 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Switching in End-to-End Automatic Speech Recognition: A Systematic Literature Review
Jul 10, 2025



Motivated by a growing research interest into automatic speech recognition (ASR), and the growing body of work for languages in which code-switching (CS) often occurs, we present a systematic literature review of code-switching in end-to-end ASR models. We collect and manually annotate papers published in peer reviewed venues. We document the languages considered, datasets, metrics, model choices, and performance, and present a discussion of challenges in end-to-end ASR for code-switching. Our analysis thus provides insights on current research efforts and available resources as well as opportunities and gaps to guide future research.
JEEM: Vision-Language Understanding in Four Arabic Dialects
Mar 27, 2025We introduce JEEM, a benchmark designed to evaluate Vision-Language Models (VLMs) on visual understanding across four Arabic-speaking countries: Jordan, The Emirates, Egypt, and Morocco. JEEM includes the tasks of image captioning and visual question answering, and features culturally rich and regionally diverse content. This dataset aims to assess the ability of VLMs to generalize across dialects and accurately interpret cultural elements in visual contexts. In an evaluation of five prominent open-source Arabic VLMs and GPT-4V, we find that the Arabic VLMs consistently underperform, struggling with both visual understanding and dialect-specific generation. While GPT-4V ranks best in this comparison, the model's linguistic competence varies across dialects, and its visual understanding capabilities lag behind. This underscores the need for more inclusive models and the value of culturally-diverse evaluation paradigms.
Commonsense Reasoning in Arab Culture
Feb 18, 2025



Despite progress in Arabic large language models, such as Jais and AceGPT, their evaluation on commonsense reasoning has largely relied on machine-translated datasets, which lack cultural depth and may introduce Anglocentric biases. Commonsense reasoning is shaped by geographical and cultural contexts, and existing English datasets fail to capture the diversity of the Arab world. To address this, we introduce \datasetname, a commonsense reasoning dataset in Modern Standard Arabic (MSA), covering cultures of 13 countries across the Gulf, Levant, North Africa, and the Nile Valley. The dataset was built from scratch by engaging native speakers to write and validate culturally relevant questions for their respective countries. \datasetname spans 12 daily life domains with 54 fine-grained subtopics, reflecting various aspects of social norms, traditions, and everyday experiences. Zero-shot evaluations show that open-weight language models with up to 32B parameters struggle to comprehend diverse Arab cultures, with performance varying across regions. These findings highlight the need for more culturally aware models and datasets tailored to the Arabic-speaking world.
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
uDistil-Whisper: Label-Free Data Filtering for Knowledge Distillation via Large-Scale Pseudo Labelling
Jul 01, 2024Recent work on distilling Whisper's knowledge into small models using pseudo-labels shows promising performance while reducing the size by up to 50\%. This results in small, efficient, and dedicated models. However, a critical step of distillation from pseudo-labels involves filtering high-quality predictions and using only those during training. This step requires ground truth to compare and filter bad examples making the whole process supervised. In addition to that, the distillation process requires a large amount of data thereby limiting the ability to distil models in low-resource settings. To address this challenge, we propose an unsupervised or label-free framework for distillation, thus eliminating the requirement for labeled data altogether. Through experimentation, we show that our best distilled models outperform the teacher model by 5-7 points in terms of WER. Additionally, our models are on par with or better than similar supervised data filtering setup. When we scale the data, our models significantly outperform all zero-shot and supervised models. In this work, we demonstrate that it's possible to distill large Whisper models into relatively small models without using any labeled data. As a result, our distilled models are 25-50\% more compute and memory efficient while maintaining performance equal to or better than the teacher model.
To Distill or Not to Distill? On the Robustness of Robust Knowledge Distillation
Jun 06, 2024Arabic is known to present unique challenges for Automatic Speech Recognition (ASR). On one hand, its rich linguistic diversity and wide range of dialects complicate the development of robust, inclusive models. On the other, current multilingual ASR models are compute-intensive and lack proper comprehensive evaluations. In light of these challenges, we distill knowledge from large teacher models into smaller student variants that are more efficient. We also introduce a novel human-annotated dataset covering five under-represented Arabic dialects for evaluation. We further evaluate both our models and existing SoTA multilingual models on both standard available benchmarks and our new dialectal data. Our best-distilled model's overall performance ($45.0$\% WER) surpasses that of a SoTA model twice its size (SeamlessM4T-large-v2, WER=$47.0$\%) and its teacher model (Whisper-large-v2, WER=$55.1$\%), and its average performance on our new dialectal data ($56.9$\% WER) outperforms all other models. To gain more insight into the poor performance of these models on dialectal data, we conduct an error analysis and report the main types of errors the different models tend to make. The GitHub repository for the project is available at \url{https://github.com/UBC-NLP/distill-whisper-ar}.
TARJAMAT: Evaluation of Bard and ChatGPT on Machine Translation of Ten Arabic Varieties
Aug 06, 2023



