 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Overcoming the Distance Estimation Bottleneck in Camera Trap Distance Sampling
May 10, 2021
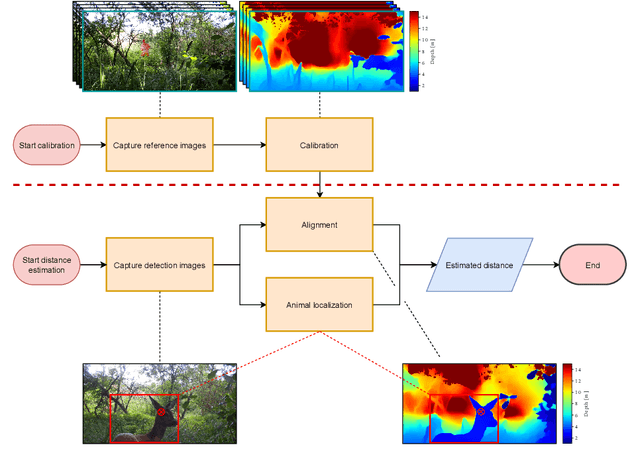
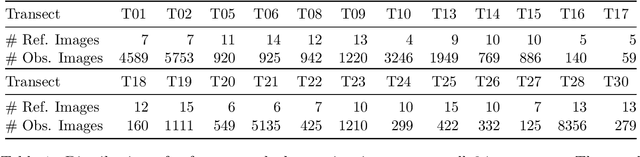

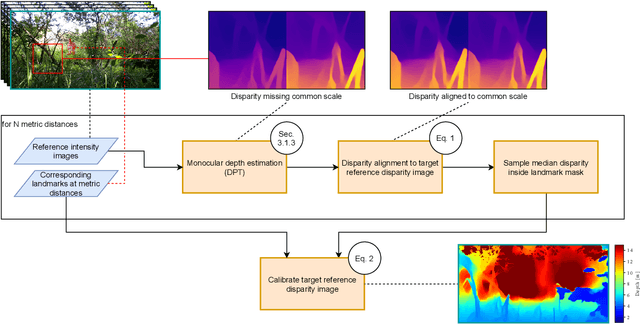
Biodiversity crisis is still accelerating. Estimating animal abundance is of critical importance to assess, for example, the consequences of land-use change and invasive species on species composition, or the effectiveness of conservation interventions. Camera trap distance sampling (CTDS) is a recently developed monitoring method providing reliable estimates of wildlife population density and abundance. However, in current applications of CTDS, the required camera-to-animal distance measurements are derived by laborious, manual and subjective estimation methods. To overcome this distance estimation bottleneck in CTDS, this study proposes a completely automatized workflow utilizing state-of-the-art methods of image processing and pattern recognition.
A Self-Supervised Bootstrap Method for Single-Image 3D Face Reconstruction
Dec 17, 2018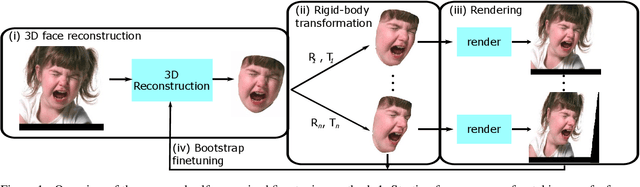

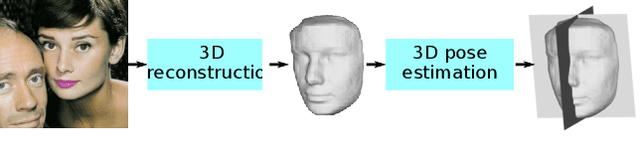
State-of-the-art methods for 3D reconstruction of faces from a single image require 2D-3D pairs of ground-truth data for supervision. Such data is costly to acquire, and most datasets available in the literature are restricted to pairs for which the input 2D images depict faces in a near fronto-parallel pose. Therefore, many data-driven methods for single-image 3D facial reconstruction perform poorly on profile and near-profile faces. We propose a method to improve the performance of single-image 3D facial reconstruction networks by utilizing the network to synthesize its own training data for fine-tuning, comprising: (i) single-image 3D reconstruction of faces in near-frontal images without ground-truth 3D shape; (ii) application of a rigid-body transformation to the reconstructed face model; (iii) rendering of the face model from new viewpoints; and (iv) use of the rendered image and corresponding 3D reconstruction as additional data for supervised fine-tuning. The new 2D-3D pairs thus produced have the same high-quality observed for near fronto-parallel reconstructions, thereby nudging the network towards more uniform performance as a function of the viewing angle of input faces. Application of the proposed technique to the fine-tuning of a state-of-the-art single-image 3D-reconstruction network for faces demonstrates the usefulness of the method, with particularly significant gains for profile or near-profile views.
