 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Need for Neural ISP in the Small-Pixel Era: How Shrinking Pixels Push Optics to the Limit and Neural Restoration Pushes Back
Jun 04, 2026Smartphone telephoto cameras are approaching a "telephoto physics wall": as pixel pitches shrink toward sub-0.5 micron, the optics remain limited by geometric aberrations, leading to diminishing returns on resolution. Traditional Image Signal Processors (ISPs) cannot eliminate these aberrations, because they operate through local, stage-wise processing with no explicit model of the underlying point spread function (PSF). We demonstrate how a learning-based Neural ISP for image restoration, trained on the underlying degradations, inverts what stage-wise pipelines cannot, turning small-pixel designs into a net advantage. We investigate this through a controlled simulation of a representative telephoto module, evaluating five configurations (0.35--0.75 micron pixel pitch). The aperture is scaled proportionally to keep per-pixel SNR and diffraction spot size fixed, thereby isolating geometric aberration and spatial sampling. While the traditional ISP improves only modestly with smaller pixels, the Neural ISP scales substantially: at 0.35 micron} it reaches 745 cycles/mm MTF50 (vertical), a 2.5--3x resolution improvement over the traditional ISP, and LPIPS improves significantly from 0.244 to 0.151 while traditional results stay comparatively flat. In a low-SNR extension (15 dB per-frame bursts at 0.35 micron), a multi-frame Neural ISP recovers performance close to the bright-light single-frame baseline, whereas a multi-frame traditional ISP shows no meaningful improvement -- indicating that traditional pipelines at small pixels are bottlenecked by uncorrected PSF blur rather than by noise. These results point to a design philosophy in which Neural ISPs enable high-resolution telephoto modules by correcting residual optical aberrations rather than requiring increasingly complex optics.
Learning by Hallucinating: Vision-Language Pre-training with Weak Supervision
Oct 27, 2022



Weakly-supervised vision-language (V-L) pre-training (W-VLP) aims at learning cross-modal alignment with little or no paired data, such as aligned images and captions. Recent W-VLP methods, which pair visual features with object tags, help achieve performances comparable with some VLP models trained with aligned pairs in various V-L downstream tasks. This, however, is not the case in cross-modal retrieval (XMR). We argue that the learning of such a W-VLP model is curbed and biased by the object tags of limited semantics. We address the lack of paired V-L data for model supervision with a novel Visual Vocabulary based Feature Hallucinator (WFH), which is trained via weak supervision as a W-VLP model, not requiring images paired with captions. WFH generates visual hallucinations from texts, which are then paired with the originally unpaired texts, allowing more diverse interactions across modalities. Empirically, WFH consistently boosts the prior W-VLP works, e.g. U-VisualBERT (U-VB), over a variety of V-L tasks, i.e. XMR, Visual Question Answering, etc. Notably, benchmarked with recall@{1,5,10}, it consistently improves U-VB on image-to-text and text-to-image retrieval on two popular datasets Flickr30K and MSCOCO. Meanwhile, it gains by at least 14.5% in cross-dataset generalization tests on these XMR tasks. Moreover, in other V-L downstream tasks considered, our WFH models are on par with models trained with paired V-L data, revealing the utility of unpaired data. These results demonstrate greater generalization of the proposed W-VLP model with WFH.
OrigamiNet: Weakly-Supervised, Segmentation-Free, One-Step, Full Page Text Recognition by learning to unfold
Jun 12, 2020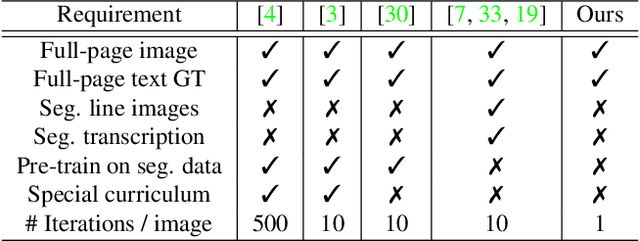
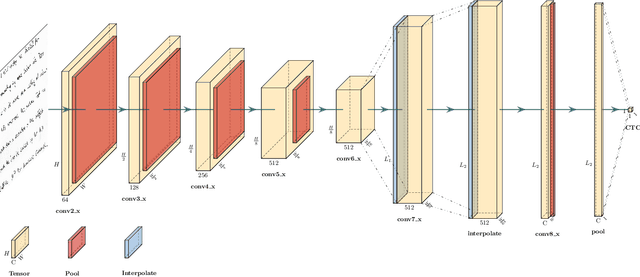
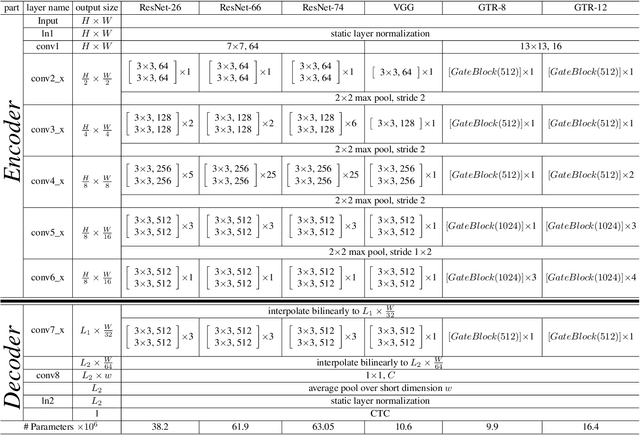

