 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMA: From Surface Observations to Muscle Anatomy
Jun 08, 2026With the growing demand for realistic virtual humans, parametric body models have become a cornerstone of modern medicine, sports, and entertainment applications. However, most of these models are inherently limited: they only capture the 3D surface of the skin, offering no insight into the complex bio-mechanical structures that generate motion. As more applications expand towards biomechanics, the need for virtual human models that go beyond the skin has become increasingly evident. Traditional soft-tissue simulations, such as FEM, are accurate but non-scalable and too computationally expensive for most common applications. Alternatively, existing biomechanical tools can simulate muscular forces and activations, but do not model changes in external shape, restricting how activations correlate with actual observable anatomy. This motivates a novel inverse research problem: recovering muscle deformations directly from visible surface observations - i.e., from the skin, and thus the pose. In this work, we present SOMA (from Surface Observations to Muscle Anatomy), a person-specific model that infers spatio-temporal muscle behavior from surface signals obtained using RGB cameras, and SKIM, a subject-specific soft-tissue deformation dataset. To the best of our knowledge, this is the first method that attempts to recover muscle deformations from multi-view RGB data. We show how our method provides anatomically grounded animations without the complexity of traditional simulations, leading to a scalable and cost-effective solution. Data and code are available.
EgoRelight: Egocentric Human Capture and Illumination Recovery for Relightable and Photoreal Avatar Rendering
May 27, 2026Mixed Reality (MR) headsets promise a future of immersive telepresence where virtual humans blend indistinguishably into real or virtual surroundings. Achieving this vision requires a method for capturing a user's motion, estimating appearance under novel lighting, and understanding the environment - all from the constrained viewpoint of a head-mounted display (HMD). Existing approaches treat these as isolated problems: they either focus on driving avatars with baked-in lighting or rely on studio setups for relighting. In this paper, we present EgoRelight, a holistic framework for egocentric telepresence that simultaneously captures full-body human performance, synthesizes photorealistic and relightable appearance, and estimates high dynamic range (HDR) environment maps from a single HMD. First, to ensure motion and surface reconstruction, we propose an egocentric perception module that leverages stereo down-facing cameras to extract dense depth maps, which serve as geometric control signals to drive a mesh-based avatar. Second, we introduce a novel neural appearance model that learns to synthesize view-dependent specular and view-independent diffuse shading separately. By employing a specialized ray-sampling strategy, our model generalizes to unseen illumination without relying on restrictive analytical BRDF priors. Third, we enable seamless avatar integration into the physical world via a test-time inverse rendering process, which recovers an HDR environment map by matching the pre-trained avatar's appearance to live egocentric camera observations. We demonstrate our system through a social telepresence application, where remote users are coherently relit according to their physical environment. Extensive experiments show that our components and the integrated system significantly outperform state-of-the-art baselines in geometric accuracy and rendering as well as relighting fidelity.
MUA: Mobile Ultra-detailed Animatable Avatars
Apr 20, 2026Building photorealistic, animatable full-body digital humans remains a longstanding challenge in computer graphics and vision. Recent advances in animatable avatar modeling have largely progressed along two directions: improving the fidelity of dynamic geometry and appearance, or reducing computational complexity to enable deployment on resource-constrained platforms, e.g., VR headsets. However, existing approaches fail to achieve both goals simultaneously: Ultra-high-fidelity avatars typically require substantial computation on server-class GPUs, whereas lightweight avatars often suffer from limited surface dynamics, reduced appearance details, and noticeable artifacts. To bridge this gap, we propose a novel animatable avatar representation, termed Wavelet-guided Multi-level Spatial Factorized Blendshapes, and a corresponding distillation pipeline that transfers motion-aware clothing dynamics and fine-grained appearance details from a pre-trained ultra-high-quality avatar model into a compact, efficient representation. By coupling multi-level wavelet spectral decomposition with low-rank structural factorization in texture space, our method achieves up to 2000X lower computational cost and a 10X smaller model size than the original high-quality teacher avatar model, while preserving visually plausible dynamics and appearance details closely resemble those of the teacher model. Extensive comparisons with state-of-the-art methods show that our approach significantly outperforms existing avatar approaches designed for mobile settings and achieves comparable or superior rendering quality to most approaches that can only run on servers. Importantly, our representation substantially improves the practicality of high-fidelity avatars for immersive applications, achieving over 180 FPS on a desktop PC and real-time native on-device performance at 24 FPS on a standalone Meta Quest 3.
