 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Logical Operations for Arbitrary Quantum Error Correction Codes
May 27, 2026Logical operations are essential for quantum computation within quantum error-correcting codes. However, discovering their physical realizations is challenging, especially for non-additive codes that lack a stabilizer description. We present a general learning-based framework that, given only an encoding circuit, constructs physical implementations of logical operations while enforcing structural properties such as transversality or shallow depth. Our approach is validated by rediscovering known logical operations of standard stabilizer codes. We then extend it to a co-design procedure, dubbed variational early fault-tolerant quantum computing (VarEFTQC), which tailors non-additive encodings to a given noise model and enforces desired logical gate sets, such as transversal IQP-type families or low-depth universal sets. A software library implements the complete learning pipeline, including loss-function variants, ansatz families, and optimization routines. Together, these results position VarEFTQC as a practical tool for discovering hardware-adapted logical gadgets for early fault-tolerant quantum computing.
GenAI for Energy-Efficient and Interference-Aware Compressed Sensing of GNSS Signals on a Google Edge TPU
May 14, 2026Traditional methods for classifying global navigation satellite system (GNSS) jamming signals typically involve post-processing raw or spectral data streams, requiring complex and costly data transmission to cloud-based interference classification systems. In contrast, our proposed approach efficiently compresses GNSS data streams directly at the hardware receiver while simultaneously classifying jamming and spoofing attacks in real time. Given the growing prevalence of GNSS jamming, there is a critical need for real-time solutions suitable for power-constrained environments. This paper introduces a novel method for compressing and classifying GNSS jamming threats using generative artificial intelligence (GenAI), specifically variational autoencoders (VAEs), deployed on Google Edge tensor processing units (TPUs). The study evaluates various autoencoder (AE) architectures to compress and reconstruct GNSS signals, focusing on preserving interference characteristics while minimizing data size near the receiver hardware. The pipeline adapts large-scale AE models for Google Edge TPUs through 8-bit quantization to ensure energy-efficient deployment. Tests on raw in-phase and quadrature-phase (IQ) data, Fast Fourier Transform (FFT) data, and handcrafted features show the system achieves significant compression (>42x) and accurate classification of approximately 72 interference types on reconstructed signals (F2-score 0.915), closely matching the original signals (F2-score 0.923). The hardware-centric GenAI approach also substantially reduces jammer signal transmission costs, offering a practical solution for interference mitigation. Ablation studies on conditional and factorized VAEs (i.e., FactorVAE) explore latent feature disentanglement for data generation, enhancing model interpretability and fostering trust in machine learning (ML) solutions for sensitive interference applications.
* 12 pages
Exploitation of Hidden Context in Dynamic Movement Forecasting: A Neural Network Journey from Recurrent to Graph Neural Networks and General Purpose Transformers
May 14, 2026Forecasting within signal processing pipelines is crucial for mitigating delays, particularly in predicting the dynamic movements of objects such as NBA players. This task poses significant challenges due to the inherently interactive and unpredictable nature of sports, where abrupt changes in velocity and direction are prevalent. Traditional approaches, including (S)ARIMA(X), Kalman filters (KF), and Particle filters (PF), often struggle to model the non-linear dynamics present in such scenarios. Machine learning (ML) methods, such as long short-term memory (LSTM) networks, graph neural networks (GNNs), and Transformers, offer greater flexibility and accuracy but frequently fail to explicitly capture the interplay between temporal dependencies and contextual interactions, which are critical in chaotic sports environments. In this paper, we evaluate these models and assess their strengths and weaknesses. Experimental results reveal key performance trade-offs across input history length, generalizability, and the ability to incorporate contextual information. ML-based methods demonstrated substantial improvements over linear models across forecast horizons of up to 2s. Among the tested architectures, our hybrid LSTM augmented with contextual information achieved the lowest final displacement error (FDE) of 1.51m, outperforming temporal convolutional neural network (TCNN), graph attention network (GAT), and Transformers, while also requiring less data and training time compared to GAT and Transformers. Our findings indicate that no single architecture excels across all metrics, emphasizing the need for task-specific considerations in trajectory prediction for fast-paced, dynamic environments such as NBA gameplay.
