 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Synthetic to Real: Image Dehazing Collaborating with Unlabeled Real Data
Aug 06, 2021
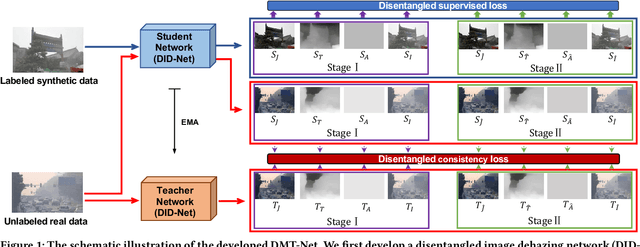
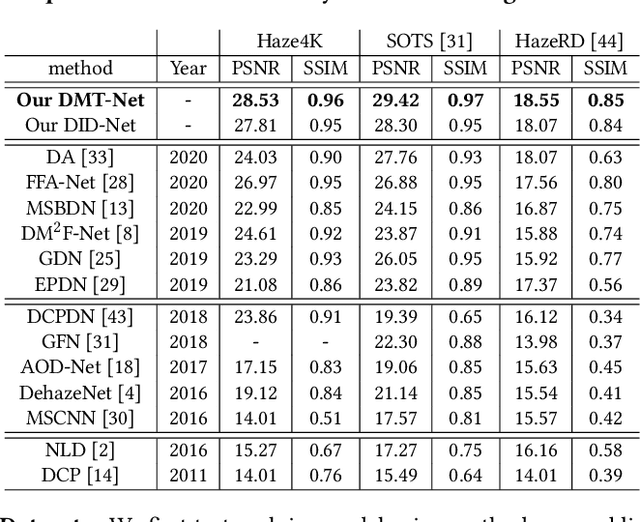
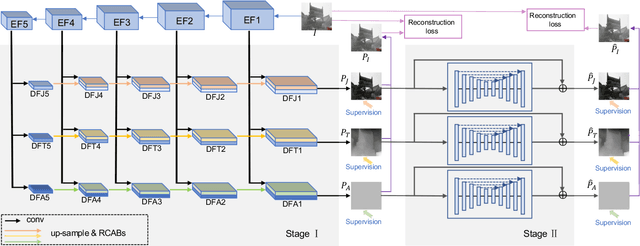
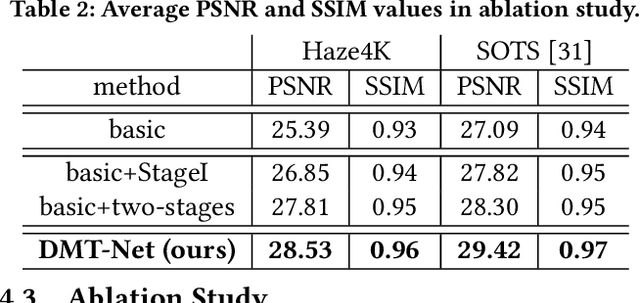
Single image dehazing is a challenging task, for which the domain shift between synthetic training data and real-world testing images usually leads to degradation of existing methods. To address this issue, we propose a novel image dehazing framework collaborating with unlabeled real data. First, we develop a disentangled image dehazing network (DID-Net), which disentangles the feature representations into three component maps, i.e. the latent haze-free image, the transmission map, and the global atmospheric light estimate, respecting the physical model of a haze process. Our DID-Net predicts the three component maps by progressively integrating features across scales, and refines each map by passing an independent refinement network. Then a disentangled-consistency mean-teacher network (DMT-Net) is employed to collaborate unlabeled real data for boosting single image dehazing. Specifically, we encourage the coarse predictions and refinements of each disentangled component to be consistent between the student and teacher networks by using a consistency loss on unlabeled real data. We make comparison with 13 state-of-the-art dehazing methods on a new collected dataset (Haze4K) and two widely-used dehazing datasets (i.e., SOTS and HazeRD), as well as on real-world hazy images. Experimental results demonstrate that our method has obvious quantitative and qualitative improvements over the existing methods.
