 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Primer on Topological Data Analysis to Support Image Analysis Tasks in Environmental Science
Jul 21, 2022
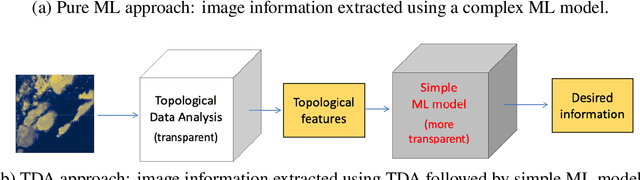


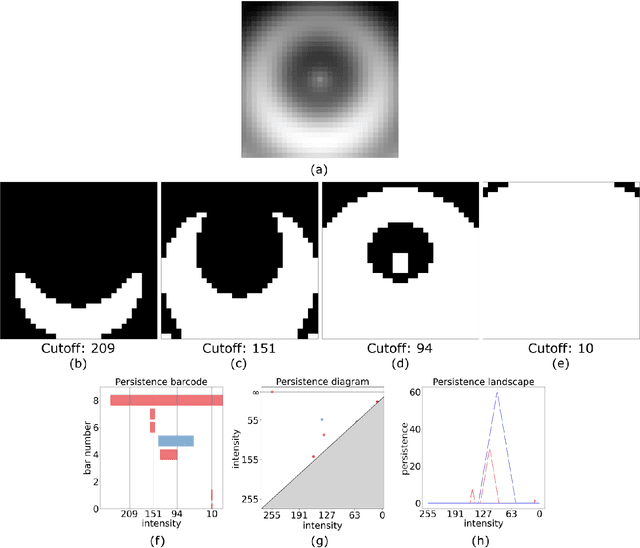
Topological data analysis (TDA) is a tool from data science and mathematics that is beginning to make waves in environmental science. In this work, we seek to provide an intuitive and understandable introduction to a tool from TDA that is particularly useful for the analysis of imagery, namely persistent homology. We briefly discuss the theoretical background but focus primarily on understanding the output of this tool and discussing what information it can glean. To this end, we frame our discussion around a guiding example of classifying satellite images from the Sugar, Fish, Flower, and Gravel Dataset produced for the study of mesocale organization of clouds by Rasp et. al. in 2020 (arXiv:1906:01906). We demonstrate how persistent homology and its vectorization, persistence landscapes, can be used in a workflow with a simple machine learning algorithm to obtain good results, and explore in detail how we can explain this behavior in terms of image-level features. One of the core strengths of persistent homology is how interpretable it can be, so throughout this paper we discuss not just the patterns we find, but why those results are to be expected given what we know about the theory of persistent homology. Our goal is that a reader of this paper will leave with a better understanding of TDA and persistent homology, be able to identify problems and datasets of their own for which persistent homology could be helpful, and gain an understanding of results they obtain from applying the included GitHub example code.