Text recognition is a major computer vision task with a big set of associated challenges. One of those traditional challenges is the coupled nature of text recognition and segmentation. This problem has been progressively solved over the past decades, going from segmentation based recognition to segmentation free approaches, which proved more accurate and much cheaper to annotate data for. We take a step from segmentation-free single line recognition towards segmentation-free multi-line / full page recognition. We propose a novel and simple neural network module, termed \textbf{OrigamiNet}, that can augment any CTC-trained, fully convolutional single line text recognizer, to convert it into a multi-line version by providing the model with enough spatial capacity to be able to properly collapse a 2D input signal into 1D without losing information. Such modified networks can be trained using exactly their same simple original procedure, and using only \textbf{unsegmented} image and text pairs. We carry out a set of interpretability experiments that show that our trained models learn an accurate implicit line segmentation. We achieve state-of-the-art character error rate on both IAM \& ICDAR 2017 HTR benchmarks for handwriting recognition, surpassing all other methods in the literature. On IAM we even surpass single line methods that use accurate localization information during training. Our code is available online at \url{https://github.com/IntuitionMachines/OrigamiNet}.
Learning to hash with semantic similarity metrics and empirical KL divergence
May 11, 2020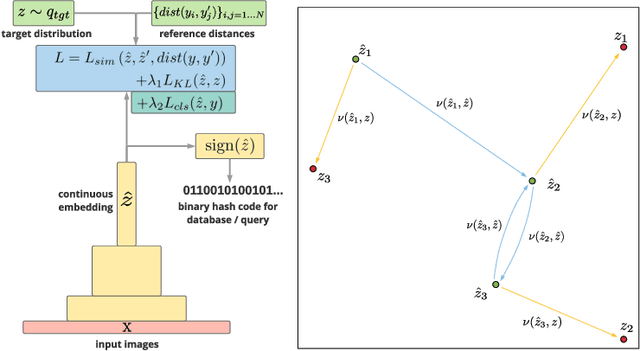

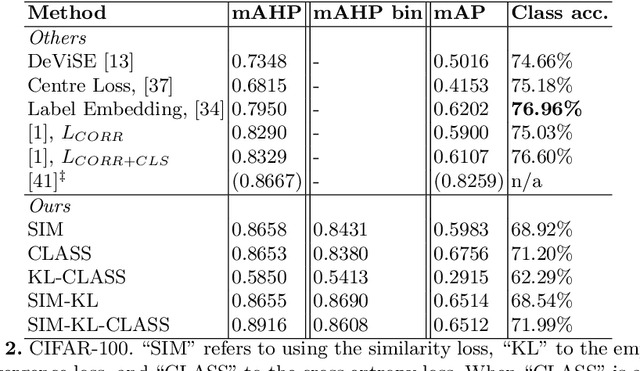
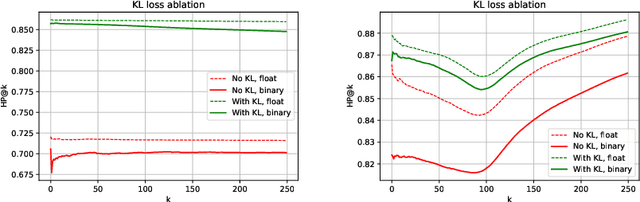
Learning to hash is an efficient paradigm for exact and approximate nearest neighbor search from massive databases. Binary hash codes are typically extracted from an image by rounding output features from a CNN, which is trained on a supervised binary similar/ dissimilar task. Drawbacks of this approach are: (i) resulting codes do not necessarily capture semantic similarity of the input data (ii) rounding results in information loss, manifesting as decreased retrieval performance and (iii) Using only class-wise similarity as a target can lead to trivial solutions, simply encoding classifier outputs rather than learning more intricate relations, which is not detected by most performance metrics. We overcome (i) via a novel loss function encouraging the relative hash code distances of learned features to match those derived from their targets. We address (ii) via a differentiable estimate of the KL divergence between network outputs and a binary target distribution, resulting in minimal information loss when the features are rounded to binary. Finally, we resolve (iii) by focusing on a hierarchical precision metric. Efficiency of the methods is demonstrated with semantic image retrieval on the CIFAR-100, ImageNet and Conceptual Captions datasets, using similarities inferred from the WordNet label hierarchy or sentence embeddings.