 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-modal Alignment using Representation Codebook
Mar 03, 2022
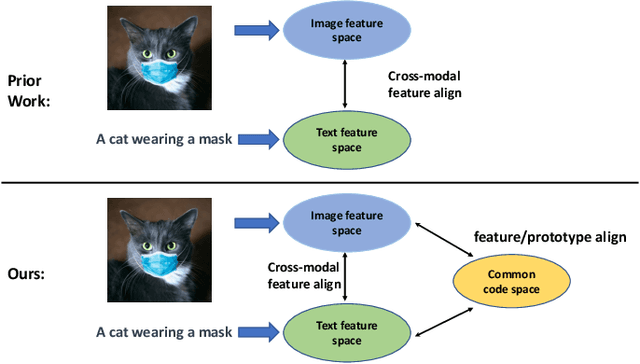
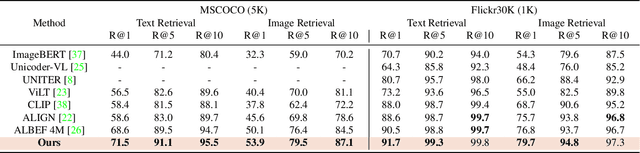
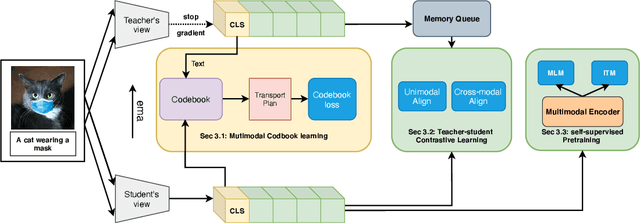
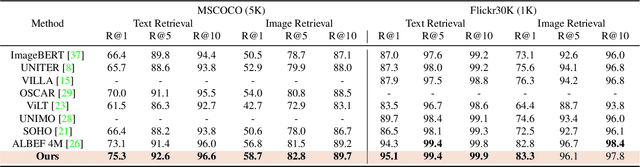
Aligning signals from different modalities is an important step in vision-language representation learning as it affects the performance of later stages such as cross-modality fusion. Since image and text typically reside in different regions of the feature space, directly aligning them at instance level is challenging especially when features are still evolving during training. In this paper, we propose to align at a higher and more stable level using cluster representation. Specifically, we treat image and text as two "views" of the same entity, and encode them into a joint vision-language coding space spanned by a dictionary of cluster centers (codebook). We contrast positive and negative samples via their cluster assignments while simultaneously optimizing the cluster centers. To further smooth out the learning process, we adopt a teacher-student distillation paradigm, where the momentum teacher of one view guides the student learning of the other. We evaluated our approach on common vision language benchmarks and obtain new SoTA on zero-shot cross modality retrieval while being competitive on various other transfer tasks.
Memory-Augmented Reinforcement Learning for Image-Goal Navigation
Jan 13, 2021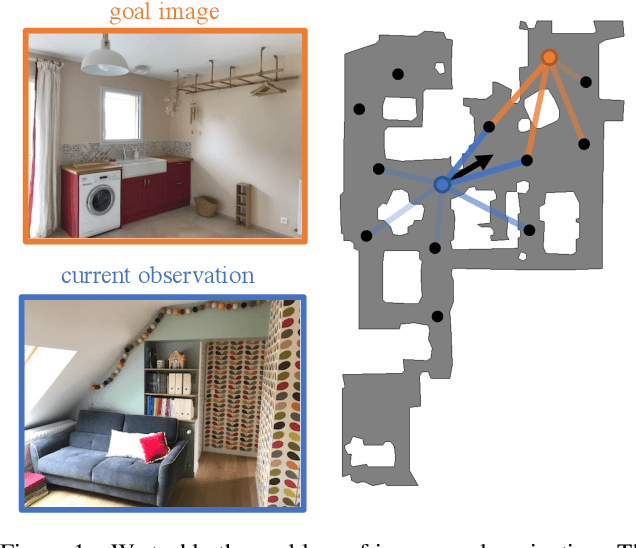
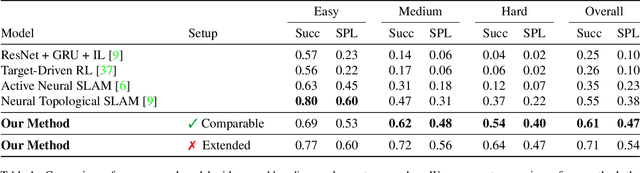
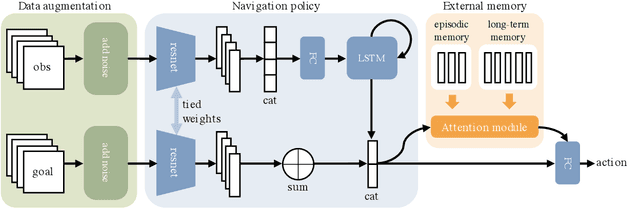
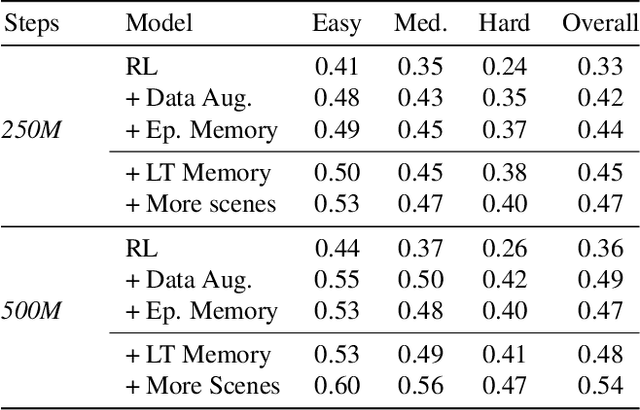
In this work, we address the problem of image-goal navigation in the context of visually-realistic 3D environments. This task involves navigating to a location indicated by a target image in a previously unseen environment. Earlier attempts, including RL-based and SLAM-based approaches, have either shown poor generalization performance, or are heavily-reliant on pose/depth sensors. We present a novel method that leverages a cross-episode memory to learn to navigate. We first train a state-embedding network in a self-supervised fashion, and then use it to embed previously-visited states into a memory. In order to avoid overfitting, we propose to use data augmentation on the RGB input during training. We validate our approach through extensive evaluations, showing that our data-augmented memory-based model establishes a new state of the art on the image-goal navigation task in the challenging Gibson dataset. We obtain this competitive performance from RGB input only, without access to additional sensors such as position or depth.