MAP: Modality-Agnostic Uncertainty-Aware Vision-Language Pre-training Model
Oct 11, 2022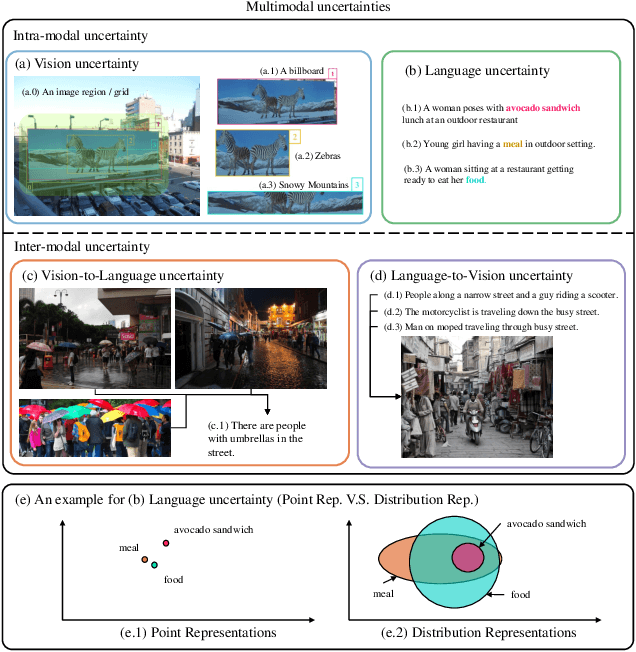
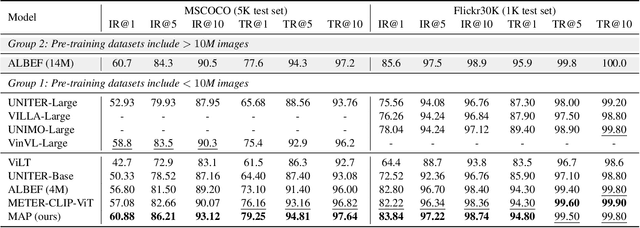
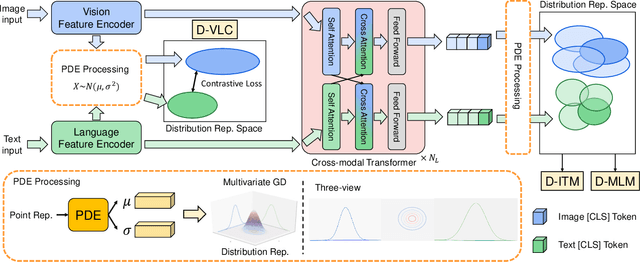
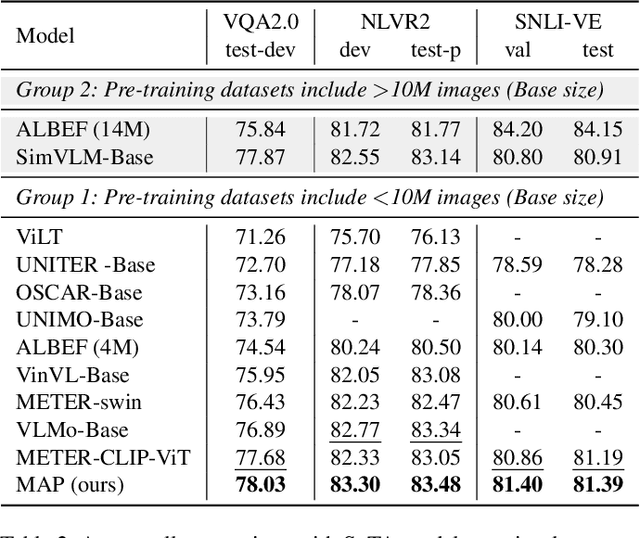
Multimodal semantic understanding often has to deal with uncertainty, which means the obtained message tends to refer to multiple targets. Such uncertainty is problematic for our interpretation, including intra-modal and inter-modal uncertainty. Little effort studies the modeling of this uncertainty, particularly in pre-training on unlabeled datasets and fine-tuning in task-specific downstream tasks. To address this, we project the representations of all modalities as probabilistic distributions via a Probability Distribution Encoder (PDE) by utilizing rich multimodal semantic information. Furthermore, we integrate uncertainty modeling with popular pre-training frameworks and propose suitable pre-training tasks: Distribution-based Vision-Language Contrastive learning (D-VLC), Distribution-based Masked Language Modeling (D-MLM), and Distribution-based Image-Text Matching (D-ITM). The fine-tuned models are applied to challenging downstream tasks, including image-text retrieval, visual question answering, visual reasoning, and visual entailment, and achieve state-of-the-art results. Code is released at https://github.com/IIGROUP/MAP.