Segmenting Objects in Day and Night:Edge-Conditioned CNN for Thermal Image Semantic Segmentation
Jul 24, 2019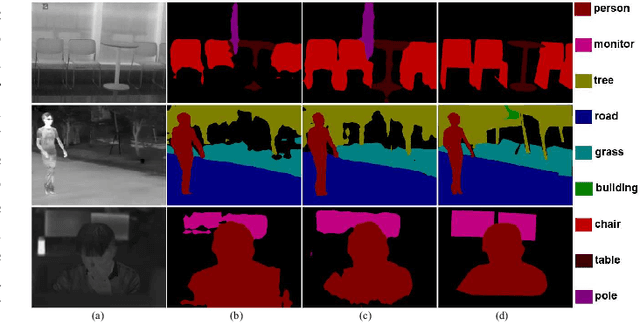

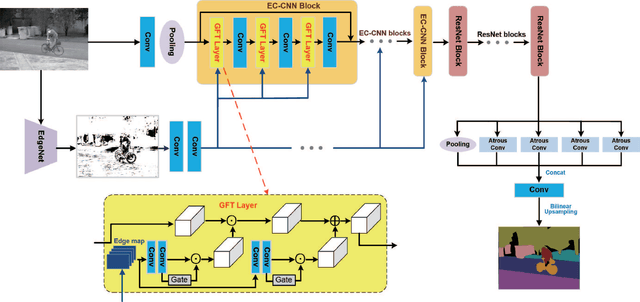
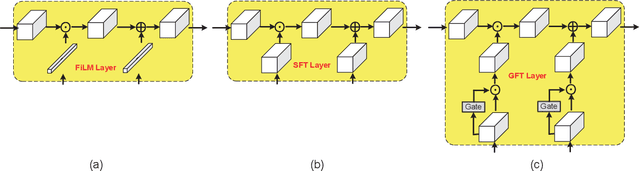
Despite much research progress in image semantic segmentation, it remains challenging under adverse environmental conditions caused by imaging limitations of visible spectrum. While thermal infrared cameras have several advantages over cameras for the visible spectrum, such as operating in total darkness, insensitive to illumination variations, robust to shadow effects and strong ability to penetrate haze and smog. These advantages of thermal infrared cameras make the segmentation of semantic objects in day and night. In this paper, we propose a novel network architecture, called edge-conditioned convolutional neural network (EC-CNN), for thermal image semantic segmentation. Particularly, we elaborately design a gated feature-wise transform layer in EC-CNN to adaptively incorporate edge prior knowledge. The whole EC-CNN is end-to-end trained, and can generate high-quality segmentation results with the edge guidance. Meanwhile, we also introduce a new benchmark dataset named "Segment Objects in Day And night"(SODA) for comprehensive evaluations in thermal image semantic segmentation. SODA contains over 7,168 manually annotated and synthetically generated thermal images with 20 semantic region labels and from a broad range of viewpoints and scene complexities. Extensive experiments on SODA demonstrate the effectiveness of the proposed EC-CNN against the state-of-the-art methods.