Free-breathing motion compensated 4D (3D+respiration) T2-weighted turbo spin-echo MRI for body imaging
Feb 07, 2022Purpose: To develop and evaluate a free-breathing respiratory motion compensated 4D (3D+respiration) $T_2$-weighted turbo spin echo sequence with application to radiology and MR-guided radiotherapy. Methods: k-space data are continuously acquired using a rewound Cartesian acquisition with spiral profile ordering (rCASPR) to provide matching contrast to the conventional linear phase encode ordering and to sort data into multiple respiratory phases. Low-resolution respiratory-correlated 4D images were reconstructed with compressed sensing and used to estimate non-rigid deformation vector fields, which were subsequently used for a motion compensated image reconstruction. rCASPR sampling was compared to linear and CASPR sampling in terms of point-spread-function (PSF) and image contrast with in silico, phantom and in vivo experiments. Reconstruction parameters for low-resolution 4D-MRI (spatial resolution and temporal regularization) were determined using a grid search. The proposed motion compensated rCASPR was evaluated in eight healthy volunteers and compared to free-breathing scans with linear sampling. Image quality was compared based on visual inspection and quantitatively by means of the gradient entropy. Results: rCASPR provided a superior PSF (similar in ky and narrower in kz) and showed no considerable differences in images contrast compared to linear sampling. The optimal 4D-MRI reconstruction parameters were spatial resolution=$4.5 mm^3$ and $\lambda_t=10^{-4}$. The groupwise average gradient entropy was 22.31 for linear, 22.20 for rCASPR, 22.14 for soft-gated rCASPR and 22.02 for motion compensated rCASPR. Conclusion: The proposed motion compensated rCASPR enables high quality free-breathing T2-TSE with minimal changes in image contrast and scan time. The proposed method therefore enables direct transfer of clinically used 3D TSE sequences to free-breathing.