HGGT: Robust and Flexible 3D Hand Mesh Reconstruction from Uncalibrated Images
Mar 25, 2026Recovering high-fidelity 3D hand geometry from images is a critical task in computer vision, holding significant value for domains such as robotics, animation and VR/AR. Crucially, scalable applications demand both accuracy and deployment flexibility, requiring the ability to leverage massive amounts of unstructured image data from the internet or enable deployment on consumer-grade RGB cameras without complex calibration. However, current methods face a dilemma. While single-view approaches are easy to deploy, they suffer from depth ambiguity and occlusion. Conversely, multi-view systems resolve these uncertainties but typically demand fixed, calibrated setups, limiting their real-world utility. To bridge this gap, we draw inspiration from 3D foundation models that learn explicit geometry directly from visual data. By reformulating hand reconstruction from arbitrary views as a visual-geometry grounded task, we propose a feed-forward architecture that, for the first time in literature, jointly infers 3D hand meshes and camera poses from uncalibrated views. Extensive evaluations show that our approach outperforms state-of-the-art benchmarks and demonstrates strong generalization to uncalibrated, in-the-wild scenarios. Here is the link of our project page: https://lym29.github.io/HGGT/.
DInf-Grid: A Neural Differential Equation Solver with Differentiable Feature Grids
Jan 15, 2026We present a novel differentiable grid-based representation for efficiently solving differential equations (DEs). Widely used architectures for neural solvers, such as sinusoidal neural networks, are coordinate-based MLPs that are both computationally intensive and slow to train. Although grid-based alternatives for implicit representations (e.g., Instant-NGP and K-Planes) train faster by exploiting signal structure, their reliance on linear interpolation restricts their ability to compute higher-order derivatives, rendering them unsuitable for solving DEs. Our approach overcomes these limitations by combining the efficiency of feature grids with radial basis function interpolation, which is infinitely differentiable. To effectively capture high-frequency solutions and enable stable and faster computation of global gradients, we introduce a multi-resolution decomposition with co-located grids. Our proposed representation, DInf-Grid, is trained implicitly using the differential equations as loss functions, enabling accurate modelling of physical fields. We validate DInf-Grid on a variety of tasks, including the Poisson equation for image reconstruction, the Helmholtz equation for wave fields, and the Kirchhoff-Love boundary value problem for cloth simulation. Our results demonstrate a 5-20x speed-up over coordinate-based MLP-based methods, solving differential equations in seconds or minutes while maintaining comparable accuracy and compactness.
RelightAnyone: A Generalized Relightable 3D Gaussian Head Model
Jan 06, 20263D Gaussian Splatting (3DGS) has become a standard approach to reconstruct and render photorealistic 3D head avatars. A major challenge is to relight the avatars to match any scene illumination. For high quality relighting, existing methods require subjects to be captured under complex time-multiplexed illumination, such as one-light-at-a-time (OLAT). We propose a new generalized relightable 3D Gaussian head model that can relight any subject observed in a single- or multi-view images without requiring OLAT data for that subject. Our core idea is to learn a mapping from flat-lit 3DGS avatars to corresponding relightable Gaussian parameters for that avatar. Our model consists of two stages: a first stage that models flat-lit 3DGS avatars without OLAT lighting, and a second stage that learns the mapping to physically-based reflectance parameters for high-quality relighting. This two-stage design allows us to train the first stage across diverse existing multi-view datasets without OLAT lighting ensuring cross-subject generalization, where we learn a dataset-specific lighting code for self-supervised lighting alignment. Subsequently, the second stage can be trained on a significantly smaller dataset of subjects captured under OLAT illumination. Together, this allows our method to generalize well and relight any subject from the first stage as if we had captured them under OLAT lighting. Furthermore, we can fit our model to unseen subjects from as little as a single image, allowing several applications in novel view synthesis and relighting for digital avatars.
Step2Motion: Locomotion Reconstruction from Pressure Sensing Insoles
Oct 26, 2025Human motion is fundamentally driven by continuous physical interaction with the environment. Whether walking, running, or simply standing, the forces exchanged between our feet and the ground provide crucial insights for understanding and reconstructing human movement. Recent advances in wearable insole devices offer a compelling solution for capturing these forces in diverse, real-world scenarios. Sensor insoles pose no constraint on the users' motion (unlike mocap suits) and are unaffected by line-of-sight limitations (in contrast to optical systems). These qualities make sensor insoles an ideal choice for robust, unconstrained motion capture, particularly in outdoor environments. Surprisingly, leveraging these devices with recent motion reconstruction methods remains largely unexplored. Aiming to fill this gap, we present Step2Motion, the first approach to reconstruct human locomotion from multi-modal insole sensors. Our method utilizes pressure and inertial data-accelerations and angular rates-captured by the insoles to reconstruct human motion. We evaluate the effectiveness of our approach across a range of experiments to show its versatility for diverse locomotion styles, from simple ones like walking or jogging up to moving sideways, on tiptoes, slightly crouching, or dancing.
