of a pretrained Diffusion Transformer (DiT) and find that physically plausible and implausible videos are partially separable in mid-layer feature space across noise levels. This separability cannot be fully attributed to visual quality or generator identity, suggesting recoverable physics-related cues in frozen DiT features. Leveraging this observation, we introduce progressive trajectory selection, an inference-time strategy that scores parallel denoising trajectories at a few intermediate checkpoints using a lightweight physics verifier trained on frozen features, and prunes low-scoring candidates early. Extensive experiments on PhyGenBench demonstrate that our method improves physical consistency while reducing inference cost, achieving comparable results to Best-of-K sampling with substantially fewer denoising steps.
HyperDet: 3D Object Detection with Hyper 4D Radar Point Clouds
Feb 13, 20264D mmWave radar provides weather-robust, velocity-aware measurements and is more cost-effective than LiDAR. However, radar-only 3D detection still trails LiDAR-based systems because radar point clouds are sparse, irregular, and often corrupted by multipath noise, yielding weak and unstable geometry. We present HyperDet, a detector-agnostic radar-only 3D detection framework that constructs a task-aware hyper 4D radar point cloud for standard LiDAR-oriented detectors. HyperDet aggregates returns from multiple surround-view 4D radars over consecutive frames to improve coverage and density, then applies geometry-aware cross-sensor consensus validation with a lightweight self-consistency check outside overlap regions to suppress inconsistent returns. It further integrates a foreground-focused diffusion module with training-time mixed radar-LiDAR supervision to densify object structures while lifting radar attributes (e.g., Doppler, RCS); the model is distilled into a consistency model for single-step inference. On MAN TruckScenes, HyperDet consistently improves over raw radar inputs with VoxelNeXt and CenterPoint, partially narrowing the radar-LiDAR gap. These results show that input-level refinement enables radar to better leverage LiDAR-oriented detectors without architectural modifications.
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
Wavelet-based Multi-View Fusion of 4D Radar Tensor and Camera for Robust 3D Object Detection
Dec 28, 20254D millimeter-wave (mmWave) radar has been widely adopted in autonomous driving and robot perception due to its low cost and all-weather robustness. However, its inherent sparsity and limited semantic richness significantly constrain perception capability. Recently, fusing camera data with 4D radar has emerged as a promising cost effective solution, by exploiting the complementary strengths of the two modalities. Nevertheless, point-cloud-based radar often suffer from information loss introduced by multi-stage signal processing, while directly utilizing raw 4D radar data incurs prohibitive computational costs. To address these challenges, we propose WRCFormer, a novel 3D object detection framework that fuses raw radar cubes with camera inputs via multi-view representations of the decoupled radar cube. Specifically, we design a Wavelet Attention Module as the basic module of wavelet-based Feature Pyramid Network (FPN) to enhance the representation of sparse radar signals and image data. We further introduce a two-stage query-based, modality-agnostic fusion mechanism termed Geometry-guided Progressive Fusion to efficiently integrate multi-view features from both modalities. Extensive experiments demonstrate that WRCFormer achieves state-of-the-art performance on the K-Radar benchmarks, surpassing the best model by approximately 2.4% in all scenarios and 1.6% in the sleet scenario, highlighting its robustness under adverse weather conditions.
