 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Development and Clinical Evaluation of an AI Support Tool for Improving Telemedicine Photo Quality
Sep 12, 2022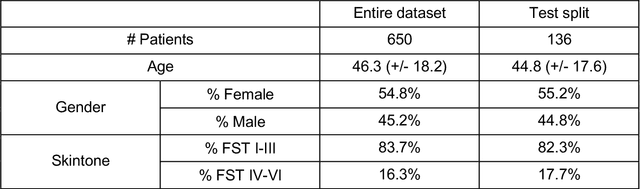
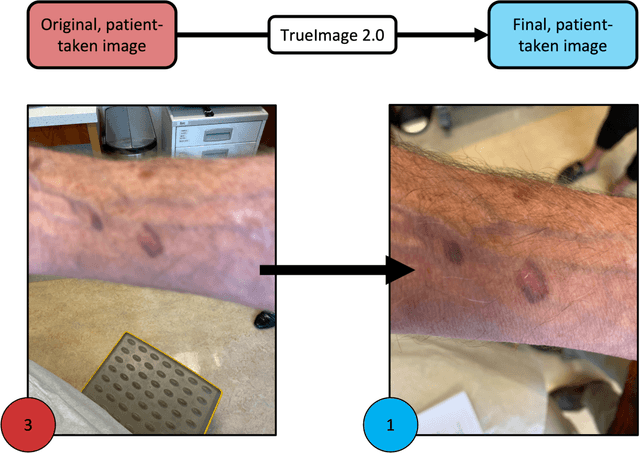

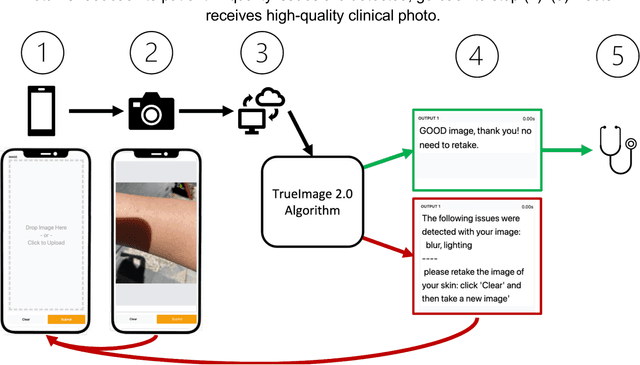
Telemedicine utilization was accelerated during the COVID-19 pandemic, and skin conditions were a common use case. However, the quality of photographs sent by patients remains a major limitation. To address this issue, we developed TrueImage 2.0, an artificial intelligence (AI) model for assessing patient photo quality for telemedicine and providing real-time feedback to patients for photo quality improvement. TrueImage 2.0 was trained on 1700 telemedicine images annotated by clinicians for photo quality. On a retrospective dataset of 357 telemedicine images, TrueImage 2.0 effectively identified poor quality images (Receiver operator curve area under the curve (ROC-AUC) =0.78) and the reason for poor quality (Blurry ROC-AUC=0.84, Lighting issues ROC-AUC=0.70). The performance is consistent across age, gender, and skin tone. Next, we assessed whether patient-TrueImage 2.0 interaction led to an improvement in submitted photo quality through a prospective clinical pilot study with 98 patients. TrueImage 2.0 reduced the number of patients with a poor-quality image by 68.0%.