Single View Physical Distance Estimation using Human Pose
Jun 18, 2021
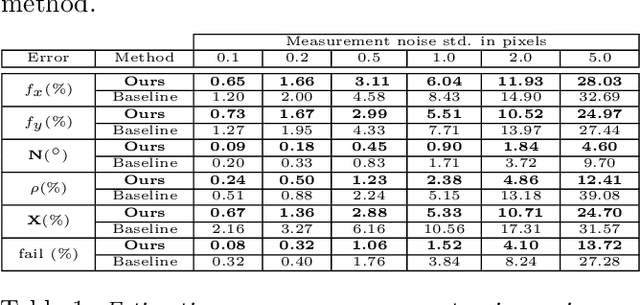
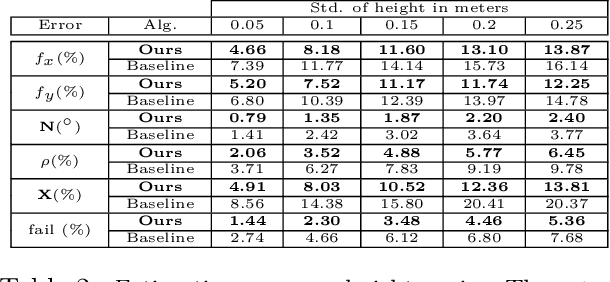
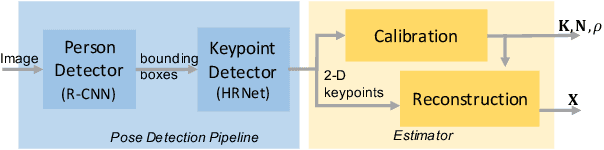
We propose a fully automated system that simultaneously estimates the camera intrinsics, the ground plane, and physical distances between people from a single RGB image or video captured by a camera viewing a 3-D scene from a fixed vantage point. To automate camera calibration and distance estimation, we leverage priors about human pose and develop a novel direct formulation for pose-based auto-calibration and distance estimation, which shows state-of-the-art performance on publicly available datasets. The proposed approach enables existing camera systems to measure physical distances without needing a dedicated calibration process or range sensors, and is applicable to a broad range of use cases such as social distancing and workplace safety. Furthermore, to enable evaluation and drive research in this area, we contribute to the publicly available MEVA dataset with additional distance annotations, resulting in MEVADA -- the first evaluation benchmark in the world for the pose-based auto-calibration and distance estimation problem.
The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification
Jul 05, 2021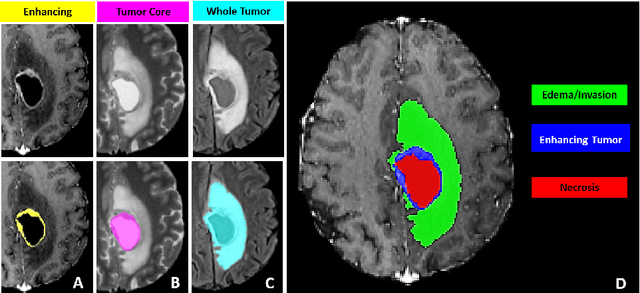
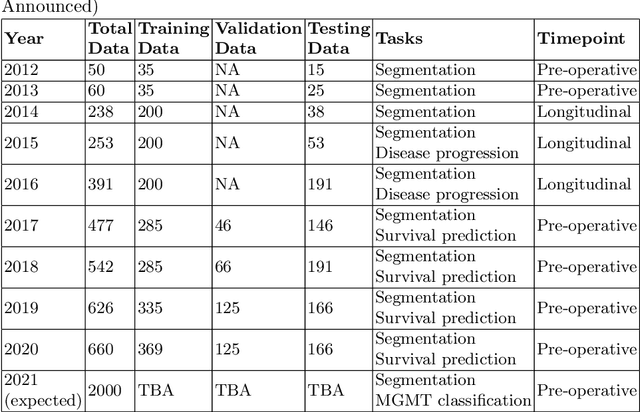
The BraTS 2021 challenge celebrates its 10th anniversary and is jointly organized by the Radiological Society of North America (RSNA), the American Society of Neuroradiology (ASNR), and the Medical Image Computing and Computer Assisted Interventions (MICCAI) society. Since its inception, BraTS has been focusing on being a common benchmarking venue for brain glioma segmentation algorithms, with well-curated multi-institutional multi-parametric magnetic resonance imaging (mpMRI) data. Gliomas are the most common primary malignancies of the central nervous system, with varying degrees of aggressiveness and prognosis. The RSNA-ASNR-MICCAI BraTS 2021 challenge targets the evaluation of computational algorithms assessing the same tumor compartmentalization, as well as the underlying tumor's molecular characterization, in pre-operative baseline mpMRI data from 2,000 patients. Specifically, the two tasks that BraTS 2021 focuses on are: a) the segmentation of the histologically distinct brain tumor sub-regions, and b) the classification of the tumor's O[6]-methylguanine-DNA methyltransferase (MGMT) promoter methylation status. The performance evaluation of all participating algorithms in BraTS 2021 will be conducted through the Sage Bionetworks Synapse platform (Task 1) and Kaggle (Task 2), concluding in distributing to the top ranked participants monetary awards of $60,000 collectively.