RadarGen: Automotive Radar Point Cloud Generation from Cameras
Dec 19, 2025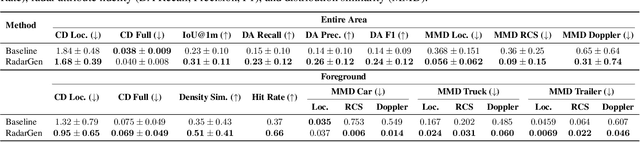
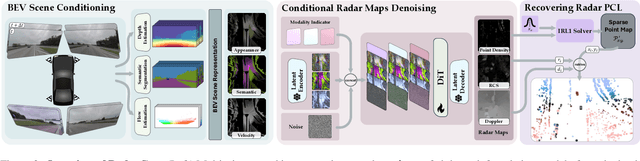
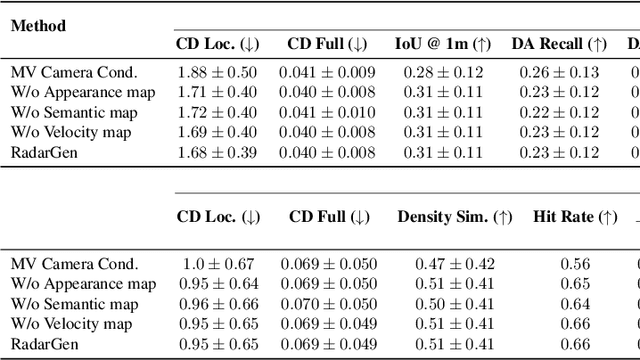
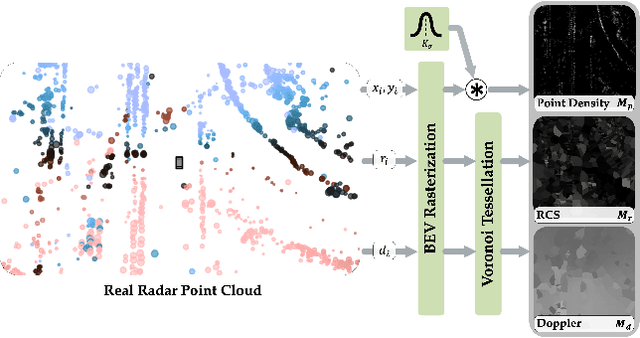
We present RadarGen, a diffusion model for synthesizing realistic automotive radar point clouds from multi-view camera imagery. RadarGen adapts efficient image-latent diffusion to the radar domain by representing radar measurements in bird's-eye-view form that encodes spatial structure together with radar cross section (RCS) and Doppler attributes. A lightweight recovery step reconstructs point clouds from the generated maps. To better align generation with the visual scene, RadarGen incorporates BEV-aligned depth, semantic, and motion cues extracted from pretrained foundation models, which guide the stochastic generation process toward physically plausible radar patterns. Conditioning on images makes the approach broadly compatible, in principle, with existing visual datasets and simulation frameworks, offering a scalable direction for multimodal generative simulation. Evaluations on large-scale driving data show that RadarGen captures characteristic radar measurement distributions and reduces the gap to perception models trained on real data, marking a step toward unified generative simulation across sensing modalities.
M4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
Dec 17, 2025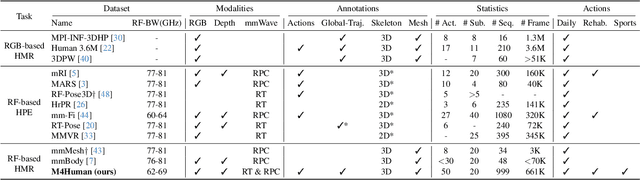
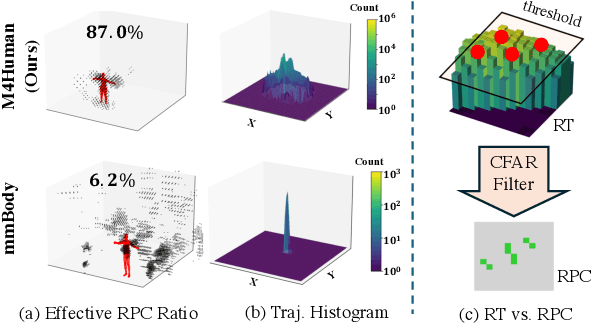

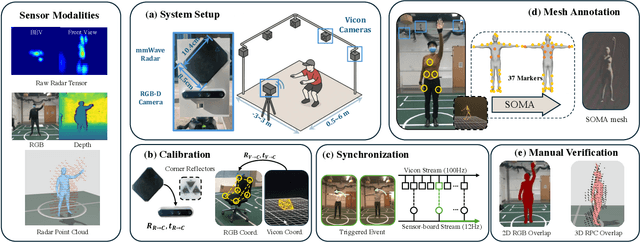
Human mesh reconstruction (HMR) provides direct insights into body-environment interaction, which enables various immersive applications. While existing large-scale HMR datasets rely heavily on line-of-sight RGB input, vision-based sensing is limited by occlusion, lighting variation, and privacy concerns. To overcome these limitations, recent efforts have explored radio-frequency (RF) mmWave radar for privacy-preserving indoor human sensing. However, current radar datasets are constrained by sparse skeleton labels, limited scale, and simple in-place actions. To advance the HMR research community, we introduce M4Human, the current largest-scale (661K-frame) ($9\times$ prior largest) multimodal benchmark, featuring high-resolution mmWave radar, RGB, and depth data. M4Human provides both raw radar tensors (RT) and processed radar point clouds (RPC) to enable research across different levels of RF signal granularity. M4Human includes high-quality motion capture (MoCap) annotations with 3D meshes and global trajectories, and spans 20 subjects and 50 diverse actions, including in-place, sit-in-place, and free-space sports or rehabilitation movements. We establish benchmarks on both RT and RPC modalities, as well as multimodal fusion with RGB-D modalities. Extensive results highlight the significance of M4Human for radar-based human modeling while revealing persistent challenges under fast, unconstrained motion. The dataset and code will be released after the paper publication.
Dexterous Manipulation through Imitation Learning: A Survey