Learning Semantic Person Image Generation by Region-Adaptive Normalization
Apr 14, 2021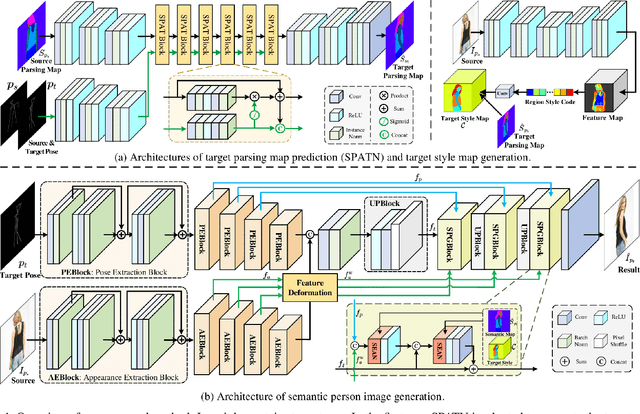
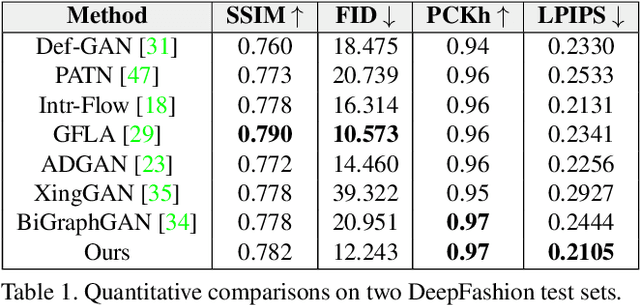
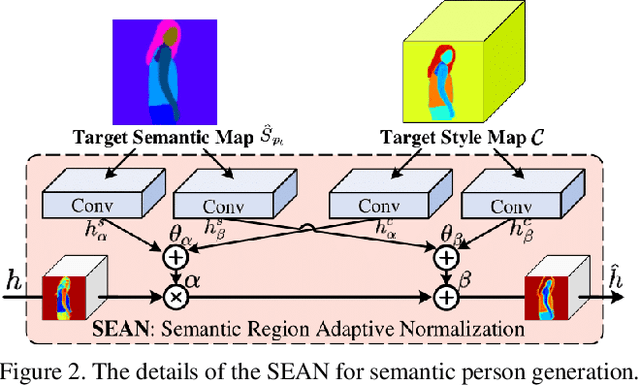

Human pose transfer has received great attention due to its wide applications, yet is still a challenging task that is not well solved. Recent works have achieved great success to transfer the person image from the source to the target pose. However, most of them cannot well capture the semantic appearance, resulting in inconsistent and less realistic textures on the reconstructed results. To address this issue, we propose a new two-stage framework to handle the pose and appearance translation. In the first stage, we predict the target semantic parsing maps to eliminate the difficulties of pose transfer and further benefit the latter translation of per-region appearance style. In the second one, with the predicted target semantic maps, we suggest a new person image generation method by incorporating the region-adaptive normalization, in which it takes the per-region styles to guide the target appearance generation. Extensive experiments show that our proposed SPGNet can generate more semantic, consistent, and photo-realistic results and perform favorably against the state of the art methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SPGNet.git.