Hyper Diffusion Avatars: Dynamic Human Avatar Generation using Network Weight Space Diffusion
Sep 04, 2025Creating human avatars is a highly desirable yet challenging task. Recent advancements in radiance field rendering have achieved unprecedented photorealism and real-time performance for personalized dynamic human avatars. However, these approaches are typically limited to person-specific rendering models trained on multi-view video data for a single individual, limiting their ability to generalize across different identities. On the other hand, generative approaches leveraging prior knowledge from pre-trained 2D diffusion models can produce cartoonish, static human avatars, which are animated through simple skeleton-based articulation. Therefore, the avatars generated by these methods suffer from lower rendering quality compared to person-specific rendering methods and fail to capture pose-dependent deformations such as cloth wrinkles. In this paper, we propose a novel approach that unites the strengths of person-specific rendering and diffusion-based generative modeling to enable dynamic human avatar generation with both high photorealism and realistic pose-dependent deformations. Our method follows a two-stage pipeline: first, we optimize a set of person-specific UNets, with each network representing a dynamic human avatar that captures intricate pose-dependent deformations. In the second stage, we train a hyper diffusion model over the optimized network weights. During inference, our method generates network weights for real-time, controllable rendering of dynamic human avatars. Using a large-scale, cross-identity, multi-view video dataset, we demonstrate that our approach outperforms state-of-the-art human avatar generation methods.
Physics-based Human Pose Estimation from a Single Moving RGB Camera
Jul 23, 2025Most monocular and physics-based human pose tracking methods, while achieving state-of-the-art results, suffer from artifacts when the scene does not have a strictly flat ground plane or when the camera is moving. Moreover, these methods are often evaluated on in-the-wild real world videos without ground-truth data or on synthetic datasets, which fail to model the real world light transport, camera motion, and pose-induced appearance and geometry changes. To tackle these two problems, we introduce MoviCam, the first non-synthetic dataset containing ground-truth camera trajectories of a dynamically moving monocular RGB camera, scene geometry, and 3D human motion with human-scene contact labels. Additionally, we propose PhysDynPose, a physics-based method that incorporates scene geometry and physical constraints for more accurate human motion tracking in case of camera motion and non-flat scenes. More precisely, we use a state-of-the-art kinematics estimator to obtain the human pose and a robust SLAM method to capture the dynamic camera trajectory, enabling the recovery of the human pose in the world frame. We then refine the kinematic pose estimate using our scene-aware physics optimizer. From our new benchmark, we found that even state-of-the-art methods struggle with this inherently challenging setting, i.e. a moving camera and non-planar environments, while our method robustly estimates both human and camera poses in world coordinates.
EVA: Expressive Virtual Avatars from Multi-view Videos
May 21, 2025

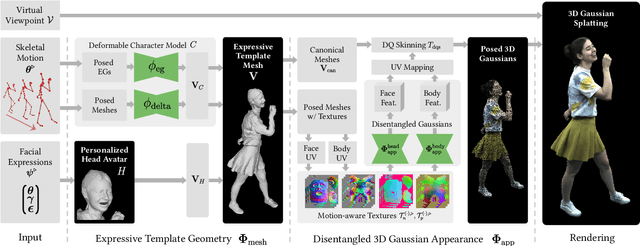

With recent advancements in neural rendering and motion capture algorithms, remarkable progress has been made in photorealistic human avatar modeling, unlocking immense potential for applications in virtual reality, augmented reality, remote communication, and industries such as gaming, film, and medicine. However, existing methods fail to provide complete, faithful, and expressive control over human avatars due to their entangled representation of facial expressions and body movements. In this work, we introduce Expressive Virtual Avatars (EVA), an actor-specific, fully controllable, and expressive human avatar framework that achieves high-fidelity, lifelike renderings in real time while enabling independent control of facial expressions, body movements, and hand gestures. Specifically, our approach designs the human avatar as a two-layer model: an expressive template geometry layer and a 3D Gaussian appearance layer. First, we present an expressive template tracking algorithm that leverages coarse-to-fine optimization to accurately recover body motions, facial expressions, and non-rigid deformation parameters from multi-view videos. Next, we propose a novel decoupled 3D Gaussian appearance model designed to effectively disentangle body and facial appearance. Unlike unified Gaussian estimation approaches, our method employs two specialized and independent modules to model the body and face separately. Experimental results demonstrate that EVA surpasses state-of-the-art methods in terms of rendering quality and expressiveness, validating its effectiveness in creating full-body avatars. This work represents a significant advancement towards fully drivable digital human models, enabling the creation of lifelike digital avatars that faithfully replicate human geometry and appearance.