SaiT: Sparse Vision Transformers through Adaptive Token Pruning
Oct 11, 2022
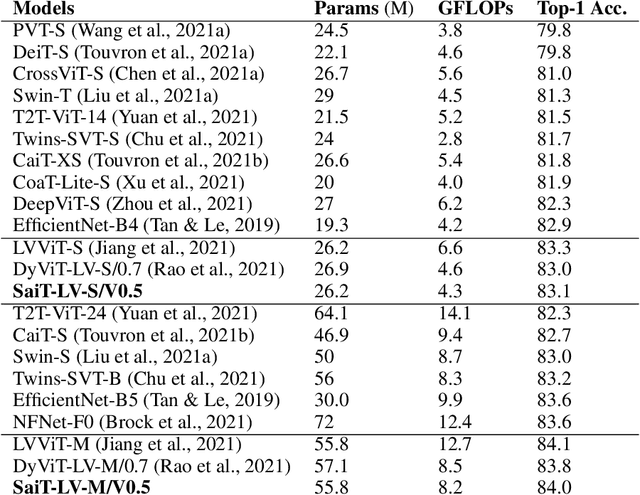
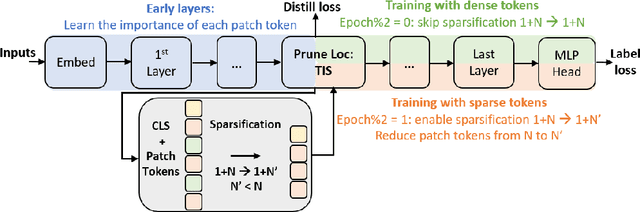
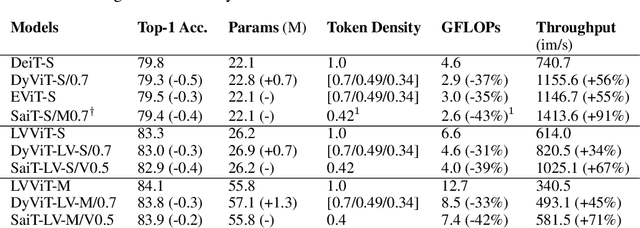
While vision transformers have achieved impressive results, effectively and efficiently accelerating these models can further boost performances. In this work, we propose a dense/sparse training framework to obtain a unified model, enabling weight sharing across various token densities. Thus one model offers a range of accuracy and throughput tradeoffs for different applications. Besides, we introduce adaptive token pruning to optimize the patch token sparsity based on the input image. In addition, we investigate knowledge distillation to enhance token selection capability in early transformer modules. Sparse adaptive image Transformer (SaiT) offers varying levels of model acceleration by merely changing the token sparsity on the fly. Specifically, SaiT reduces the computation complexity (FLOPs) by 39% - 43% and increases the throughput by 67% - 91% with less than 0.5% accuracy loss for various vision transformer models. Meanwhile, the same model also provides the zero accuracy drop option by skipping the sparsification step. SaiT achieves better accuracy and computation tradeoffs than state-of-the-art transformer and convolutional models.
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 14, 2022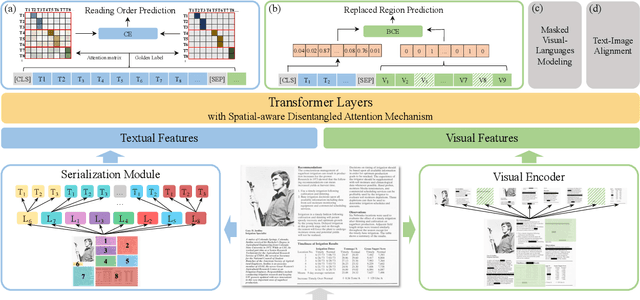
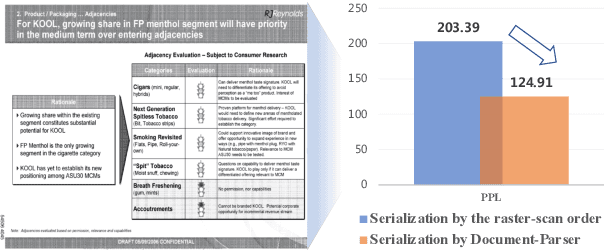
Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.