HDR Reconstruction from Bracketed Exposures and Events
Mar 28, 2022
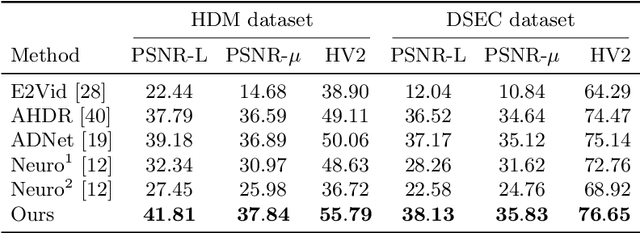
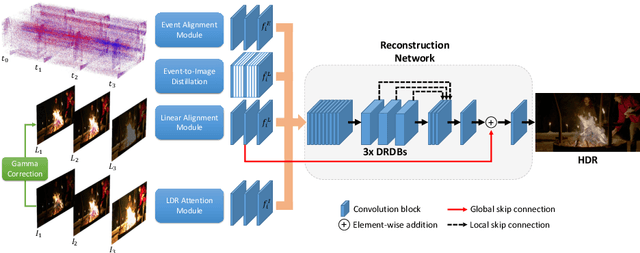
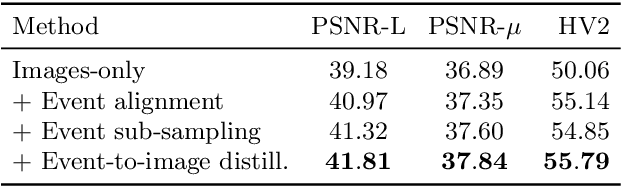
Reconstruction of high-quality HDR images is at the core of modern computational photography. Significant progress has been made with multi-frame HDR reconstruction methods, producing high-resolution, rich and accurate color reconstructions with high-frequency details. However, they are still prone to fail in dynamic or largely over-exposed scenes, where frame misalignment often results in visible ghosting artifacts. Recent approaches attempt to alleviate this by utilizing an event-based camera (EBC), which measures only binary changes of illuminations. Despite their desirable high temporal resolution and dynamic range characteristics, such approaches have not outperformed traditional multi-frame reconstruction methods, mainly due to the lack of color information and low-resolution sensors. In this paper, we propose to leverage both bracketed LDR images and simultaneously captured events to obtain the best of both worlds: high-quality RGB information from bracketed LDRs and complementary high frequency and dynamic range information from events. We present a multi-modal end-to-end learning-based HDR imaging system that fuses bracketed images and event modalities in the feature domain using attention and multi-scale spatial alignment modules. We propose a novel event-to-image feature distillation module that learns to translate event features into the image-feature space with self-supervision. Our framework exploits the higher temporal resolution of events by sub-sampling the input event streams using a sliding window, enriching our combined feature representation. Our proposed approach surpasses SoTA multi-frame HDR reconstruction methods using synthetic and real events, with a 2dB and 1dB improvement in PSNR-L and PSNR-mu on the HdM HDR dataset, respectively.
Barlow constrained optimization for Visual Question Answering
Mar 07, 2022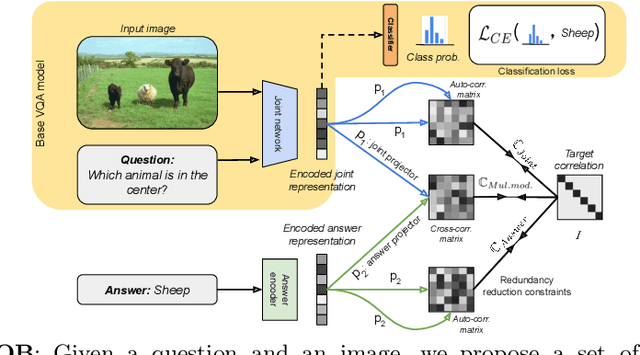
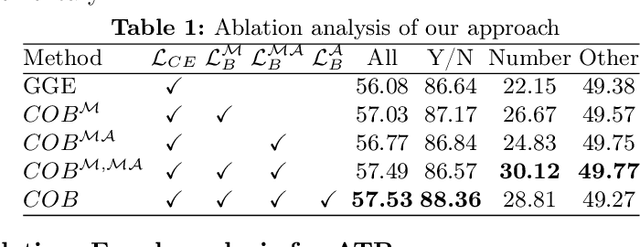
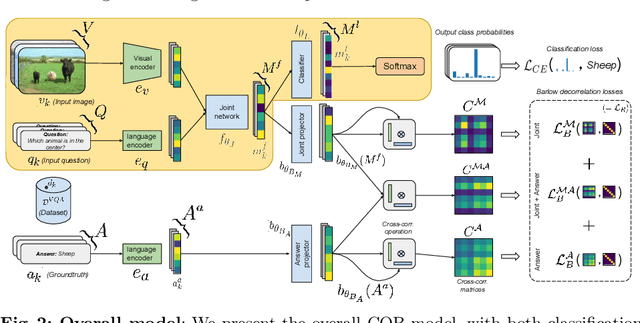
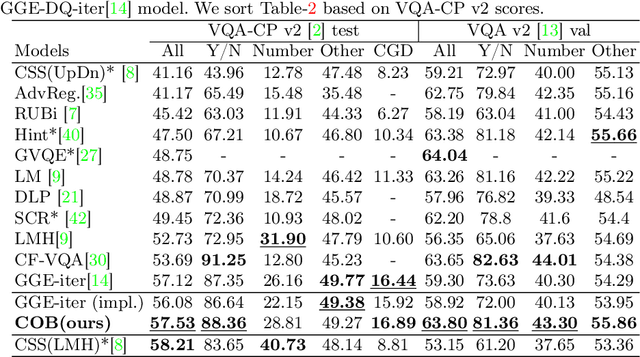
