 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Development and Clinical Evaluation of an AI Support Tool for Improving Telemedicine Photo Quality
Sep 12, 2022
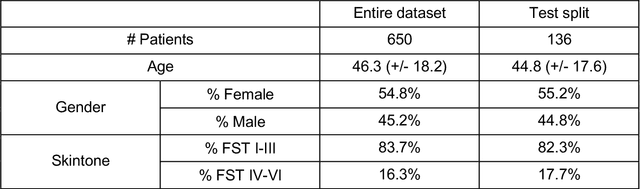
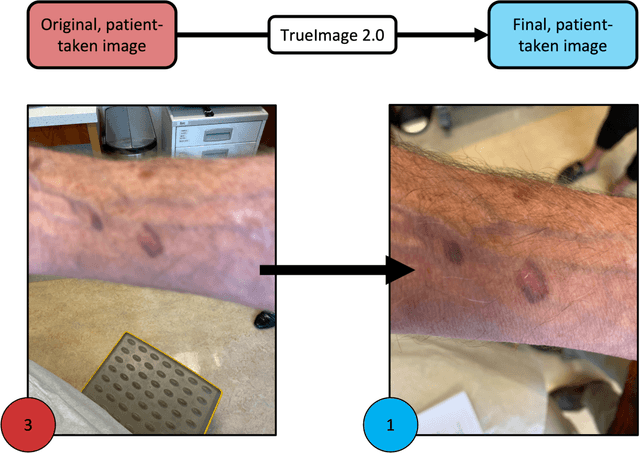

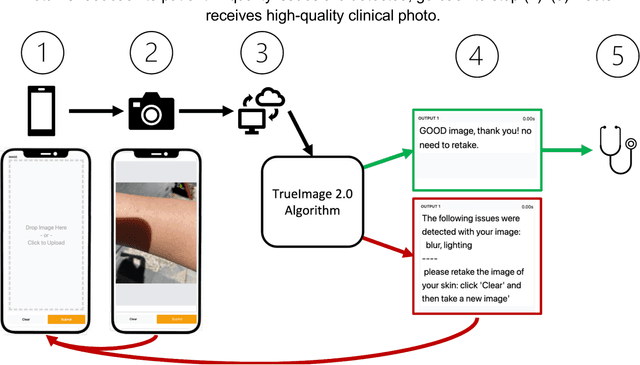
Telemedicine utilization was accelerated during the COVID-19 pandemic, and skin conditions were a common use case. However, the quality of photographs sent by patients remains a major limitation. To address this issue, we developed TrueImage 2.0, an artificial intelligence (AI) model for assessing patient photo quality for telemedicine and providing real-time feedback to patients for photo quality improvement. TrueImage 2.0 was trained on 1700 telemedicine images annotated by clinicians for photo quality. On a retrospective dataset of 357 telemedicine images, TrueImage 2.0 effectively identified poor quality images (Receiver operator curve area under the curve (ROC-AUC) =0.78) and the reason for poor quality (Blurry ROC-AUC=0.84, Lighting issues ROC-AUC=0.70). The performance is consistent across age, gender, and skin tone. Next, we assessed whether patient-TrueImage 2.0 interaction led to an improvement in submitted photo quality through a prospective clinical pilot study with 98 patients. TrueImage 2.0 reduced the number of patients with a poor-quality image by 68.0%.
VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction
Aug 09, 2022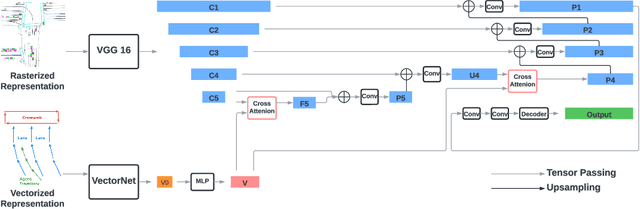
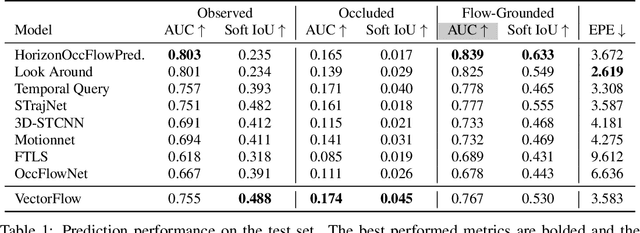

Predicting future behaviors of road agents is a key task in autonomous driving. While existing models have demonstrated great success in predicting marginal agent future behaviors, it remains a challenge to efficiently predict consistent joint behaviors of multiple agents. Recently, the occupancy flow fields representation was proposed to represent joint future states of road agents through a combination of occupancy grid and flow, which supports efficient and consistent joint predictions. In this work, we propose a novel occupancy flow fields predictor to produce accurate occupancy and flow predictions, by combining the power of an image encoder that learns features from a rasterized traffic image and a vector encoder that captures information of continuous agent trajectories and map states. The two encoded features are fused by multiple attention modules before generating final predictions. Our simple but effective model ranks 3rd place on the Waymo Open Dataset Occupancy and Flow Prediction Challenge, and achieves the best performance in the occluded occupancy and flow prediction task.