Multimodal Transformer for Automatic 3D Annotation and Object Detection
Jul 20, 2022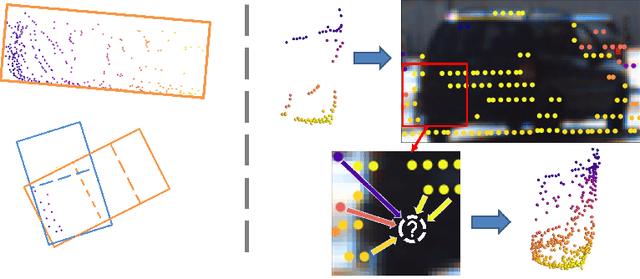
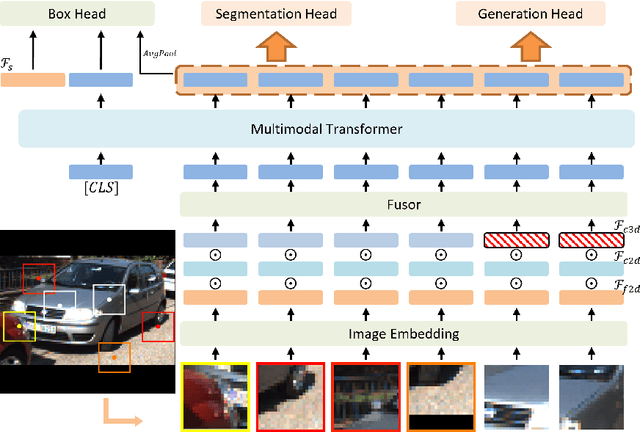
Despite a growing number of datasets being collected for training 3D object detection models, significant human effort is still required to annotate 3D boxes on LiDAR scans. To automate the annotation and facilitate the production of various customized datasets, we propose an end-to-end multimodal transformer (MTrans) autolabeler, which leverages both LiDAR scans and images to generate precise 3D box annotations from weak 2D bounding boxes. To alleviate the pervasive sparsity problem that hinders existing autolabelers, MTrans densifies the sparse point clouds by generating new 3D points based on 2D image information. With a multi-task design, MTrans segments the foreground/background, densifies LiDAR point clouds, and regresses 3D boxes simultaneously. Experimental results verify the effectiveness of the MTrans for improving the quality of the generated labels. By enriching the sparse point clouds, our method achieves 4.48\% and 4.03\% better 3D AP on KITTI moderate and hard samples, respectively, versus the state-of-the-art autolabeler. MTrans can also be extended to improve the accuracy for 3D object detection, resulting in a remarkable 89.45\% AP on KITTI hard samples. Codes are at \url{https://github.com/Cliu2/MTrans}.
A Thorough Review on Recent Deep Learning Methodologies for Image Captioning
Jul 28, 2021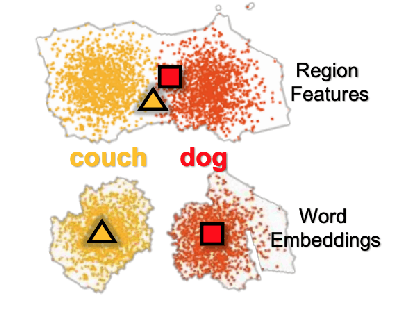
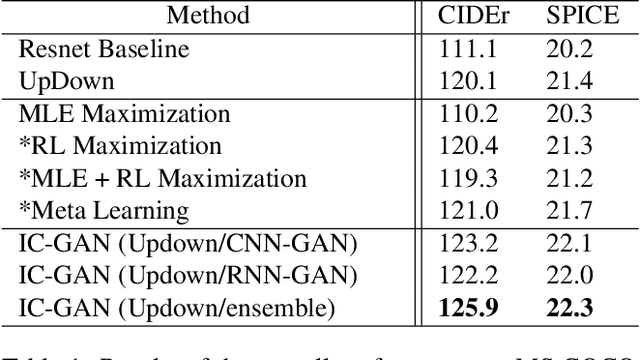
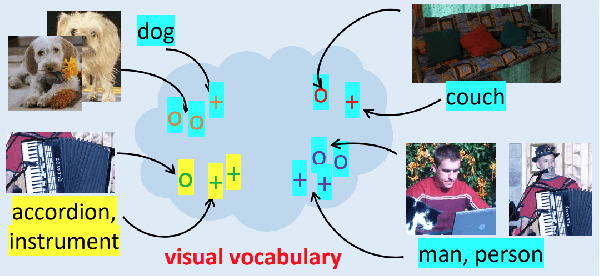
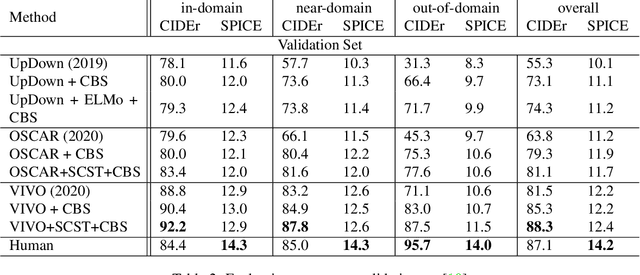
Image Captioning is a task that combines computer vision and natural language processing, where it aims to generate descriptive legends for images. It is a two-fold process relying on accurate image understanding and correct language understanding both syntactically and semantically. It is becoming increasingly difficult to keep up with the latest research and findings in the field of image captioning due to the growing amount of knowledge available on the topic. There is not, however, enough coverage of those findings in the available review papers. We perform in this paper a run-through of the current techniques, datasets, benchmarks and evaluation metrics used in image captioning. The current research on the field is mostly focused on deep learning-based methods, where attention mechanisms along with deep reinforcement and adversarial learning appear to be in the forefront of this research