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis
Mar 03, 2021
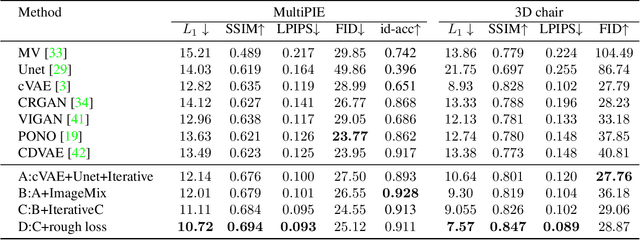
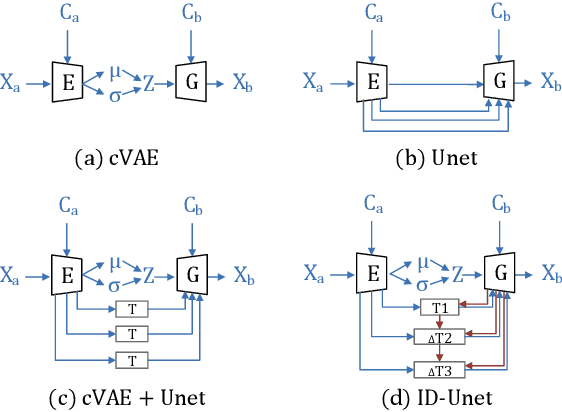
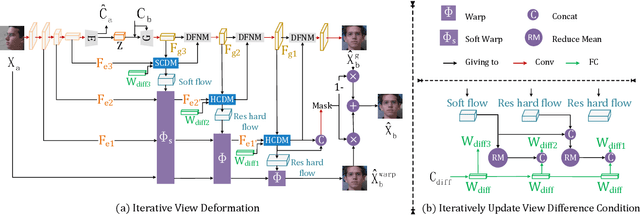
View synthesis is usually done by an autoencoder, in which the encoder maps a source view image into a latent content code, and the decoder transforms it into a target view image according to the condition. However, the source contents are often not well kept in this setting, which leads to unnecessary changes during the view translation. Although adding skipped connections, like Unet, alleviates the problem, but it often causes the failure on the view conformity. This paper proposes a new architecture by performing the source-to-target deformation in an iterative way. Instead of simply incorporating the features from multiple layers of the encoder, we design soft and hard deformation modules, which warp the encoder features to the target view at different resolutions, and give results to the decoder to complement the details. Particularly, the current warping flow is not only used to align the feature of the same resolution, but also as an approximation to coarsely deform the high resolution feature. Then the residual flow is estimated and applied in the high resolution, so that the deformation is built up in the coarse-to-fine fashion. To better constrain the model, we synthesize a rough target view image based on the intermediate flows and their warped features. The extensive ablation studies and the final results on two different data sets show the effectiveness of the proposed model.