Sequential Learning Of Neural Networks for Prequential MDL
Oct 14, 2022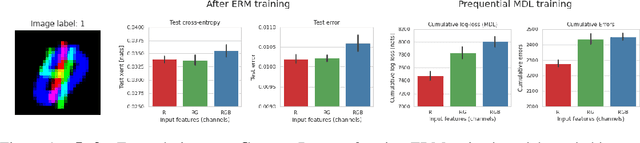
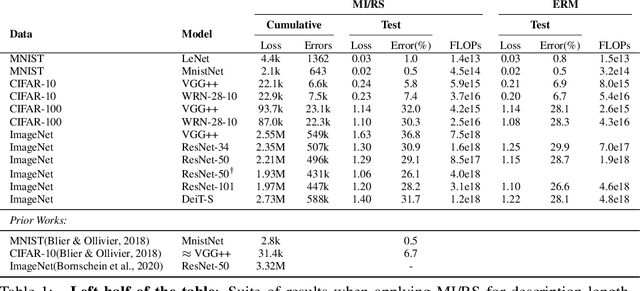
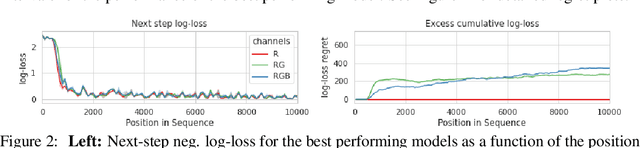

Minimum Description Length (MDL) provides a framework and an objective for principled model evaluation. It formalizes Occam's Razor and can be applied to data from non-stationary sources. In the prequential formulation of MDL, the objective is to minimize the cumulative next-step log-loss when sequentially going through the data and using previous observations for parameter estimation. It thus closely resembles a continual- or online-learning problem. In this study, we evaluate approaches for computing prequential description lengths for image classification datasets with neural networks. Considering the computational cost, we find that online-learning with rehearsal has favorable performance compared to the previously widely used block-wise estimation. We propose forward-calibration to better align the models predictions with the empirical observations and introduce replay-streams, a minibatch incremental training technique to efficiently implement approximate random replay while avoiding large in-memory replay buffers. As a result, we present description lengths for a suite of image classification datasets that improve upon previously reported results by large margins.
Learning by Hallucinating: Vision-Language Pre-training with Weak Supervision
Oct 27, 2022
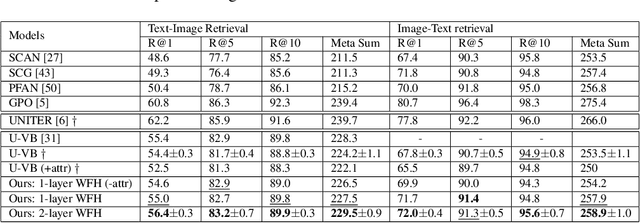
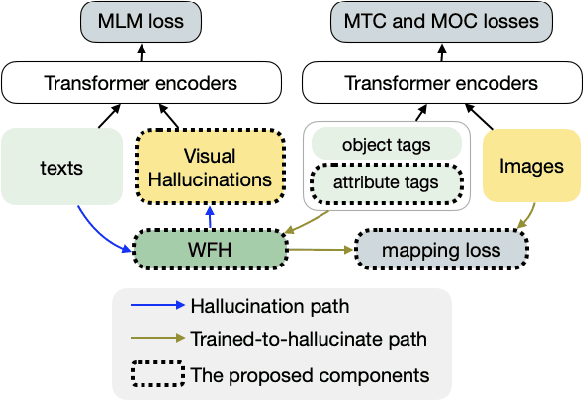
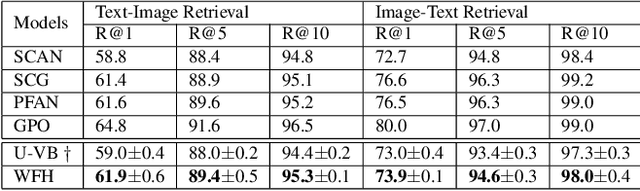
Weakly-supervised vision-language (V-L) pre-training (W-VLP) aims at learning cross-modal alignment with little or no paired data, such as aligned images and captions. Recent W-VLP methods, which pair visual features with object tags, help achieve performances comparable with some VLP models trained with aligned pairs in various V-L downstream tasks. This, however, is not the case in cross-modal retrieval (XMR). We argue that the learning of such a W-VLP model is curbed and biased by the object tags of limited semantics. We address the lack of paired V-L data for model supervision with a novel Visual Vocabulary based Feature Hallucinator (WFH), which is trained via weak supervision as a W-VLP model, not requiring images paired with captions. WFH generates visual hallucinations from texts, which are then paired with the originally unpaired texts, allowing more diverse interactions across modalities. Empirically, WFH consistently boosts the prior W-VLP works, e.g. U-VisualBERT (U-VB), over a variety of V-L tasks, i.e. XMR, Visual Question Answering, etc. Notably, benchmarked with recall@{1,5,10}, it consistently improves U-VB on image-to-text and text-to-image retrieval on two popular datasets Flickr30K and MSCOCO. Meanwhile, it gains by at least 14.5% in cross-dataset generalization tests on these XMR tasks. Moreover, in other V-L downstream tasks considered, our WFH models are on par with models trained with paired V-L data, revealing the utility of unpaired data. These results demonstrate greater generalization of the proposed W-VLP model with WFH.