topic. In this paper, we review recent methodologies such as UpDown, OSCAR, VIVO, Meta Learning and a model that uses conditional generative adversarial nets. Although the GAN-based model achieves the highest score, UpDown represents an important basis for image captioning and OSCAR and VIVO are more useful as they use novel object captioning. This review paper serves as a roadmap for researchers to keep up to date with the latest contributions made in the field of image caption generation.
PROTOtypical Logic Tensor Networks (PROTO-LTN) for Zero Shot Learning
Jun 26, 2022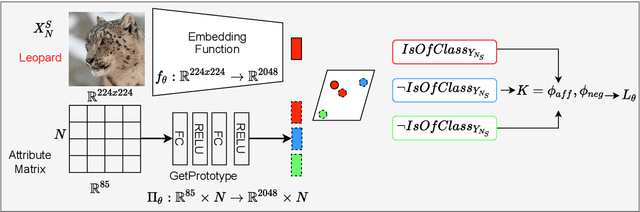

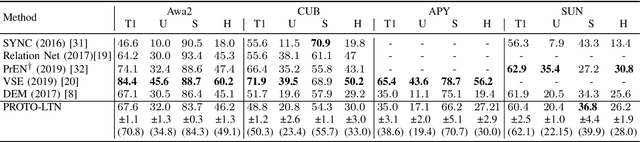
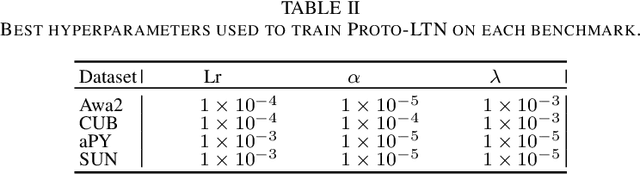
Semantic image interpretation can vastly benefit from approaches that combine sub-symbolic distributed representation learning with the capability to reason at a higher level of abstraction. Logic Tensor Networks (LTNs) are a class of neuro-symbolic systems based on a differentiable, first-order logic grounded into a deep neural network. LTNs replace the classical concept of training set with a knowledge base of fuzzy logical axioms. By defining a set of differentiable operators to approximate the role of connectives, predicates, functions and quantifiers, a loss function is automatically specified so that LTNs can learn to satisfy the knowledge base. We focus here on the subsumption or \texttt{isOfClass} predicate, which is fundamental to encode most semantic image interpretation tasks. Unlike conventional LTNs, which rely on a separate predicate for each class (e.g., dog, cat), each with its own set of learnable weights, we propose a common \texttt{isOfClass} predicate, whose level of truth is a function of the distance between an object embedding and the corresponding class prototype. The PROTOtypical Logic Tensor Networks (PROTO-LTN) extend the current formulation by grounding abstract concepts as parametrized class prototypes in a high-dimensional embedding space, while reducing the number of parameters required to ground the knowledge base. We show how this architecture can be effectively trained in the few and zero-shot learning scenarios. Experiments on Generalized Zero Shot Learning benchmarks validate the proposed implementation as a competitive alternative to traditional embedding-based approaches. The proposed formulation opens up new opportunities in zero shot learning settings, as the LTN formalism allows to integrate background knowledge in the form of logical axioms to compensate for the lack of labelled examples.