* 12 pages
Active Sensing with Meta-Reinforcement Learning for Emitter Localization from RF Observations
May 12, 2026Global navigation satellite system (GNSS) interference poses a serious threat to reliable positioning, especially in indoor and multipath-rich environments where source localization is highly challenging. In this paper, we formulate GNSS interference localization as an active sensing problem and propose a reinforcement learning (RL) framework in which an agent sequentially explores the environment to infer the position of an emitter source from radio frequency (RF) observations acquired with a 2x2 patch antenna. The localization task is modeled as a partially observable decision process, since single-snapshot measurements are often ambiguous under multipath propagation and changing channel conditions. To address this, the proposed framework combines high-dimensional RF sensing with deep RL and recurrent policy learning. We investigate both value-based and policy-based approaches, namely Deep Q-Networks (DQN) and Proximal Policy Optimization (PPO), and study their behavior under domain shift. The approach is evaluated on a simulated dataset generated with the Sionna ray-tracing module, which provides realistic propagation effects and diverse environment configurations. Experimental results show that the proposed method achieves a localization success rate of 80.1%, demonstrating the potential of RL for adaptive GNSS interference localization. Overall, the results highlight simulation-assisted training as a promising direction for robust interference localization in challenging propagation environments.
Learning to Concatenate Quantum Codes
Apr 16, 2026Concatenating quantum error correction codes scales error correction capability by driving logical error rates down double-exponentially across levels. However, the noise structure shifts under concatenation, making it hard to choose an optimal code sequence. We automate this choice by estimating the effective noise channel after each level and selecting the next code accordingly. In particular, we use learning-based methods to tailor small, non-additive encoders when the noise exhibits sufficient structure, then switch to standard codes once the noise is nearly uniform. In simulations, this level-wise adaptation achieves a target logical error rate with far fewer qubits than concatenating stabilizer codes alone--reducing qubit counts by up to two orders of magnitude for strongly structured noise. Therefore, this hybrid, learning-based strategy offers a promising tool for early fault-tolerant quantum computing.
Resilient Channel Charting Under Varying Radio Link Availability
Feb 04, 2026Channel charting (CC) has become a key technology for RF-based localization, enabling unsupervised radio fingerprinting, even in non line of sight scenarios, with a minimum of reference position labels. However, most CC models assume fixed-size inputs, such as a constant number of antennas or channel measurements. In practical systems, antennas may fail, signals may be blocked, or antenna sets may change during handovers, making fixed-input architectures fragile. Existing radio-fingerprinting approaches address this by training separate models for each antenna configuration, but the resulting training effort scales prohibitively with the array size. We propose Adaptive Positioning (AdaPos), a CC architecture that natively handles variable numbers of channel measurements. AdaPos combines convolutional feature extraction with a transformer-based encoder using learnable antenna identifiers and self-attention to fuse arbitrary subsets of CSI inputs. Experiments on two public real-world datasets (SISO and MIMO) show that AdaPos maintains state-of-the-art accuracy under missing-antenna conditions and replaces roughly 57 configuration-specific models with a single unified model. With AdaPos and our novel training strategies, we provide resilience to both individual antenna failures and full-array outages.
Learning Encodings by Maximizing State Distinguishability: Variational Quantum Error Correction
Jun 13, 2025



Quantum error correction is crucial for protecting quantum information against decoherence. Traditional codes like the surface code require substantial overhead, making them impractical for near-term, early fault-tolerant devices. We propose a novel objective function for tailoring error correction codes to specific noise structures by maximizing the distinguishability between quantum states after a noise channel, ensuring efficient recovery operations. We formalize this concept with the distinguishability loss function, serving as a machine learning objective to discover resource-efficient encoding circuits optimized for given noise characteristics. We implement this methodology using variational techniques, termed variational quantum error correction (VarQEC). Our approach yields codes with desirable theoretical and practical properties and outperforms standard codes in various scenarios. We also provide proof-of-concept demonstrations on IBM and IQM hardware devices, highlighting the practical relevance of our procedure.
Position Paper: Rethinking AI/ML for Air Interface in Wireless Networks
Jun 13, 2025AI/ML research has predominantly been driven by domains such as computer vision, natural language processing, and video analysis. In contrast, the application of AI/ML to wireless networks, particularly at the air interface, remains in its early stages. Although there are emerging efforts to explore this intersection, fully realizing the potential of AI/ML in wireless communications requires a deep interdisciplinary understanding of both fields. We provide an overview of AI/ML-related discussions in 3GPP standardization, highlighting key use cases, architectural considerations, and technical requirements. We outline open research challenges and opportunities where academic and industrial communities can contribute to shaping the future of AI-enabled wireless systems.