Unified Loss of Pair Similarity Optimization for Vision-Language Retrieval
Sep 28, 2022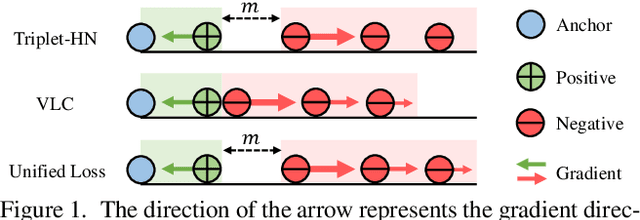
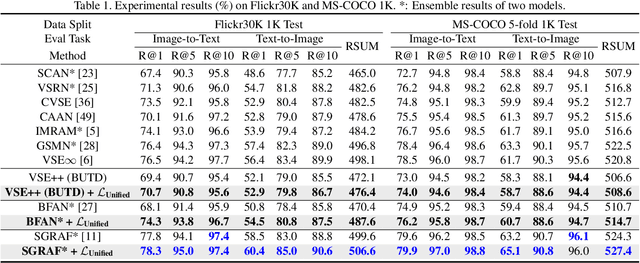
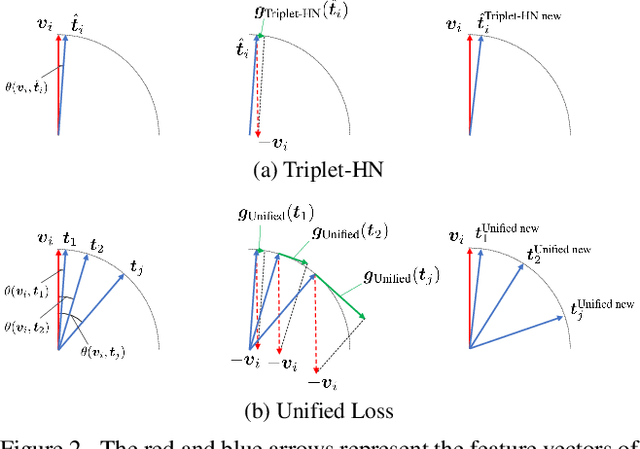

There are two popular loss functions used for vision-language retrieval, i.e., triplet loss and contrastive learning loss, both of them essentially minimize the difference between the similarities of negative pairs and positive pairs. More specifically, Triplet loss with Hard Negative mining (Triplet-HN), which is widely used in existing retrieval models to improve the discriminative ability, is easy to fall into local minima in training. On the other hand, Vision-Language Contrastive learning loss (VLC), which is widely used in the vision-language pre-training, has been shown to achieve significant performance gains on vision-language retrieval, but the performance of fine-tuning with VLC on small datasets is not satisfactory. This paper proposes a unified loss of pair similarity optimization for vision-language retrieval, providing a powerful tool for understanding existing loss functions. Our unified loss includes the hard sample mining strategy of VLC and introduces the margin used by the triplet loss for better similarity separation. It is shown that both Triplet-HN and VLC are special forms of our unified loss. Compared with the Triplet-HN, our unified loss has a fast convergence speed. Compared with the VLC, our unified loss is more discriminative and can provide better generalization in downstream fine-tuning tasks. Experiments on image-text and video-text retrieval benchmarks show that our unified loss can significantly improve the performance of the state-of-the-art retrieval models.