Physics-Inspired Unsupervised Classification for Region of Interest in X-Ray Ptychography
Jun 29, 2022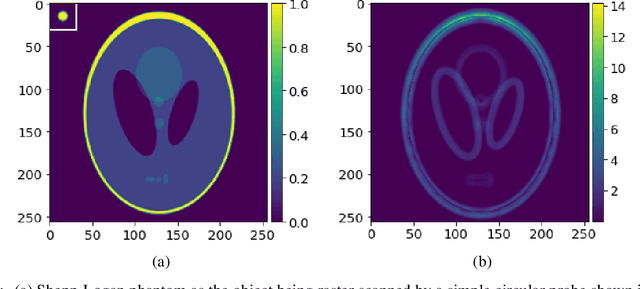
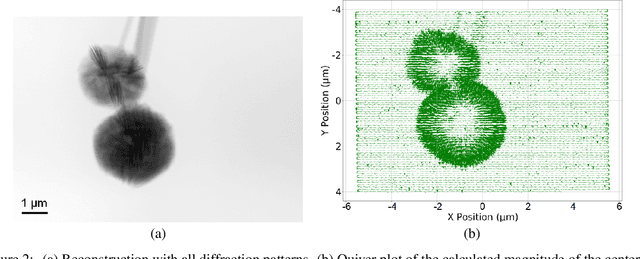
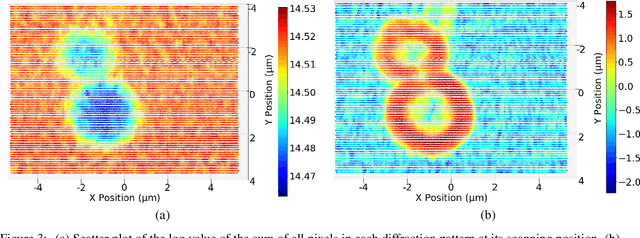
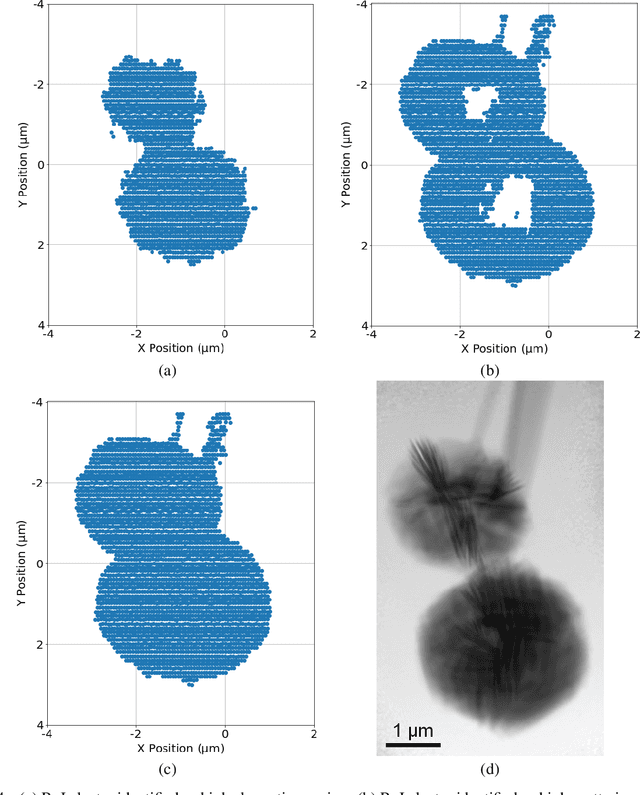
X-ray ptychography allows for large fields to be imaged at high resolution at the cost of additional computational expense due to the large volume of data. Given limited information regarding the object, the acquired data often has an excessive amount of information that is outside the region of interest (RoI). In this work we propose a physics-inspired unsupervised learning algorithm to identify the RoI of an object using only diffraction patterns from a ptychography dataset before committing computational resources to reconstruction. Obtained diffraction patterns that are automatically identified as not within the RoI are filtered out, allowing efficient reconstruction by focusing only on important data within the RoI while preserving image quality.