State of the Art in Dense Monocular Non-Rigid 3D Reconstruction
Oct 27, 2022
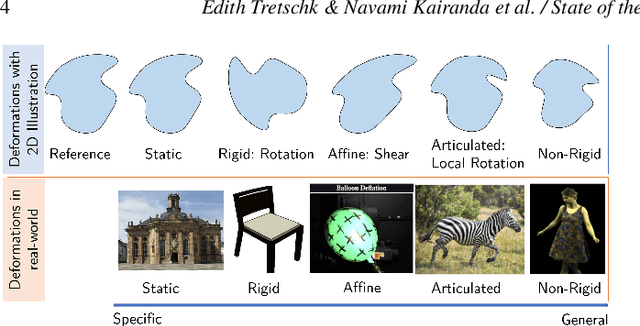

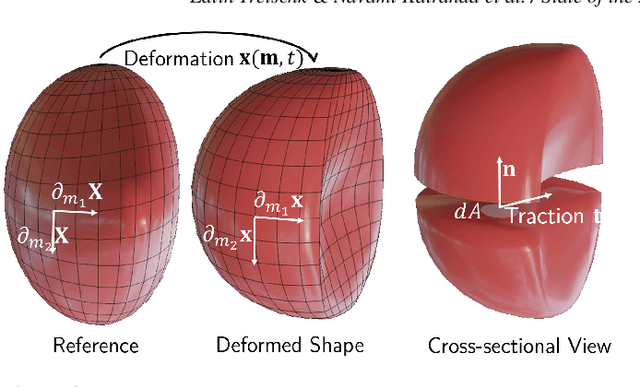
3D reconstruction of deformable (or non-rigid) scenes from a set of monocular 2D image observations is a long-standing and actively researched area of computer vision and graphics. It is an ill-posed inverse problem, since--without additional prior assumptions--it permits infinitely many solutions leading to accurate projection to the input 2D images. Non-rigid reconstruction is a foundational building block for downstream applications like robotics, AR/VR, or visual content creation. The key advantage of using monocular cameras is their omnipresence and availability to the end users as well as their ease of use compared to more sophisticated camera set-ups such as stereo or multi-view systems. This survey focuses on state-of-the-art methods for dense non-rigid 3D reconstruction of various deformable objects and composite scenes from monocular videos or sets of monocular views. It reviews the fundamentals of 3D reconstruction and deformation modeling from 2D image observations. We then start from general methods--that handle arbitrary scenes and make only a few prior assumptions--and proceed towards techniques making stronger assumptions about the observed objects and types of deformations (e.g. human faces, bodies, hands, and animals). A significant part of this STAR is also devoted to classification and a high-level comparison of the methods, as well as an overview of the datasets for training and evaluation of the discussed techniques. We conclude by discussing open challenges in the field and the social aspects associated with the usage of the reviewed methods.