Collaboration of Pre-trained Models Makes Better Few-shot Learner
Sep 25, 2022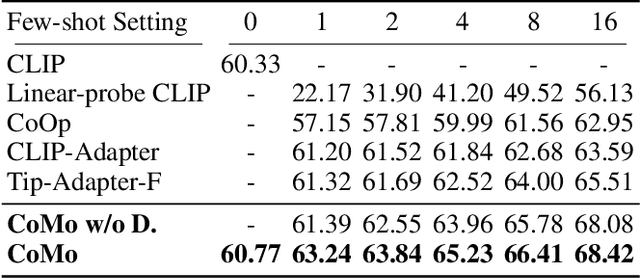
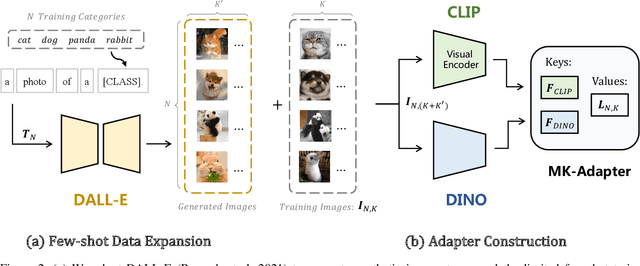
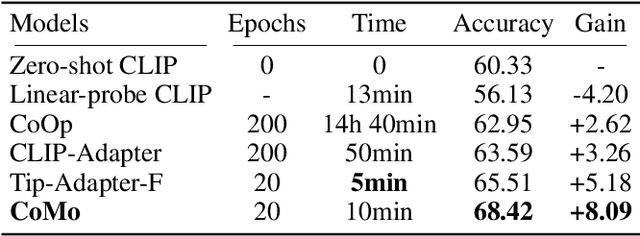
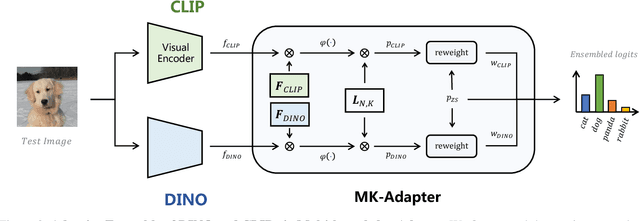
Few-shot classification requires deep neural networks to learn generalized representations only from limited training images, which is challenging but significant in low-data regimes. Recently, CLIP-based methods have shown promising few-shot performance benefited from the contrastive language-image pre-training. Based on this point, we question if the large-scale pre-training can alleviate the few-shot data deficiency and also assist the representation learning by the pre-learned knowledge. In this paper, we propose CoMo, a Collaboration of pre-trained Models that incorporates diverse prior knowledge from various pre-training paradigms for better few-shot learning. Our CoMo includes: CLIP's language-contrastive knowledge, DINO's vision-contrastive knowledge, and DALL-E's language-generative knowledge. Specifically, CoMo works in two aspects: few-shot data expansion and diverse knowledge ensemble. For one, we generate synthetic images via zero-shot DALL-E to enrich the few-shot training data without any manpower. For the other, we introduce a learnable Multi-Knowledge Adapter (MK-Adapter) to adaptively blend the predictions from CLIP and DINO. By such collaboration, CoMo can fully unleash the potential of different pre-training methods and unify them to perform state-of-the-art for few-shot classification. We conduct extensive experiments on 11 datasets to demonstrate the superiority and generalization ability of our approach.