Visual question answering is a vision-and-language multimodal task, that aims at predicting answers given samples from the question and image modalities. Most recent methods focus on learning a good joint embedding space of images and questions, either by improving the interaction between these two modalities, or by making it a more discriminant space. However, how informative this joint space is, has not been well explored. In this paper, we propose a novel regularization for VQA models, Constrained Optimization using Barlow's theory (COB), that improves the information content of the joint space by minimizing the redundancy. It reduces the correlation between the learned feature components and thereby disentangles semantic concepts. Our model also aligns the joint space with the answer embedding space, where we consider the answer and image+question as two different `views' of what in essence is the same semantic information. We propose a constrained optimization policy to balance the categorical and redundancy minimization forces. When built on the state-of-the-art GGE model, the resulting model improves VQA accuracy by 1.4% and 4% on the VQA-CP v2 and VQA v2 datasets respectively. The model also exhibits better interpretability.
DocSegTr: An Instance-Level End-to-End Document Image Segmentation Transformer
Jan 27, 2022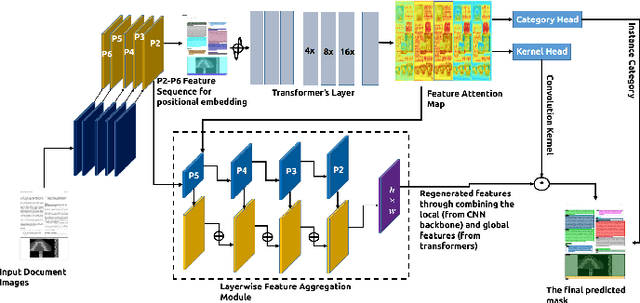
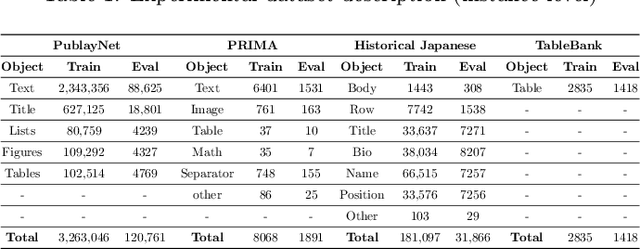

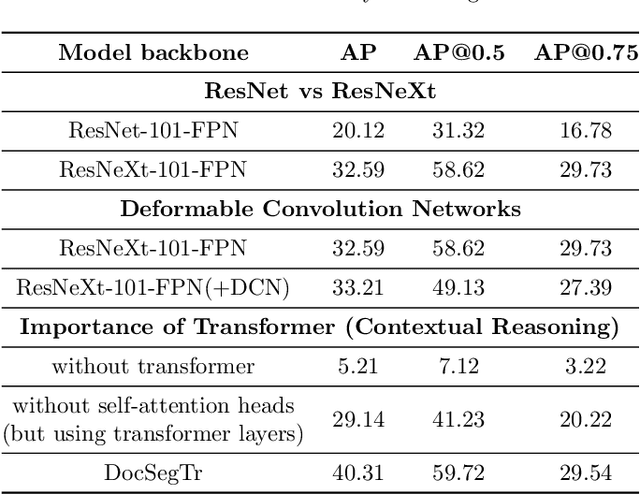
Understanding documents with rich layouts is an essential step towards information extraction. Business intelligence processes often require the extraction of useful semantic content from documents at a large scale for subsequent decision-making tasks. In this context, instance-level segmentation of different document objects(title, sections, figures, tables and so on) has emerged as an interesting problem for the document layout analysis community. To advance the research in this direction, we present a transformer-based model for end-to-end segmentation of complex layouts in document images. To our knowledge, this is the first work on transformer-based document segmentation. Extensive experimentation on the PubLayNet dataset shows that our model achieved comparable or better segmentation performance than the existing state-of-the-art approaches. We hope our simple and flexible framework could serve as a promising baseline for instance-level recognition tasks in document images.