Combining Attention with Flow for Person Image Synthesis
Aug 04, 2021

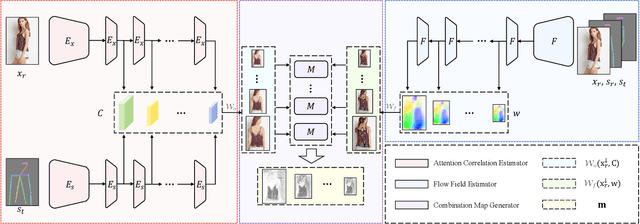
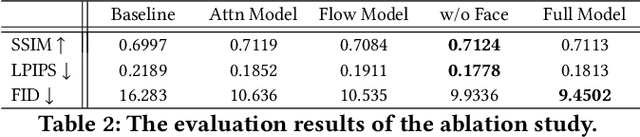
Pose-guided person image synthesis aims to synthesize person images by transforming reference images into target poses. In this paper, we observe that the commonly used spatial transformation blocks have complementary advantages. We propose a novel model by combining the attention operation with the flow-based operation. Our model not only takes the advantage of the attention operation to generate accurate target structures but also uses the flow-based operation to sample realistic source textures. Both objective and subjective experiments demonstrate the superiority of our model. Meanwhile, comprehensive ablation studies verify our hypotheses and show the efficacy of the proposed modules. Besides, additional experiments on the portrait image editing task demonstrate the versatility of the proposed combination.
NTIRE 2021 Challenge on Image Deblurring
Apr 30, 2021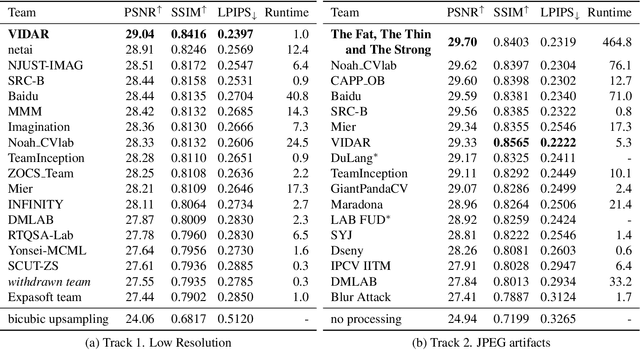


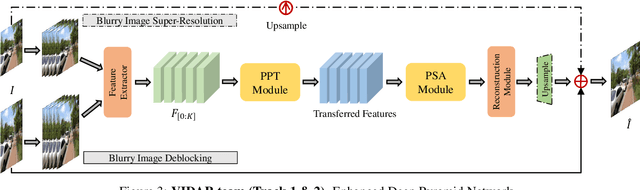
Motion blur is a common photography artifact in dynamic environments that typically comes jointly with the other types of degradation. This paper reviews the NTIRE 2021 Challenge on Image Deblurring. In this challenge report, we describe the challenge specifics and the evaluation results from the 2 competition tracks with the proposed solutions. While both the tracks aim to recover a high-quality clean image from a blurry image, different artifacts are jointly involved. In track 1, the blurry images are in a low resolution while track 2 images are compressed in JPEG format. In each competition, there were 338 and 238 registered participants and in the final testing phase, 18 and 17 teams competed. The winning methods demonstrate the state-of-the-art performance on the image deblurring task with the jointly combined artifacts.
MaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining
Jun 01, 2022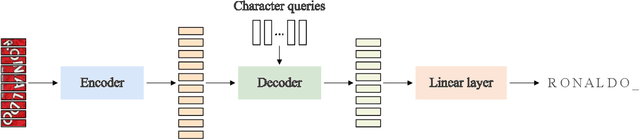


In this paper, we present a model pretraining technique, named MaskOCR, for text recognition. Our text recognition architecture is an encoder-decoder transformer: the encoder extracts the patch-level representations, and the decoder recognizes the text from the representations. Our approach pretrains both the encoder and the decoder in a sequential manner. (i) We pretrain the encoder in a self-supervised manner over a large set of unlabeled real text images. We adopt the masked image modeling approach, which shows the effectiveness for general images, expecting that the representations take on semantics. (ii) We pretrain the decoder over a large set of synthesized text images in a supervised manner and enhance the language modeling capability of the decoder by randomly masking some text image patches occupied by characters input to the encoder and accordingly the representations input to the decoder. Experiments show that the proposed MaskOCR approach achieves superior results on the benchmark datasets, including Chinese and English text images.