Shape-constrained Symbolic Regression with NSGA-III
Sep 28, 2022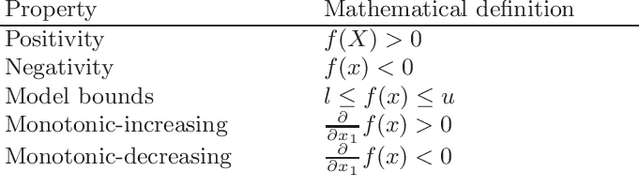


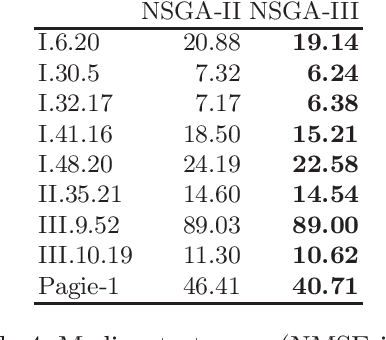
Shape-constrained symbolic regression (SCSR) allows to include prior knowledge into data-based modeling. This inclusion allows to ensure that certain expected behavior is better reflected by the resulting models. The expected behavior is defined via constraints, which refer to the function form e.g. monotonicity, concavity, convexity or the models image boundaries. In addition to the advantage of obtaining more robust and reliable models due to defining constraints over the functions shape, the use of SCSR allows to find models which are more robust to noise and have a better extrapolation behavior. This paper presents a mutlicriterial approach to minimize the approximation error as well as the constraint violations. Explicitly the two algorithms NSGA-II and NSGA-III are implemented and compared against each other in terms of model quality and runtime. Both algorithms are capable of dealing with multiple objectives, whereas NSGA-II is a well established multi-objective approach performing well on instances with up-to 3 objectives. NSGA-III is an extension of the NSGA-II algorithm and was developed to handle problems with "many" objectives (more than 3 objectives). Both algorithms are executed on a selected set of benchmark instances from physics textbooks. The results indicate that both algorithms are able to find largely feasible solutions and NSGA-III provides slight improvements in terms of model quality. Moreover, an improvement in runtime can be observed using the many-objective approach.
Robust Category-Level 6D Pose Estimation with Coarse-to-Fine Rendering of Neural Features
Sep 12, 2022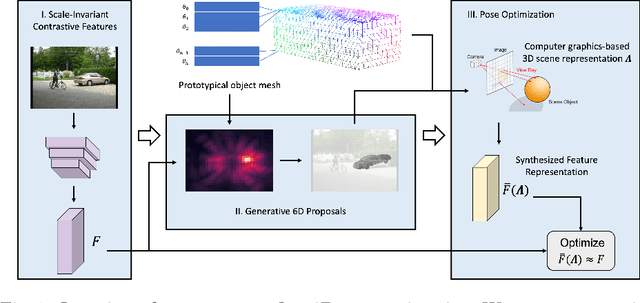
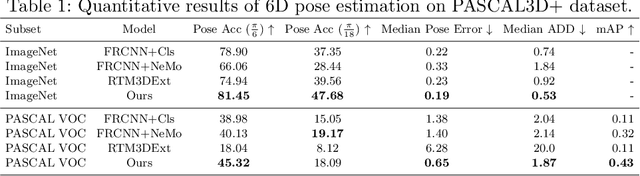


We consider the problem of category-level 6D pose estimation from a single RGB image. Our approach represents an object category as a cuboid mesh and learns a generative model of the neural feature activations at each mesh vertex to perform pose estimation through differentiable rendering. A common problem of rendering-based approaches is that they rely on bounding box proposals, which do not convey information about the 3D rotation of the object and are not reliable when objects are partially occluded. Instead, we introduce a coarse-to-fine optimization strategy that utilizes the rendering process to estimate a sparse set of 6D object proposals, which are subsequently refined with gradient-based optimization. The key to enabling the convergence of our approach is a neural feature representation that is trained to be scale- and rotation-invariant using contrastive learning. Our experiments demonstrate an enhanced category-level 6D pose estimation performance compared to prior work, particularly under strong partial occlusion.