Towards Efficient Tensor Decomposition-Based DNN Model Compression with Optimization Framework
Jul 26, 2021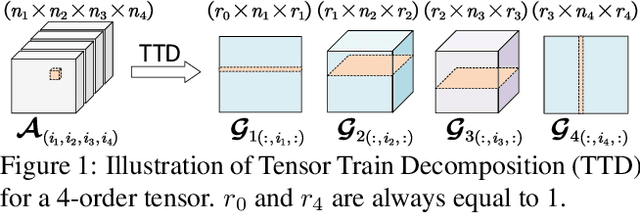
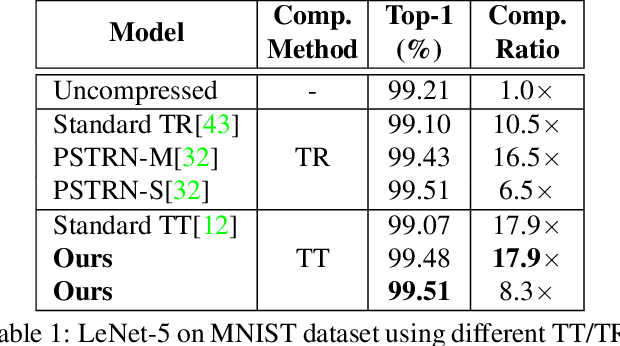
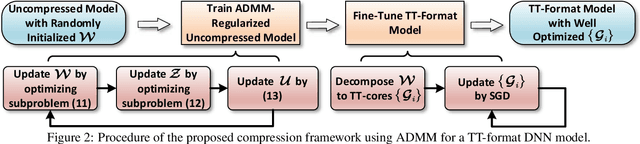
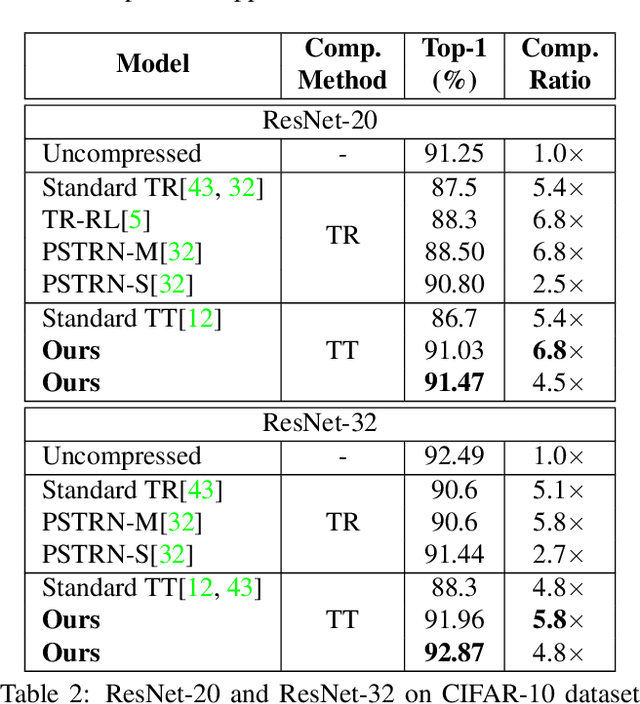
Advanced tensor decomposition, such as Tensor train (TT) and Tensor ring (TR), has been widely studied for deep neural network (DNN) model compression, especially for recurrent neural networks (RNNs). However, compressing convolutional neural networks (CNNs) using TT/TR always suffers significant accuracy loss. In this paper, we propose a systematic framework for tensor decomposition-based model compression using Alternating Direction Method of Multipliers (ADMM). By formulating TT decomposition-based model compression to an optimization problem with constraints on tensor ranks, we leverage ADMM technique to systemically solve this optimization problem in an iterative way. During this procedure, the entire DNN model is trained in the original structure instead of TT format, but gradually enjoys the desired low tensor rank characteristics. We then decompose this uncompressed model to TT format and fine-tune it to finally obtain a high-accuracy TT-format DNN model. Our framework is very general, and it works for both CNNs and RNNs, and can be easily modified to fit other tensor decomposition approaches. We evaluate our proposed framework on different DNN models for image classification and video recognition tasks. Experimental results show that our ADMM-based TT-format models demonstrate very high compression performance with high accuracy. Notably, on CIFAR-100, with 2.3X and 2.4X compression ratios, our models have 1.96% and 2.21% higher top-1 accuracy than the original ResNet-20 and ResNet-32, respectively. For compressing ResNet-18 on ImageNet, our model achieves 2.47X FLOPs reduction without accuracy loss.
