 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBathyFacto: Refraction-Aware Two-Media Neural Radiance Fields for Bathymetry
May 11, 2026Through-water photogrammetry based on UAV imagery enables shallow-water bathymetry, but refraction at the air-water interface violates the straight-ray assumption of Structure-from-Motion and causes systematic depth bias. We present BathyFacto, a refraction-aware two-media extension of Nerfacto integrated into Nerfstudio that targets metrically precise underwater point clouds. BathyFacto uses a shared hash-grid-based density field with a medium-conditioned color head that receives a one-bit medium flag (air or water) and traces each camera ray as two segments: a straight segment in air up to a planar water surface and a refracted segment in water computed via Snell's law with known refractive indices. To allocate samples efficiently across the air-water boundary, we employ a single proposal-network sampler that operates on a virtual straight ray spanning both media, combined with a kinked density wrapper that transparently corrects water-segment positions along the refracted direction before density evaluation. A data adaptation pipeline converts photogrammetric reconstructions to a Nerfstudio-compatible format, estimates the water plane from boundary markers, and provides per-pixel medium masks to gate refraction. We also extend the point cloud export with refraction-corrected backprojection and reversible coordinate transforms to world and global frames. On a simulated two-media scene with known ground truth, BathyFacto with refraction achieves a Cloud-to-Mesh mean distance of 0.06 m and 87 % completeness, compared to 0.52 m / 29 % for the Nerfacto baseline and 0.36 m / 21% for conventional MVS without refraction correction.
GS4City: Hierarchical Semantic Gaussian Splatting via City-Model Priors
Apr 13, 2026Recent semantic 3D Gaussian Splatting (3DGS) methods primarily rely on 2D foundation models, often yielding ambiguous boundaries and limited support for structured urban semantics. While city models such as CityGML encode hierarchically organized semantics together with building geometry, these labels cannot be directly mapped to Gaussian primitives. We present GS4City, a hierarchical semantic Gaussian Splatting method that incorporates city-model priors for urban scene understanding. GS4City derives reliable image-aligned masks from Level of Detail (LoD) 3 CityGML models via two-pass raycasting, explicitly using parent-child relations to validate and recover fine-grained facade elements. It then fuses these geometry-grounded masks with foundation-model predictions to establish scene-consistent instance correspondences, and learns a compact identity encoding for each Gaussian under joint 2D identity supervision and 3D spatial regularization. Experiments on the TUM2TWIN and Gold Coast datasets show that GS4City effectively incorporates structured building semantics into Gaussian scene representations, outperforming existing 2D-driven semantic 3DGS baselines, including LangSplat and Gaga, by up to 15.8 IoU points in coarse building segmentation and 14.2 mIoU points in fine-grained semantic segmentation. By bridging structured city models and photorealistic Gaussian scene representations, GS4City enables semantically queryable and structure-aware urban reconstruction. Code is available at https://github.com/Jinyzzz/GS4City.
GS4Buildings: Prior-Guided Gaussian Splatting for 3D Building Reconstruction
Aug 10, 2025
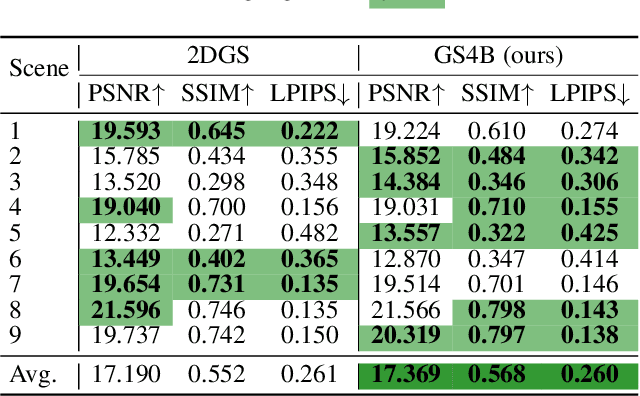
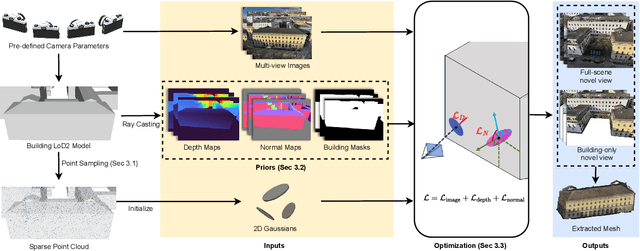