Don't Stop Learning: Towards Continual Learning for the CLIP Model
Jul 20, 2022
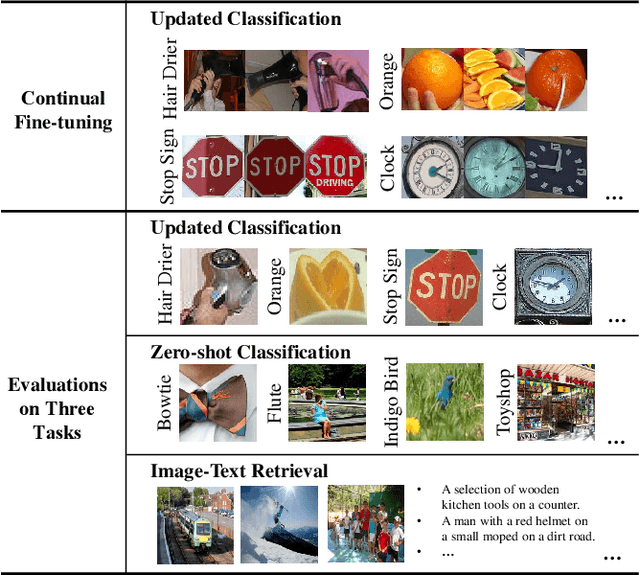
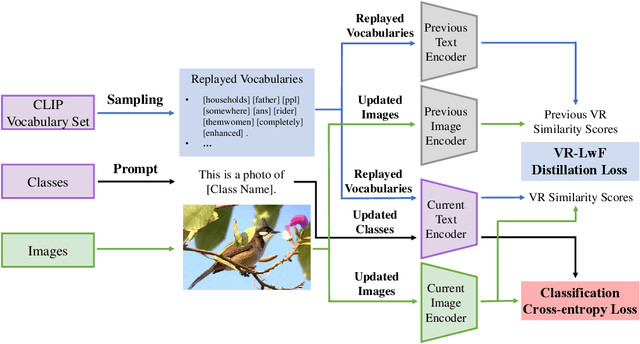
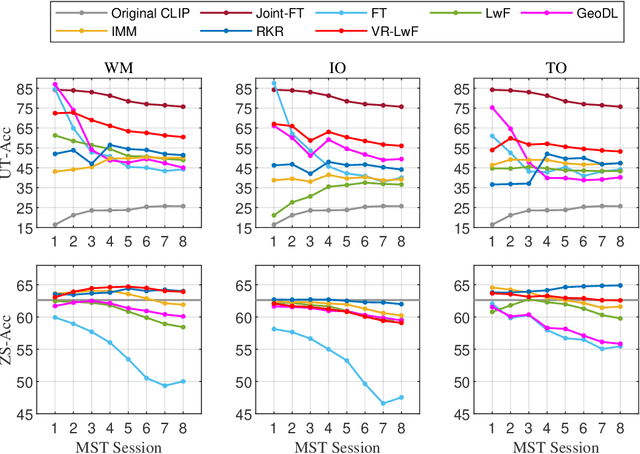
The Contrastive Language-Image Pre-training (CLIP) Model is a recently proposed large-scale pre-train model which attracts increasing attention in the computer vision community. Benefiting from its gigantic image-text training set, the CLIP model has learned outstanding capabilities in zero-shot learning and image-text matching. To boost the recognition performance of CLIP on some target visual concepts, it is often desirable to further update the CLIP model by fine-tuning some classes-of-interest on extra training data. This operation, however, raises an important concern: will the update hurt the zero-shot learning or image-text matching capability of the CLIP, i.e., the catastrophic forgetting issue? If yes, could existing continual learning algorithms be adapted to alleviate the risk of catastrophic forgetting? To answer these questions, this work conducts a systemic study on the continual learning issue of the CLIP model. We construct evaluation protocols to measure the impact of fine-tuning updates and explore different ways to upgrade existing continual learning methods to mitigate the forgetting issue of the CLIP model. Our study reveals the particular challenges of CLIP continual learning problem and lays a foundation for further researches. Moreover, we propose a new algorithm, dubbed Learning without Forgetting via Replayed Vocabulary (VR-LwF), which shows exact effectiveness for alleviating the forgetting issue of the CLIP model.