Bridging the Gap Between Object Detection and User Intent via Query-Modulation
Jun 18, 2021

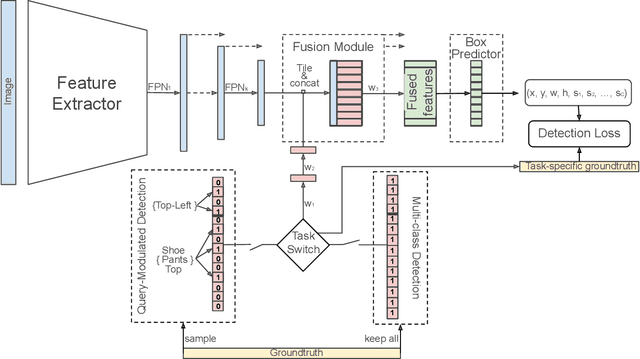
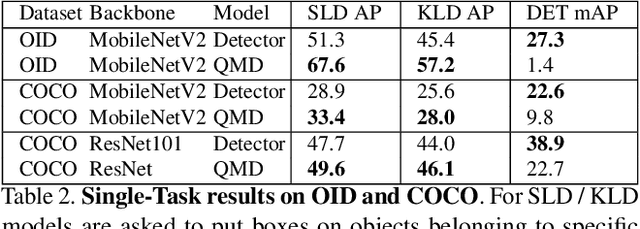
When interacting with objects through cameras, or pictures, users often have a specific intent. For example, they may want to perform a visual search. However, most object detection models ignore the user intent, relying on image pixels as their only input. This often leads to incorrect results, such as lack of a high-confidence detection on the object of interest, or detection with a wrong class label. In this paper we investigate techniques to modulate standard object detectors to explicitly account for the user intent, expressed as an embedding of a simple query. Compared to standard object detectors, query-modulated detectors show superior performance at detecting objects for a given label of interest. Thanks to large-scale training data synthesized from standard object detection annotations, query-modulated detectors can also outperform specialized referring expression recognition systems. Furthermore, they can be simultaneously trained to solve for both query-modulated detection and standard object detection.
Histogram of Cell Types: Deep Learning for Automated Bone Marrow Cytology
Jul 05, 2021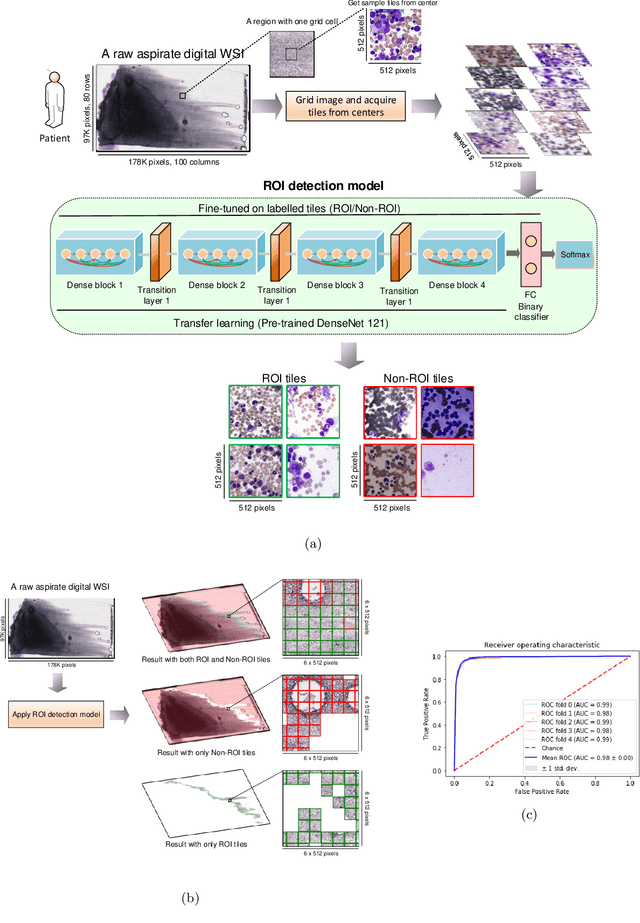
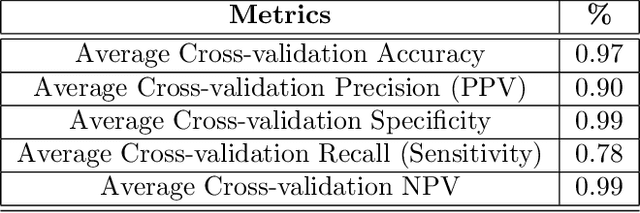