Manifold Modeling in Quotient Space: Learning An Invariant Mapping with Decodability of Image Patches
Mar 10, 2022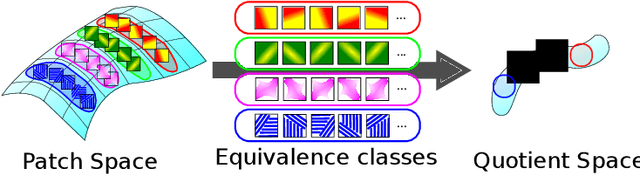
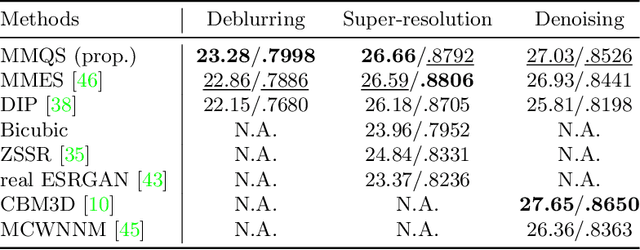
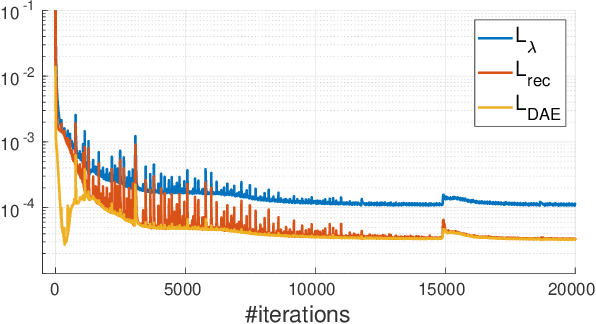
This study proposes a framework for manifold learning of image patches using the concept of equivalence classes: manifold modeling in quotient space (MMQS). In MMQS, we do not consider a set of local patches of the image as it is, but rather the set of their canonical patches obtained by introducing the concept of equivalence classes and performing manifold learning on their canonical patches. Canonical patches represent equivalence classes, and their auto-encoder constructs a manifold in the quotient space. Based on this framework, we produce a novel manifold-based image model by introducing rotation-flip-equivalence relations. In addition, we formulate an image reconstruction problem by fitting the proposed image model to a corrupted observed image and derive an algorithm to solve it. Our experiments show that the proposed image model is effective for various self-supervised image reconstruction tasks, such as image inpainting, deblurring, super-resolution, and denoising.
Image Classification on Accelerated Neural Networks
Mar 21, 2022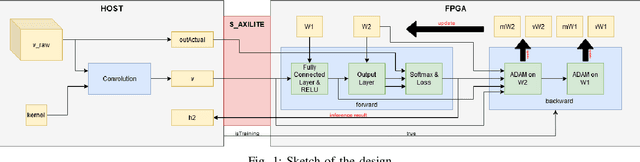
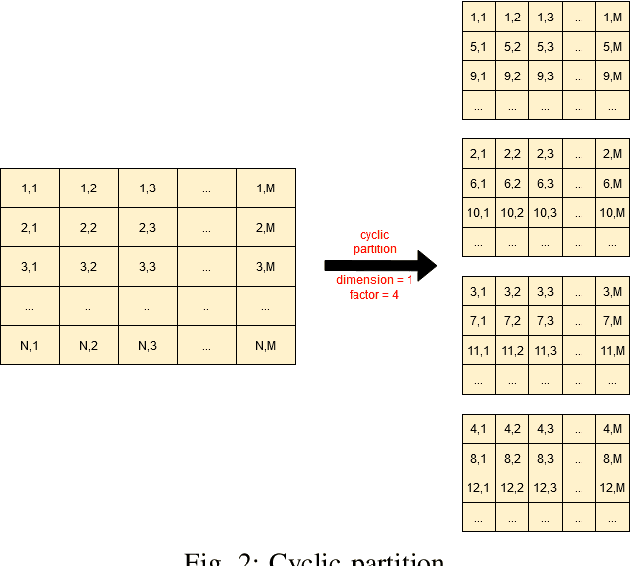
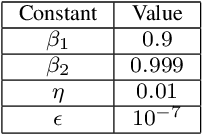
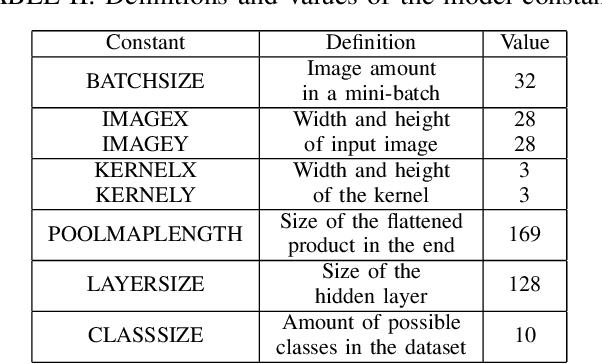
For image classification problems, various neural network models are commonly used due to their success in yielding high accuracies. Convolutional Neural Network (CNN) is one of the most frequently used deep learning methods for image classification applications. It may produce extraordinarily accurate results with regard to its complexity. However, the more complex the model is the longer it takes to train. In this paper, an acceleration design that uses the power of FPGA is given for a basic CNN model which consists of one convolutional layer and one fully connected layer for the training phase of the fully connected layer. Nonetheless, inference phase is also accelerated automatically due to the fact that training phase includes inference. In this design, the convolutional layer is calculated by the host computer and the fully connected layer is calculated by an FPGA board. It should be noted that the training of convolutional layer is not taken into account in this design and is left for future research. The results are quite encouraging as this FPGA design tops the performance of some of the state-of-the-art deep learning platforms such as Tensorflow on the host computer approximately 2 times in both training and inference.
