 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeConvEns: Convolutional Ensemble Learning for Edge Intelligence
Jul 25, 2023Deep edge intelligence aims to deploy deep learning models that demand computationally expensive training in the edge network with limited computational power. Moreover, many deep edge intelligence applications require handling distributed data that cannot be transferred to a central server due to privacy concerns. Decentralized learning methods, such as federated learning, offer solutions where models are learned collectively by exchanging learned weights. However, they often require complex models that edge devices may not handle and multiple rounds of network communication to achieve state-of-the-art performances. This study proposes a convolutional ensemble learning approach, coined EdgeConvEns, that facilitates training heterogeneous weak models on edge and learning to ensemble them where data on edge are heterogeneously distributed. Edge models are implemented and trained independently on Field-Programmable Gate Array (FPGA) devices with various computational capacities. Learned data representations are transferred to a central server where the ensemble model is trained with the learned features received from the edge devices to boost the overall prediction performance. Extensive experiments demonstrate that the EdgeConvEns can outperform the state-of-the-art performance with fewer communications and less data in various training scenarios.
Common Subexpression-based Compression and Multiplication of Sparse Constant Matrices
Mar 26, 2023In deep learning inference, model parameters are pruned and quantized to reduce the model size. Compression methods and common subexpression (CSE) elimination algorithms are applied on sparse constant matrices to deploy the models on low-cost embedded devices. However, the state-of-the-art CSE elimination methods do not scale well for handling large matrices. They reach hours for extracting CSEs in a $200 \times 200$ matrix while their matrix multiplication algorithms execute longer than the conventional matrix multiplication methods. Besides, there exist no compression methods for matrices utilizing CSEs. As a remedy to this problem, a random search-based algorithm is proposed in this paper to extract CSEs in the column pairs of a constant matrix. It produces an adder tree for a $1000 \times 1000$ matrix in a minute. To compress the adder tree, this paper presents a compression format by extending the Compressed Sparse Row (CSR) to include CSEs. While compression rates of more than $50\%$ can be achieved compared to the original CSR format, simulations for a single-core embedded system show that the matrix multiplication execution time can be reduced by $20\%$.
Image Classification on Accelerated Neural Networks
Mar 21, 2022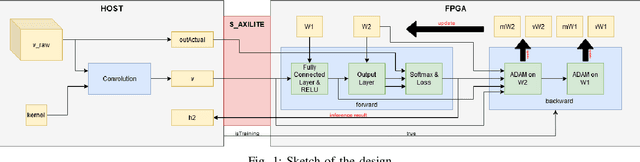
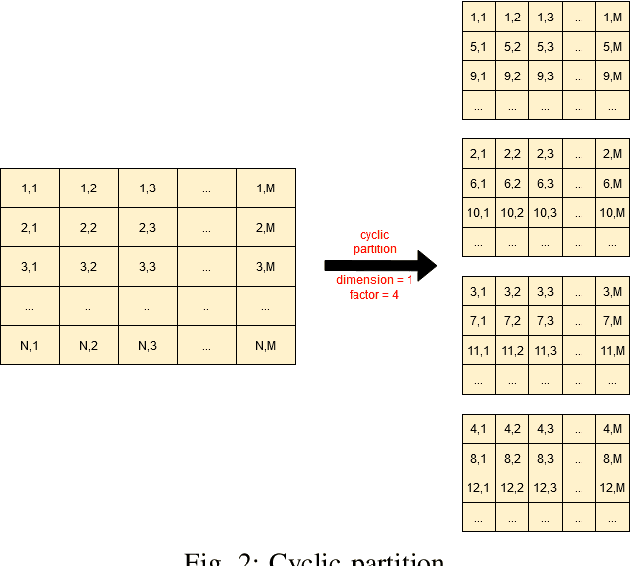
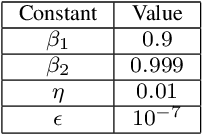
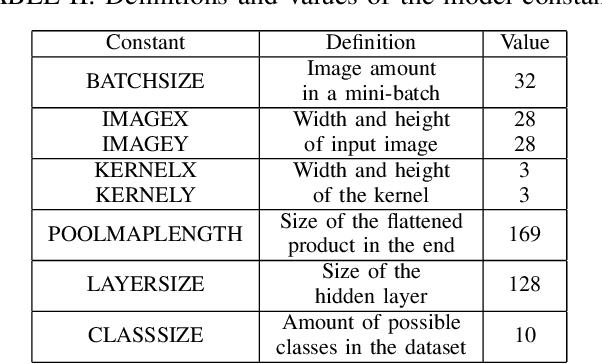
For image classification problems, various neural network models are commonly used due to their success in yielding high accuracies. Convolutional Neural Network (CNN) is one of the most frequently used deep learning methods for image classification applications. It may produce extraordinarily accurate results with regard to its complexity. However, the more complex the model is the longer it takes to train. In this paper, an acceleration design that uses the power of FPGA is given for a basic CNN model which consists of one convolutional layer and one fully connected layer for the training phase of the fully connected layer. Nonetheless, inference phase is also accelerated automatically due to the fact that training phase includes inference. In this design, the convolutional layer is calculated by the host computer and the fully connected layer is calculated by an FPGA board. It should be noted that the training of convolutional layer is not taken into account in this design and is left for future research. The results are quite encouraging as this FPGA design tops the performance of some of the state-of-the-art deep learning platforms such as Tensorflow on the host computer approximately 2 times in both training and inference.