Dual Branch Neural Network for Sea Fog Detection in Geostationary Ocean Color Imager
May 04, 2022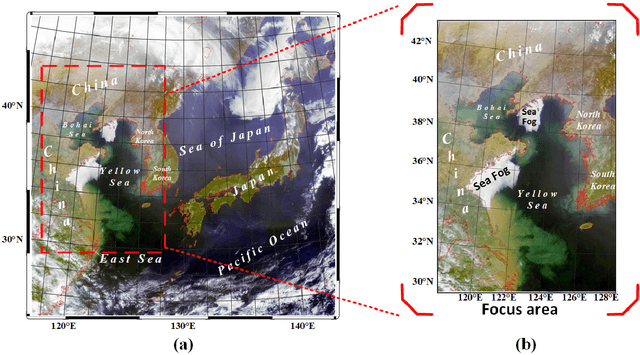
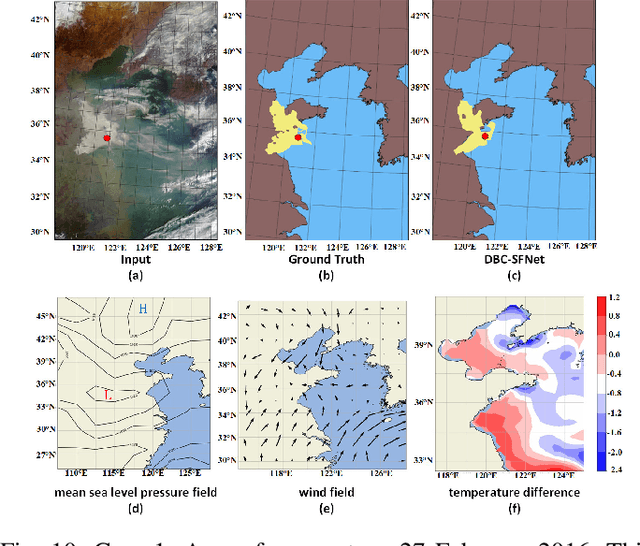
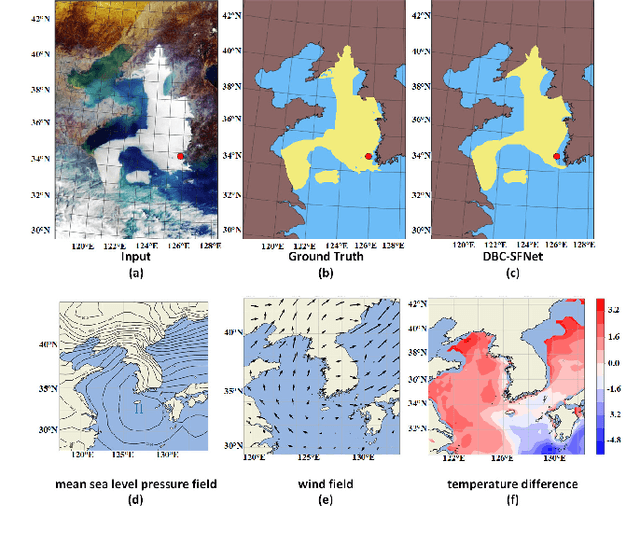
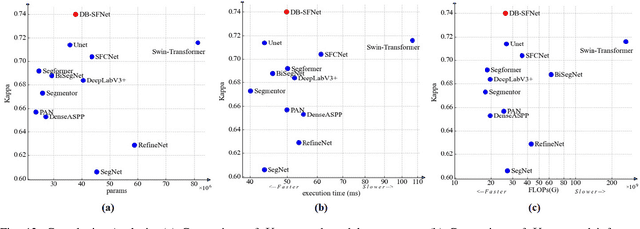
Sea fog significantly threatens the safety of maritime activities. This paper develops a sea fog dataset (SFDD) and a dual branch sea fog detection network (DB-SFNet). We investigate all the observed sea fog events in the Yellow Sea and the Bohai Sea (118.1{\deg}E-128.1{\deg}E, 29.5{\deg}N-43.8{\deg}N) from 2010 to 2020, and collect the sea fog images for each event from the Geostationary Ocean Color Imager (GOCI) to comprise the dataset SFDD. The location of the sea fog in each image in SFDD is accurately marked. The proposed dataset is characterized by a long-time span, large number of samples, and accurate labeling, that can substantially improve the robustness of various sea fog detection models. Furthermore, this paper proposes a dual branch sea fog detection network to achieve accurate and holistic sea fog detection. The poporsed DB-SFNet is composed of a knowledge extraction module and a dual branch optional encoding decoding module. The two modules jointly extracts discriminative features from both visual and statistical domain. Experiments show promising sea fog detection results with an F1-score of 0.77 and a critical success index of 0.63. Compared with existing advanced deep learning networks, DB-SFNet is superior in detection performance and stability, particularly in the mixed cloud and fog areas.