Large language models (LLMs) finetuned to follow human instructions have recently emerged as a breakthrough in AI. Models such as Google Bard and OpenAI ChatGPT, for example, are surprisingly powerful tools for question answering, code debugging, and dialogue generation. Despite the purported multilingual proficiency of these models, their linguistic inclusivity remains insufficiently explored. Considering this constraint, we present a thorough assessment of Bard and ChatGPT (encompassing both GPT-3.5 and GPT-4) regarding their machine translation proficiencies across ten varieties of Arabic. Our evaluation covers diverse Arabic varieties such as Classical Arabic, Modern Standard Arabic, and several nuanced dialectal variants. Furthermore, we undertake a human-centric study to scrutinize the efficacy of the most recent model, Bard, in following human instructions during translation tasks. Our exhaustive analysis indicates that LLMs may encounter challenges with certain Arabic dialects, particularly those for which minimal public data exists, such as Algerian and Mauritanian dialects. However, they exhibit satisfactory performance with more prevalent dialects, albeit occasionally trailing behind established commercial systems like Google Translate. Additionally, our analysis reveals a circumscribed capability of Bard in aligning with human instructions in translation contexts. Collectively, our findings underscore that prevailing LLMs remain far from inclusive, with only limited ability to cater for the linguistic and cultural intricacies of diverse communities.
A Thorough Review on Recent Deep Learning Methodologies for Image Captioning
Jul 28, 2021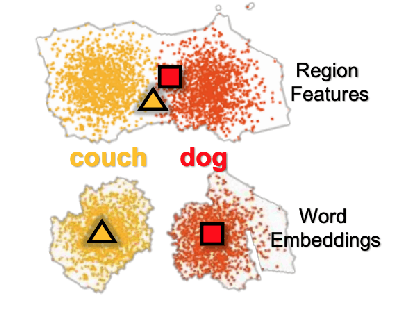
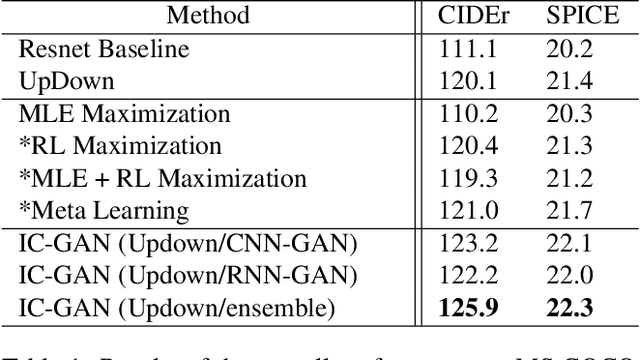
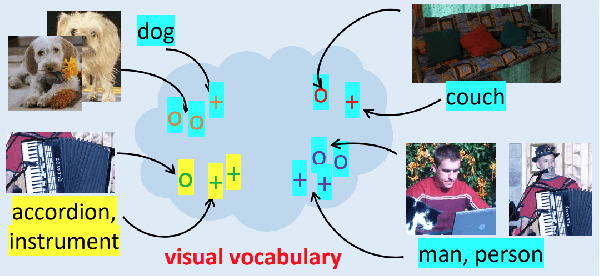
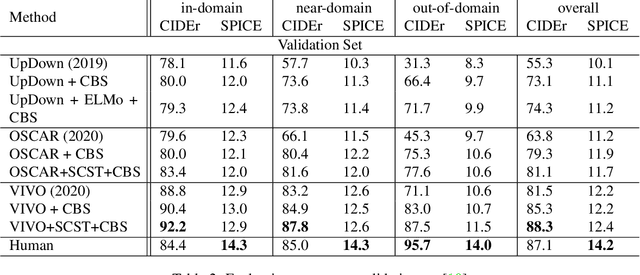
Image Captioning is a task that combines computer vision and natural language processing, where it aims to generate descriptive legends for images. It is a two-fold process relying on accurate image understanding and correct language understanding both syntactically and semantically. It is becoming increasingly difficult to keep up with the latest research and findings in the field of image captioning due to the growing amount of knowledge available on the topic. There is not, however, enough coverage of those findings in the available review papers. We perform in this paper a run-through of the current techniques, datasets, benchmarks and evaluation metrics used in image captioning. The current research on the field is mostly focused on deep learning-based methods, where attention mechanisms along with deep reinforcement and adversarial learning appear to be in the forefront of this research topic. In this paper, we review recent methodologies such as UpDown, OSCAR, VIVO, Meta Learning and a model that uses conditional generative adversarial nets. Although the GAN-based model achieves the highest score, UpDown represents an important basis for image captioning and OSCAR and VIVO are more useful as they use novel object captioning. This review paper serves as a roadmap for researchers to keep up to date with the latest contributions made in the field of image caption generation.
Experimenting with Self-Supervision using Rotation Prediction for Image Captioning
Jul 28, 2021