5G-DIL: Domain Incremental Learning with Similarity-Aware Sampling for Dynamic 5G Indoor Localization
May 23, 2025Indoor positioning based on 5G data has achieved high accuracy through the adoption of recent machine learning (ML) techniques. However, the performance of learning-based methods degrades significantly when environmental conditions change, thereby hindering their applicability to new scenarios. Acquiring new training data for each environmental change and fine-tuning ML models is both time-consuming and resource-intensive. This paper introduces a domain incremental learning (DIL) approach for dynamic 5G indoor localization, called 5G-DIL, enabling rapid adaptation to environmental changes. We present a novel similarity-aware sampling technique based on the Chebyshev distance, designed to efficiently select specific exemplars from the previous environment while training only on the modified regions of the new environment. This avoids the need to train on the entire region, significantly reducing the time and resources required for adaptation without compromising localization accuracy. This approach requires as few as 50 exemplars from adaptation domains, significantly reducing training time while maintaining high positioning accuracy in previous environments. Comparative evaluations against state-of-the-art DIL techniques on a challenging real-world indoor dataset demonstrate the effectiveness of the proposed sample selection method. Our approach is adaptable to real-world non-line-of-sight propagation scenarios and achieves an MAE positioning error of 0.261 meters, even under dynamic environmental conditions. Code: https://gitlab.cc-asp.fraunhofer.de/5g-pos/5g-dil
Simplicity is Key: An Unsupervised Pretraining Approach for Sparse Radio Channels
May 19, 2025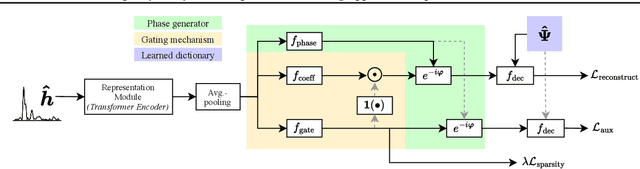

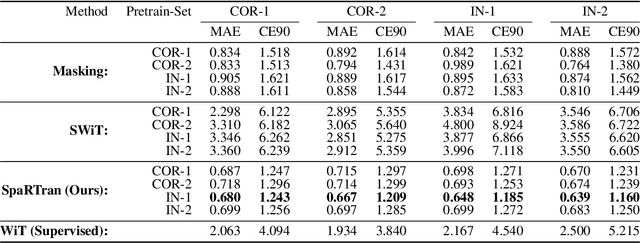
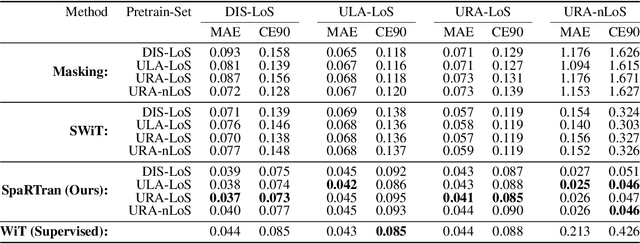
We introduce the Sparse pretrained Radio Transformer (SpaRTran), an unsupervised representation learning approach based on the concept of compressed sensing for radio channels. Our approach learns embeddings that focus on the physical properties of radio propagation, to create the optimal basis for fine-tuning on radio-based downstream tasks. SpaRTran uses a sparse gated autoencoder that induces a simplicity bias to the learned representations, resembling the sparse nature of radio propagation. For signal reconstruction, it learns a dictionary that holds atomic features, which increases flexibility across signal waveforms and spatiotemporal signal patterns. Our experiments show that SpaRTran reduces errors by up to 85 % compared to state-of-the-art methods when fine-tuned on radio fingerprinting, a challenging downstream task. In addition, our method requires less pretraining effort and offers greater flexibility, as we train it solely on individual radio signals. SpaRTran serves as an excellent base model that can be fine-tuned for various radio-based downstream tasks, effectively reducing the cost for labeling. In addition, it is significantly more versatile than existing methods and demonstrates superior generalization.