Adaptive Sparse ViT: Towards Learnable Adaptive Token Pruning by Fully Exploiting Self-Attention
Sep 28, 2022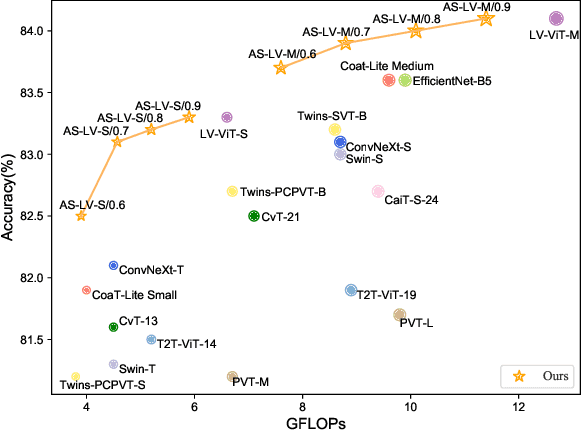
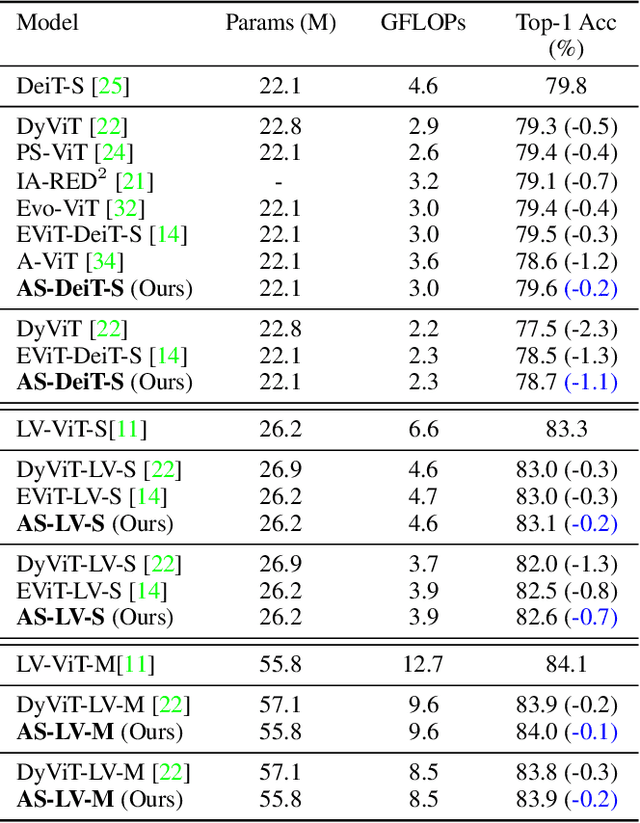

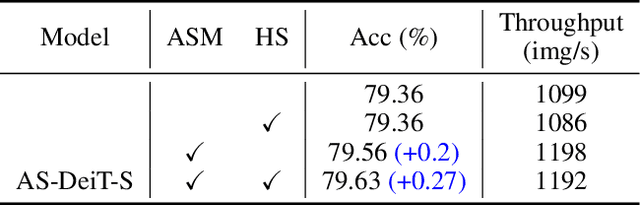
Vision transformer has emerged as a new paradigm in computer vision, showing excellent performance while accompanied by expensive computational cost. Image token pruning is one of the main approaches for ViT compression, due to the facts that the complexity is quadratic with respect to the token number, and many tokens containing only background regions do not truly contribute to the final prediction. Existing works either rely on additional modules to score the importance of individual tokens, or implement a fixed ratio pruning strategy for different input instances. In this work, we propose an adaptive sparse token pruning framework with a minimal cost. Our approach is based on learnable thresholds and leverages the Multi-Head Self-Attention to evaluate token informativeness with little additional operations. Specifically, we firstly propose an inexpensive attention head importance weighted class attention scoring mechanism. Then, learnable parameters are inserted in ViT as thresholds to distinguish informative tokens from unimportant ones. By comparing token attention scores and thresholds, we can discard useless tokens hierarchically and thus accelerate inference. The learnable thresholds are optimized in budget-aware training to balance accuracy and complexity, performing the corresponding pruning configurations for different input instances. Extensive experiments demonstrate the effectiveness of our approach. For example, our method improves the throughput of DeiT-S by 50% and brings only 0.2% drop in top-1 accuracy, which achieves a better trade-off between accuracy and latency than the previous methods.