Corrosion Detection for Industrial Objects: From Multi-Sensor System to 5D Feature Space
May 14, 2022
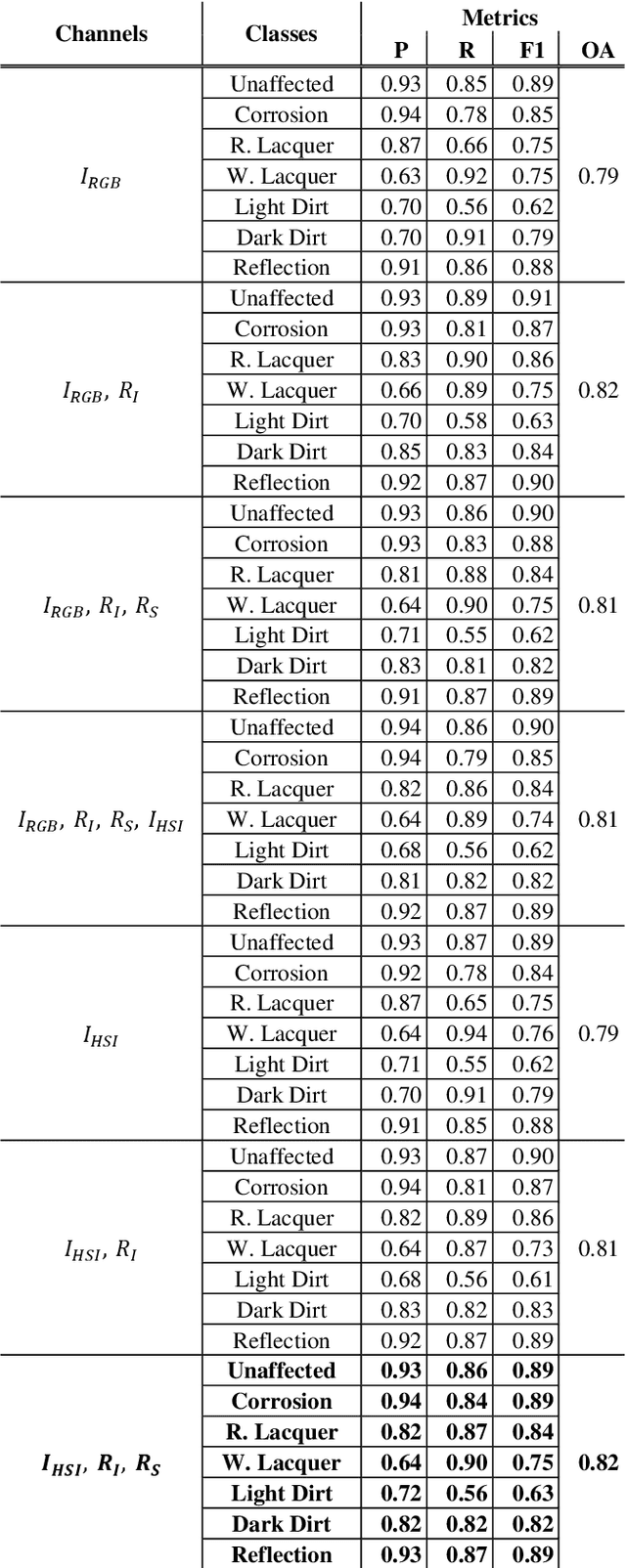

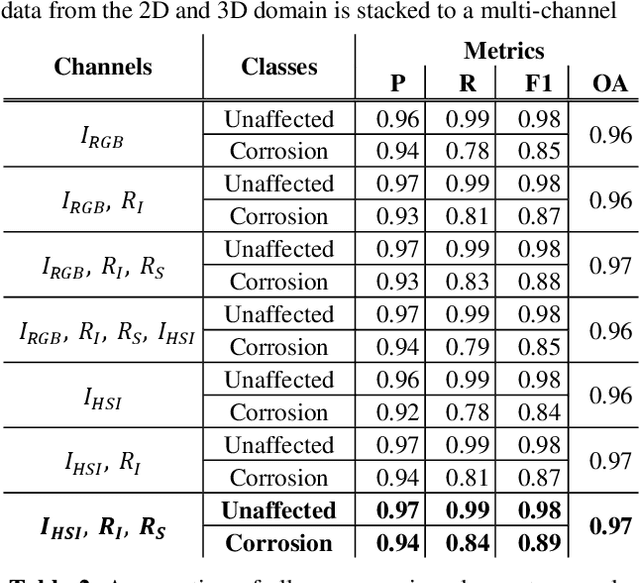
Corrosion is a form of damage that often appears on the surface of metal-made objects used in industrial applications. Those damages can be critical depending on the purpose of the used object. Optical-based testing systems provide a form of non-contact data acquisition, where the acquired data can then be used to analyse the surface of an object. In the field of industrial image processing, this is called surface inspection. We provide a testing setup consisting of a rotary table which rotates the object by 360 degrees, as well as industrial RGB cameras and laser triangulation sensors for the acquisition of 2D and 3D data as our multi-sensor system. These sensors acquire data while the object to be tested takes a full rotation. Further on, data augmentation is applied to prepare new data or enhance already acquired data. In order to evaluate the impact of a laser triangulation sensor for corrosion detection, one challenge is to at first fuse the data of both domains. After the data fusion process, 5 different channels can be utilized to create a 5D feature space. Besides the red, green and blue channels of the image (1-3), additional range data from the laser triangulation sensor is incorporated (4). As a fifth channel, said sensor provides additional intensity data (5). With a multi-channel image classification, a 5D feature space will lead to slightly superior results opposed to a 3D feature space, composed of only the RGB channels of the image.
SDNet: mutil-branch for single image deraining using swin
May 31, 2021
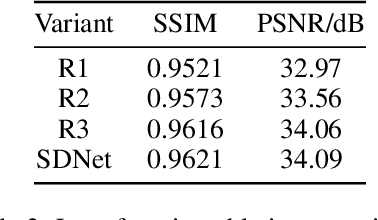