Just a Matter of Scale? Reevaluating Scale Equivariance in Convolutional Neural Networks
Nov 18, 2022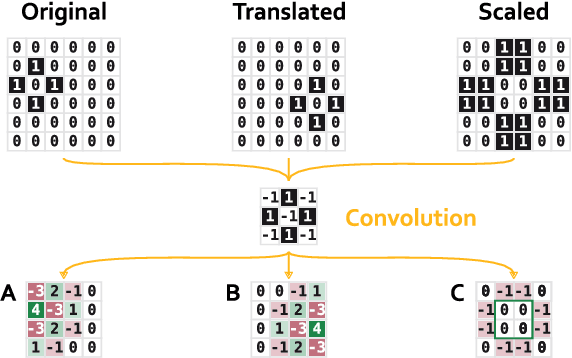

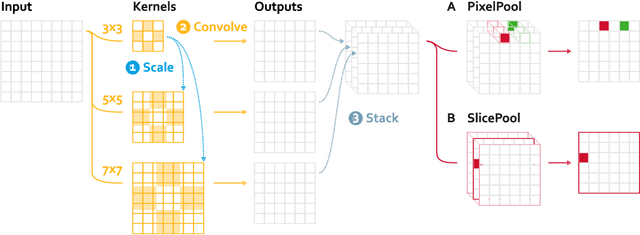
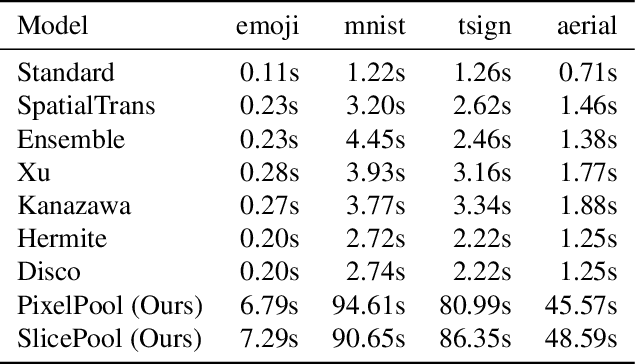
The widespread success of convolutional neural networks may largely be attributed to their intrinsic property of translation equivariance. However, convolutions are not equivariant to variations in scale and fail to generalize to objects of different sizes. Despite recent advances in this field, it remains unclear how well current methods generalize to unobserved scales on real-world data and to what extent scale equivariance plays a role. To address this, we propose the novel Scaled and Translated Image Recognition (STIR) benchmark based on four different domains. Additionally, we introduce a new family of models that applies many re-scaled kernels with shared weights in parallel and then selects the most appropriate one. Our experimental results on STIR show that both the existing and proposed approaches can improve generalization across scales compared to standard convolutions. We also demonstrate that our family of models is able to generalize well towards larger scales and improve scale equivariance. Moreover, due to their unique design we can validate that kernel selection is consistent with input scale. Even so, none of the evaluated models maintain their performance for large differences in scale, demonstrating that a general understanding of how scale equivariance can improve generalization and robustness is still lacking.