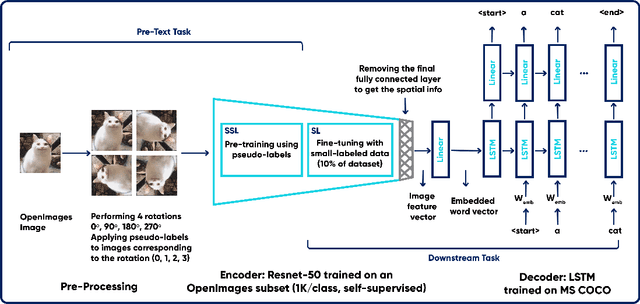

Image captioning is a task in the field of Artificial Intelligence that merges between computer vision and natural language processing. It is responsible for generating legends that describe images, and has various applications like descriptions used by assistive technology or indexing images (for search engines for instance). This makes it a crucial topic in AI that is undergoing a lot of research. This task however, like many others, is trained on large images labeled via human annotation, which can be very cumbersome: it needs manual effort, both financial and temporal costs, it is error-prone and potentially difficult to execute in some cases (e.g. medical images). To mitigate the need for labels, we attempt to use self-supervised learning, a type of learning where models use the data contained within the images themselves as labels. It is challenging to accomplish though, since the task is two-fold: the images and captions come from two different modalities and usually handled by different types of networks. It is thus not obvious what a completely self-supervised solution would look like. How it would achieve captioning in a comparable way to how self-supervision is applied today on image recognition tasks is still an ongoing research topic. In this project, we are using an encoder-decoder architecture where the encoder is a convolutional neural network (CNN) trained on OpenImages dataset and learns image features in a self-supervised fashion using the rotation pretext task. The decoder is a Long Short-Term Memory (LSTM), and it is trained, along within the image captioning model, on MS COCO dataset and is responsible of generating captions. Our GitHub repository can be found: https://github.com/elhagry1/SSL_ImageCaptioning_RotationPrediction