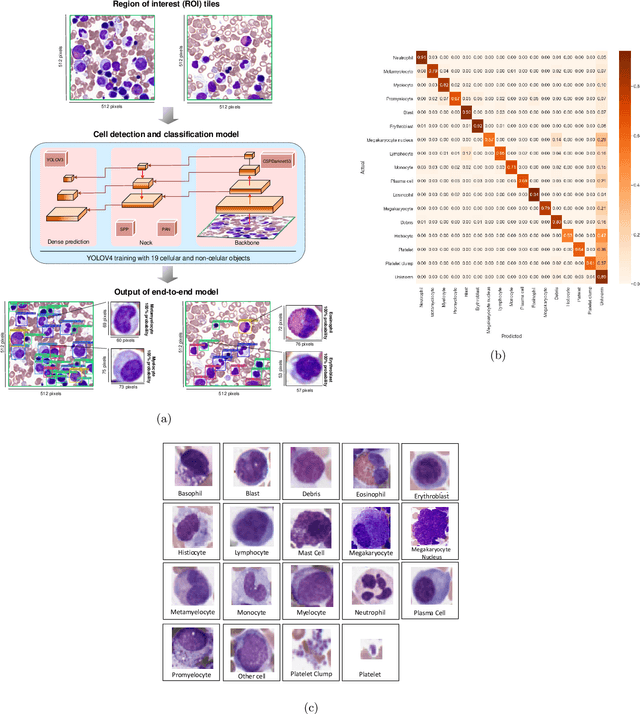
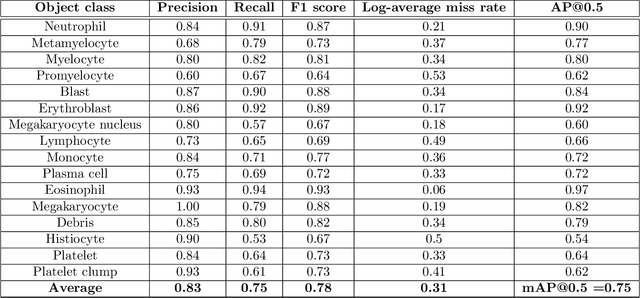
Bone marrow cytology is required to make a hematological diagnosis, influencing critical clinical decision points in hematology. However, bone marrow cytology is tedious, limited to experienced reference centers and associated with high inter-observer variability. This may lead to a delayed or incorrect diagnosis, leaving an unmet need for innovative supporting technologies. We have developed the first ever end-to-end deep learning-based technology for automated bone marrow cytology. Starting with a bone marrow aspirate digital whole slide image, our technology rapidly and automatically detects suitable regions for cytology, and subsequently identifies and classifies all bone marrow cells in each region. This collective cytomorphological information is captured in a novel representation called Histogram of Cell Types (HCT) quantifying bone marrow cell class probability distribution and acting as a cytological "patient fingerprint". The approach achieves high accuracy in region detection (0.97 accuracy and 0.99 ROC AUC), and cell detection and cell classification (0.75 mAP, 0.78 F1-score, Log-average miss rate of 0.31). HCT has potential to revolutionize hematopathology diagnostic workflows, leading to more cost-effective, accurate diagnosis and opening the door to precision medicine.