Fine-Grained Image Analysis with Deep Learning: A Survey
Nov 11, 2021
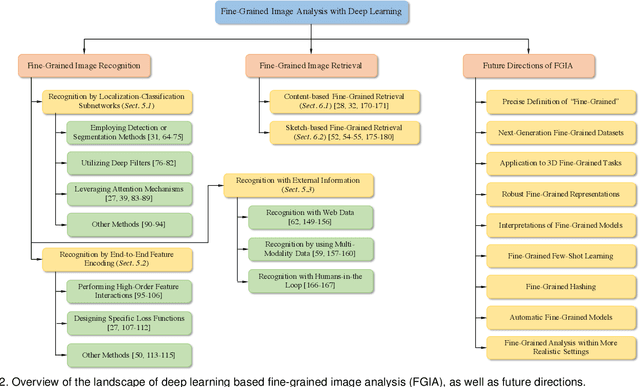
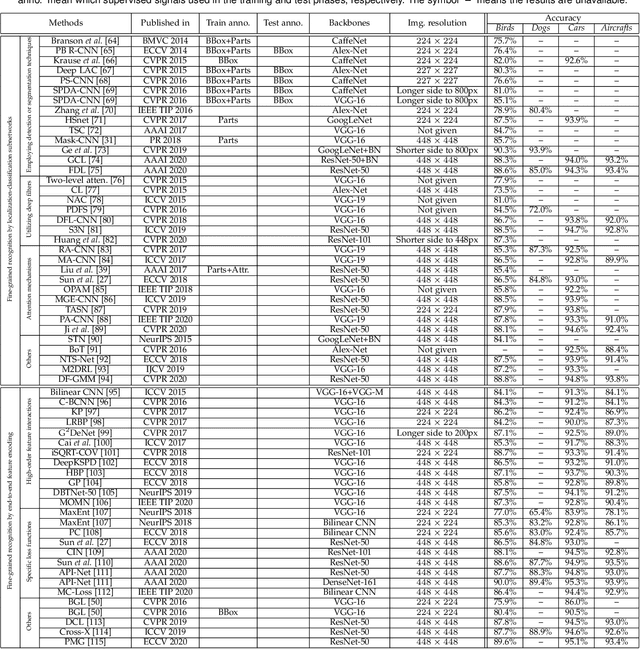
Fine-grained image analysis (FGIA) is a longstanding and fundamental problem in computer vision and pattern recognition, and underpins a diverse set of real-world applications. The task of FGIA targets analyzing visual objects from subordinate categories, e.g., species of birds or models of cars. The small inter-class and large intra-class variation inherent to fine-grained image analysis makes it a challenging problem. Capitalizing on advances in deep learning, in recent years we have witnessed remarkable progress in deep learning powered FGIA. In this paper we present a systematic survey of these advances, where we attempt to re-define and broaden the field of FGIA by consolidating two fundamental fine-grained research areas -- fine-grained image recognition and fine-grained image retrieval. In addition, we also review other key issues of FGIA, such as publicly available benchmark datasets and related domain-specific applications. We conclude by highlighting several research directions and open problems which need further exploration from the community.
Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
Sep 12, 2022
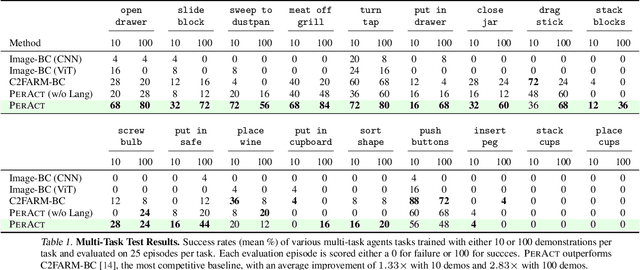
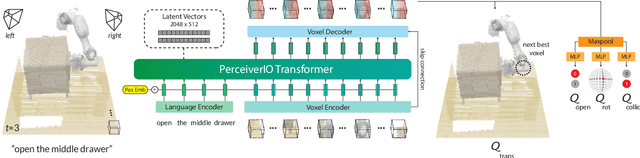
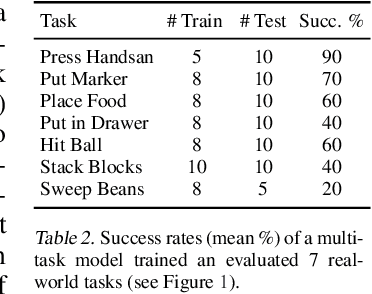
Transformers have revolutionized vision and natural language processing with their ability to scale with large datasets. But in robotic manipulation, data is both limited and expensive. Can we still benefit from Transformers with the right problem formulation? We investigate this question with PerAct, a language-conditioned behavior-cloning agent for multi-task 6-DoF manipulation. PerAct encodes language goals and RGB-D voxel observations with a Perceiver Transformer, and outputs discretized actions by "detecting the next best voxel action". Unlike frameworks that operate on 2D images, the voxelized observation and action space provides a strong structural prior for efficiently learning 6-DoF policies. With this formulation, we train a single multi-task Transformer for 18 RLBench tasks (with 249 variations) and 7 real-world tasks (with 18 variations) from just a few demonstrations per task. Our results show that PerAct significantly outperforms unstructured image-to-action agents and 3D ConvNet baselines for a wide range of tabletop tasks.