Perceptual Image Restoration with High-Quality Priori and Degradation Learning
Mar 04, 2021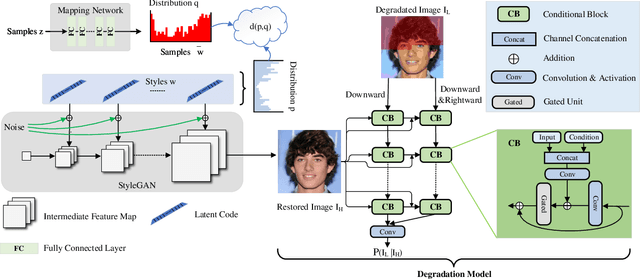

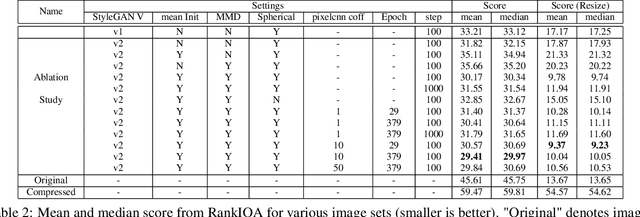
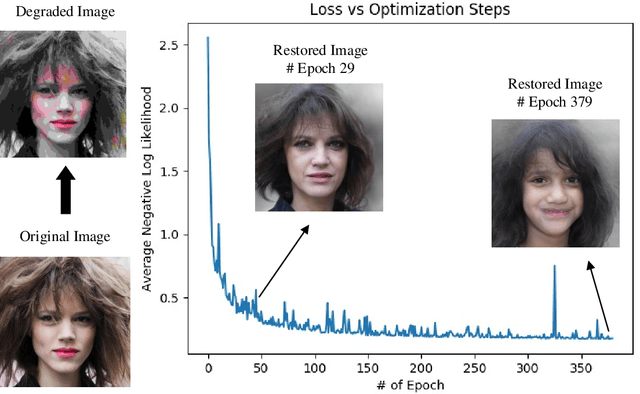
Perceptual image restoration seeks for high-fidelity images that most likely degrade to given images. For better visual quality, previous work proposed to search for solutions within the natural image manifold, by exploiting the latent space of a generative model. However, the quality of generated images are only guaranteed when latent embedding lies close to the prior distribution. In this work, we propose to restrict the feasible region within the prior manifold. This is accomplished with a non-parametric metric for two distributions: the Maximum Mean Discrepancy (MMD). Moreover, we model the degradation process directly as a conditional distribution. We show that our model performs well in measuring the similarity between restored and degraded images. Instead of optimizing the long criticized pixel-wise distance over degraded images, we rely on such model to find visual pleasing images with high probability. Our simultaneous restoration and enhancement framework generalizes well to real-world complicated degradation types. The experimental results on perceptual quality and no-reference image quality assessment (NR-IQA) demonstrate the superior performance of our method.