Recent advances in Gaussian Splatting (GS) have demonstrated its effectiveness in photo-realistic rendering and 3D reconstruction. Among these, 2D Gaussian Splatting (2DGS) is particularly suitable for surface reconstruction due to its flattened Gaussian representation and integrated normal regularization. However, its performance often degrades in large-scale and complex urban scenes with frequent occlusions, leading to incomplete building reconstructions. We propose GS4Buildings, a novel prior-guided Gaussian Splatting method leveraging the ubiquity of semantic 3D building models for robust and scalable building surface reconstruction. Instead of relying on traditional Structure-from-Motion (SfM) pipelines, GS4Buildings initializes Gaussians directly from low-level Level of Detail (LoD)2 semantic 3D building models. Moreover, we generate prior depth and normal maps from the planar building geometry and incorporate them into the optimization process, providing strong geometric guidance for surface consistency and structural accuracy. We also introduce an optional building-focused mode that limits reconstruction to building regions, achieving a 71.8% reduction in Gaussian primitives and enabling a more efficient and compact representation. Experiments on urban datasets demonstrate that GS4Buildings improves reconstruction completeness by 20.5% and geometric accuracy by 32.8%. These results highlight the potential of semantic building model integration to advance GS-based reconstruction toward real-world urban applications such as smart cities and digital twins. Our project is available: https://github.com/zqlin0521/GS4Buildings.
To Glue or Not to Glue? Classical vs Learned Image Matching for Mobile Mapping Cameras to Textured Semantic 3D Building Models
May 23, 2025



Feature matching is a necessary step for many computer vision and photogrammetry applications such as image registration, structure-from-motion, and visual localization. Classical handcrafted methods such as SIFT feature detection and description combined with nearest neighbour matching and RANSAC outlier removal have been state-of-the-art for mobile mapping cameras. With recent advances in deep learning, learnable methods have been introduced and proven to have better robustness and performance under complex conditions. Despite their growing adoption, a comprehensive comparison between classical and learnable feature matching methods for the specific task of semantic 3D building camera-to-model matching is still missing. This submission systematically evaluates the effectiveness of different feature-matching techniques in visual localization using textured CityGML LoD2 models. We use standard benchmark datasets (HPatches, MegaDepth-1500) and custom datasets consisting of facade textures and corresponding camera images (terrestrial and drone). For the latter, we evaluate the achievable accuracy of the absolute pose estimated using a Perspective-n-Point (PnP) algorithm, with geometric ground truth derived from geo-referenced trajectory data. The results indicate that the learnable feature matching methods vastly outperform traditional approaches regarding accuracy and robustness on our challenging custom datasets with zero to 12 RANSAC-inliers and zero to 0.16 area under the curve. We believe that this work will foster the development of model-based visual localization methods. Link to the code: https://github.com/simBauer/To\_Glue\_or\_not\_to\_Glue
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025



Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
OPAL: Visibility-aware LiDAR-to-OpenStreetMap Place Recognition via Adaptive Radial Fusion
Apr 30, 2025LiDAR place recognition is a critical capability for autonomous navigation and cross-modal localization in large-scale outdoor environments. Existing approaches predominantly depend on pre-built 3D dense maps or aerial imagery, which impose significant storage overhead and lack real-time adaptability. In this paper, we propose OPAL, a novel network for LiDAR place recognition that leverages OpenStreetMap (OSM) as a lightweight and up-to-date prior. Our key innovation lies in bridging the domain disparity between sparse LiDAR scans and structured OSM data through two carefully designed components. First, a cross-modal visibility mask that identifies maximal observable regions from both modalities to guide feature learning. Second, an adaptive radial fusion module that dynamically consolidates radial features into discriminative global descriptors. Extensive experiments on the KITTI and KITTI-360 datasets demonstrate OPAL's superiority, achieving 15.98% higher recall at @1m threshold for top-1 retrieved matches, along with 12x faster inference speed compared to the state-of-the-art approach. Code and datasets will be publicly available.
Texture2LoD3: Enabling LoD3 Building Reconstruction With Panoramic Images
Apr 07, 2025