3D U-NetR: Low Dose Computed Tomography Reconstruction via Deep Learning and 3 Dimensional Convolutions
May 28, 2021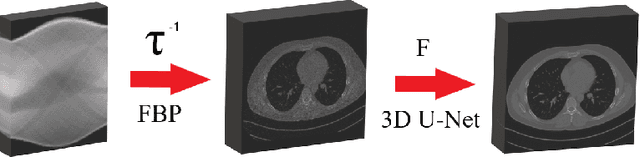
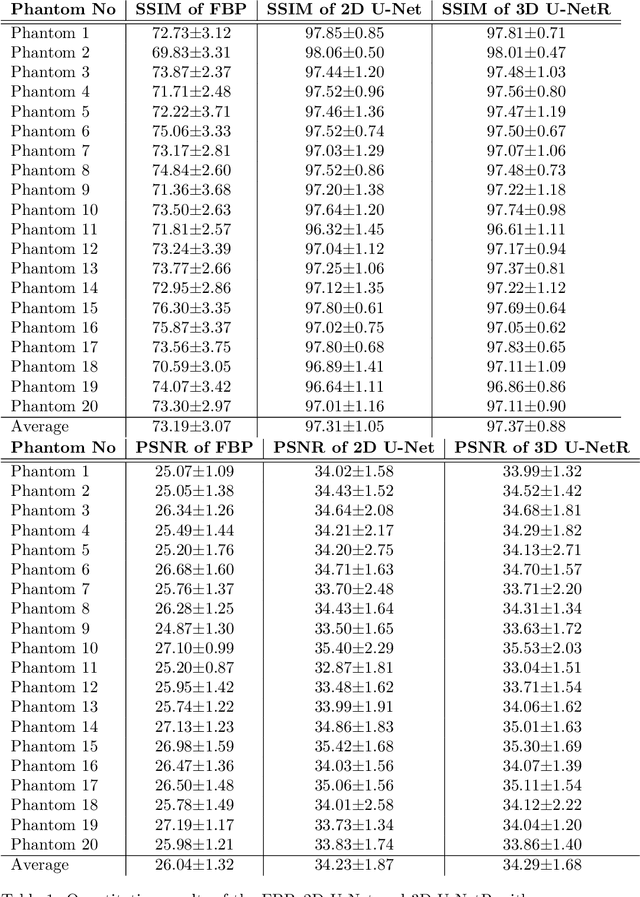
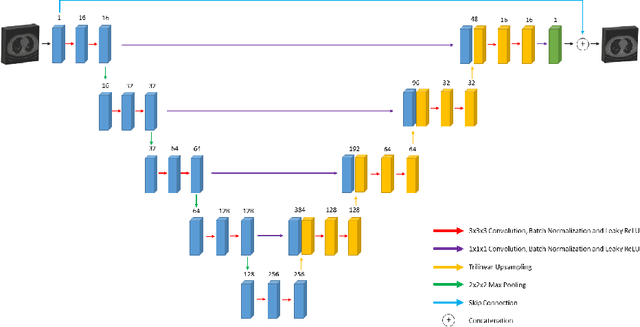
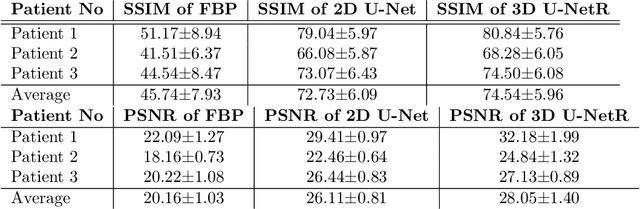
In this paper, we introduced a novel deep learning based reconstruction technique using the correlations of all 3 dimensions with each other by taking into account the correlation between 2-dimensional low-dose CT images. Sparse or noisy sinograms are back projected to the image domain with FBP operation, then denoising process is applied with a U-Net like 3 dimensional network called 3D U-NetR. Proposed network is trained with synthetic and real chest CT images, and 2D U-Net is also trained with the same dataset to prove the importance of the 3rd dimension. Proposed network shows better quantitative performance on SSIM and PSNR. More importantly, 3D U-NetR captures medically critical visual details that cannot be visualized by 2D network.