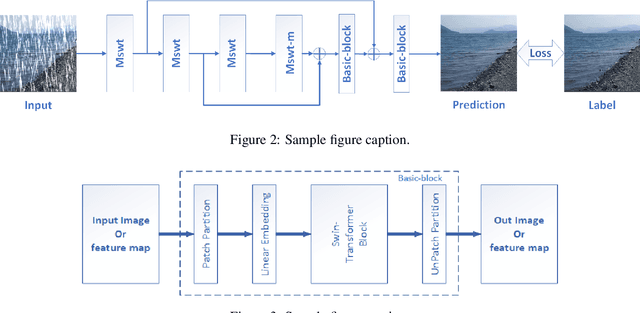
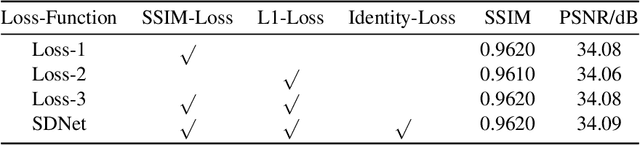
Rain streaks degrade the image quality and seriously affect the performance of subsequent computer vision tasks, such as autonomous driving, social security, etc. Therefore, removing rain streaks from a given rainy images is of great significance. Convolutional neural networks(CNN) have been widely used in image deraining tasks, however, the local computational characteristics of convolutional operations limit the development of image deraining tasks. Recently, the popular transformer has global computational features that can further facilitate the development of image deraining tasks. In this paper, we introduce Swin-transformer into the field of image deraining for the first time to study the performance and potential of Swin-transformer in the field of image deraining. Specifically, we improve the basic module of Swin-transformer and design a three-branch model to implement single-image rain removal. The former implements the basic rain pattern feature extraction, while the latter fuses different features to further extract and process the image features. In addition, we employ a jump connection to fuse deep features and shallow features. In terms of experiments, the existing public dataset suffers from image duplication and relatively homogeneous background. So we propose a new dataset Rain3000 to validate our model. Therefore, we propose a new dataset Rain3000 for validating our model. Experimental results on the publicly available datasets Rain100L, Rain100H and our dataset Rain3000 show that our proposed method has performance and inference speed advantages over the current mainstream single-image rain streaks removal models.The source code will be available at https://github.com/H-tfx/SDNet.