Despite recent advancements in surface reconstruction, Level of Detail (LoD) 3 building reconstruction remains an unresolved challenge. The main issue pertains to the object-oriented modelling paradigm, which requires georeferencing, watertight geometry, facade semantics, and low-poly representation -- Contrasting unstructured mesh-oriented models. In Texture2LoD3, we introduce a novel method leveraging the ubiquity of 3D building model priors and panoramic street-level images, enabling the reconstruction of LoD3 building models. We observe that prior low-detail building models can serve as valid planar targets for ortho-rectifying street-level panoramic images. Moreover, deploying segmentation on accurately textured low-level building surfaces supports maintaining essential georeferencing, watertight geometry, and low-poly representation for LoD3 reconstruction. In the absence of LoD3 validation data, we additionally introduce the ReLoD3 dataset, on which we experimentally demonstrate that our method leads to improved facade segmentation accuracy by 11% and can replace costly manual projections. We believe that Texture2LoD3 can scale the adoption of LoD3 models, opening applications in estimating building solar potential or enhancing autonomous driving simulations. The project website, code, and data are available here: https://wenzhaotang.github.io/Texture2LoD3/.
CDGS: Confidence-Aware Depth Regularization for 3D Gaussian Splatting
Feb 20, 20253D Gaussian Splatting (3DGS) has shown significant advantages in novel view synthesis (NVS), particularly in achieving high rendering speeds and high-quality results. However, its geometric accuracy in 3D reconstruction remains limited due to the lack of explicit geometric constraints during optimization. This paper introduces CDGS, a confidence-aware depth regularization approach developed to enhance 3DGS. We leverage multi-cue confidence maps of monocular depth estimation and sparse Structure-from-Motion depth to adaptively adjust depth supervision during the optimization process. Our method demonstrates improved geometric detail preservation in early training stages and achieves competitive performance in both NVS quality and geometric accuracy. Experiments on the publicly available Tanks and Temples benchmark dataset show that our method achieves more stable convergence behavior and more accurate geometric reconstruction results, with improvements of up to 2.31 dB in PSNR for NVS and consistently lower geometric errors in M3C2 distance metrics. Notably, our method reaches comparable F-scores to the original 3DGS with only 50% of the training iterations. We expect this work will facilitate the development of efficient and accurate 3D reconstruction systems for real-world applications such as digital twin creation, heritage preservation, or forestry applications.
FeatureGS: Eigenvalue-Feature Optimization in 3D Gaussian Splatting for Geometrically Accurate and Artifact-Reduced Reconstruction
Jan 29, 20253D Gaussian Splatting (3DGS) has emerged as a powerful approach for 3D scene reconstruction using 3D Gaussians. However, neither the centers nor surfaces of the Gaussians are accurately aligned to the object surface, complicating their direct use in point cloud and mesh reconstruction. Additionally, 3DGS typically produces floater artifacts, increasing the number of Gaussians and storage requirements. To address these issues, we present FeatureGS, which incorporates an additional geometric loss term based on an eigenvalue-derived 3D shape feature into the optimization process of 3DGS. The goal is to improve geometric accuracy and enhance properties of planar surfaces with reduced structural entropy in local 3D neighborhoods.We present four alternative formulations for the geometric loss term based on 'planarity' of Gaussians, as well as 'planarity', 'omnivariance', and 'eigenentropy' of Gaussian neighborhoods. We provide quantitative and qualitative evaluations on 15 scenes of the DTU benchmark dataset focusing on following key aspects: Geometric accuracy and artifact-reduction, measured by the Chamfer distance, and memory efficiency, evaluated by the total number of Gaussians. Additionally, rendering quality is monitored by Peak Signal-to-Noise Ratio. FeatureGS achieves a 30 % improvement in geometric accuracy, reduces the number of Gaussians by 90 %, and suppresses floater artifacts, while maintaining comparable photometric rendering quality. The geometric loss with 'planarity' from Gaussians provides the highest geometric accuracy, while 'omnivariance' in Gaussian neighborhoods reduces floater artifacts and number of Gaussians the most. This makes FeatureGS a strong method for geometrically accurate, artifact-reduced and memory-efficient 3D scene reconstruction, enabling the direct use of Gaussian centers for geometric representation.
HoloGS: Instant Depth-based 3D Gaussian Splatting with Microsoft HoloLens 2
May 03, 2024



In the fields of photogrammetry, computer vision and computer graphics, the task of neural 3D scene reconstruction has led to the exploration of various techniques. Among these, 3D Gaussian Splatting stands out for its explicit representation of scenes using 3D Gaussians, making it appealing for tasks like 3D point cloud extraction and surface reconstruction. Motivated by its potential, we address the domain of 3D scene reconstruction, aiming to leverage the capabilities of the Microsoft HoloLens 2 for instant 3D Gaussian Splatting. We present HoloGS, a novel workflow utilizing HoloLens sensor data, which bypasses the need for pre-processing steps like Structure from Motion by instantly accessing the required input data i.e. the images, camera poses and the point cloud from depth sensing. We provide comprehensive investigations, including the training process and the rendering quality, assessed through the Peak Signal-to-Noise Ratio, and the geometric 3D accuracy of the densified point cloud from Gaussian centers, measured by Chamfer Distance. We evaluate our approach on two self-captured scenes: An outdoor scene of a cultural heritage statue and an indoor scene of a fine-structured plant. Our results show that the HoloLens data, including RGB images, corresponding camera poses, and depth sensing based point clouds to initialize the Gaussians, are suitable as input for 3D Gaussian Splatting.