Apr 04, 2025Dexterous manipulation, which refers to the ability of a robotic hand or multi-fingered end-effector to skillfully control, reorient, and manipulate objects through precise, coordinated finger movements and adaptive force modulation, enables complex interactions similar to human hand dexterity. With recent advances in robotics and machine learning, there is a growing demand for these systems to operate in complex and unstructured environments. Traditional model-based approaches struggle to generalize across tasks and object variations due to the high-dimensionality and complex contact dynamics of dexterous manipulation. Although model-free methods such as reinforcement learning (RL) show promise, they require extensive training, large-scale interaction data, and carefully designed rewards for stability and effectiveness. Imitation learning (IL) offers an alternative by allowing robots to acquire dexterous manipulation skills directly from expert demonstrations, capturing fine-grained coordination and contact dynamics while bypassing the need for explicit modeling and large-scale trial-and-error. This survey provides an overview of dexterous manipulation methods based on imitation learning (IL), details recent advances, and addresses key challenges in the field. Additionally, it explores potential research directions to enhance IL-driven dexterous manipulation. Our goal is to offer researchers and practitioners a comprehensive introduction to this rapidly evolving domain.
RadarOcc: Robust 3D Occupancy Prediction with 4D Imaging Radar
May 22, 20243D occupancy-based perception pipeline has significantly advanced autonomous driving by capturing detailed scene descriptions and demonstrating strong generalizability across various object categories and shapes. Current methods predominantly rely on LiDAR or camera inputs for 3D occupancy prediction. These methods are susceptible to adverse weather conditions, limiting the all-weather deployment of self-driving cars. To improve perception robustness, we leverage the recent advances in automotive radars and introduce a novel approach that utilizes 4D imaging radar sensors for 3D occupancy prediction. Our method, RadarOcc, circumvents the limitations of sparse radar point clouds by directly processing the 4D radar tensor, thus preserving essential scene details. RadarOcc innovatively addresses the challenges associated with the voluminous and noisy 4D radar data by employing Doppler bins descriptors, sidelobe-aware spatial sparsification, and range-wise self-attention mechanisms. To minimize the interpolation errors associated with direct coordinate transformations, we also devise a spherical-based feature encoding followed by spherical-to-Cartesian feature aggregation. We benchmark various baseline methods based on distinct modalities on the public K-Radar dataset. The results demonstrate RadarOcc's state-of-the-art performance in radar-based 3D occupancy prediction and promising results even when compared with LiDAR- or camera-based methods. Additionally, we present qualitative evidence of the superior performance of 4D radar in adverse weather conditions and explore the impact of key pipeline components through ablation studies.