Review on Panoramic Imaging and Its Applications in Scene Understanding
May 11, 2022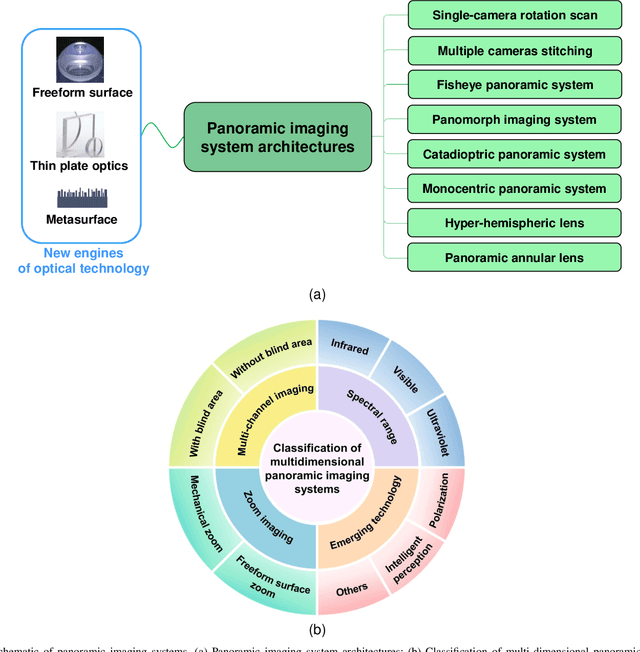

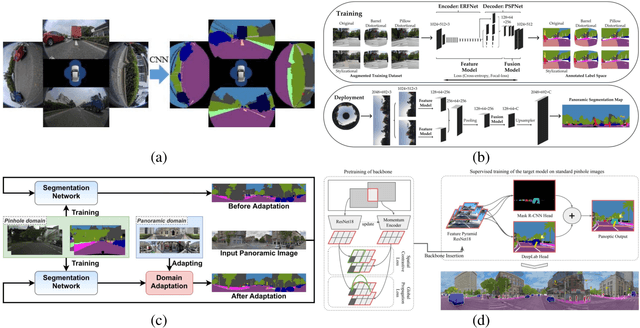
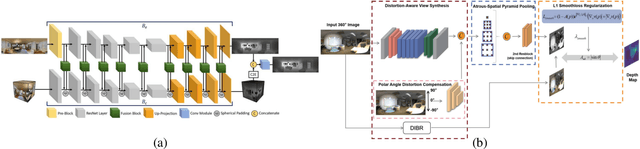
With the rapid development of high-speed communication and artificial intelligence technologies, human perception of real-world scenes is no longer limited to the use of small Field of View (FoV) and low-dimensional scene detection devices. Panoramic imaging emerges as the next generation of innovative intelligent instruments for environmental perception and measurement. However, while satisfying the need for large-FoV photographic imaging, panoramic imaging instruments are expected to have high resolution, no blind area, miniaturization, and multi-dimensional intelligent perception, and can be combined with artificial intelligence methods towards the next generation of intelligent instruments, enabling deeper understanding and more holistic perception of 360-degree real-world surrounding environments. Fortunately, recent advances in freeform surfaces, thin-plate optics, and metasurfaces provide innovative approaches to address human perception of the environment, offering promising ideas beyond conventional optical imaging. In this review, we begin with introducing the basic principles of panoramic imaging systems, and then describe the architectures, features, and functions of various panoramic imaging systems. Afterwards, we discuss in detail the broad application prospects and great design potential of freeform surfaces, thin-plate optics, and metasurfaces in panoramic imaging. We then provide a detailed analysis on how these techniques can help enhance the performance of panoramic imaging systems. We further offer a detailed analysis of applications of panoramic imaging in scene understanding for autonomous driving and robotics, spanning panoramic semantic image segmentation, panoramic depth estimation, panoramic visual localization, and so on. Finally, we cast a perspective on future potential and research directions for panoramic imaging instruments.