 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Two Consensuses of the Transferability in Deep Learning
Dec 01, 2022
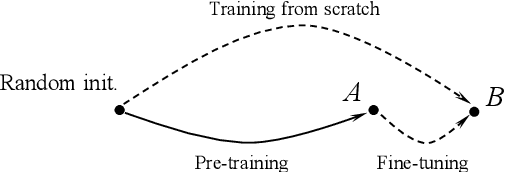
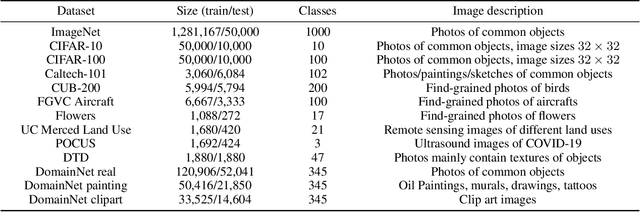
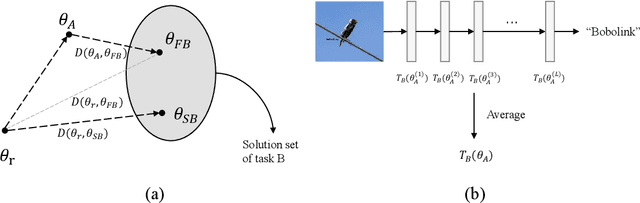

Deep transfer learning (DTL) has formed a long-term quest toward enabling deep neural networks (DNNs) to reuse historical experiences as efficiently as humans. This ability is named knowledge transferability. A commonly used paradigm for DTL is firstly learning general knowledge (pre-training) and then reusing (fine-tuning) them for a specific target task. There are two consensuses of transferability of pre-trained DNNs: (1) a larger domain gap between pre-training and downstream data brings lower transferability; (2) the transferability gradually decreases from lower layers (near input) to higher layers (near output). However, these consensuses were basically drawn from the experiments based on natural images, which limits their scope of application. This work aims to study and complement them from a broader perspective by proposing a method to measure the transferability of pre-trained DNN parameters. Our experiments on twelve diverse image classification datasets get similar conclusions to the previous consensuses. More importantly, two new findings are presented, i.e., (1) in addition to the domain gap, a larger data amount and huge dataset diversity of downstream target task also prohibit the transferability; (2) although the lower layers learn basic image features, they are usually not the most transferable layers due to their domain sensitivity.
Accurate, Low-latency, Efficient SAR Automatic Target Recognition on FPGA
Jan 04, 2023
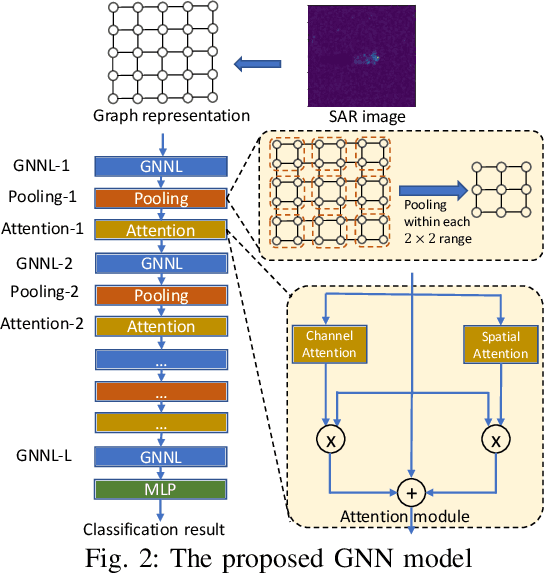
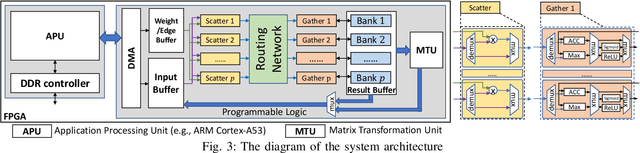
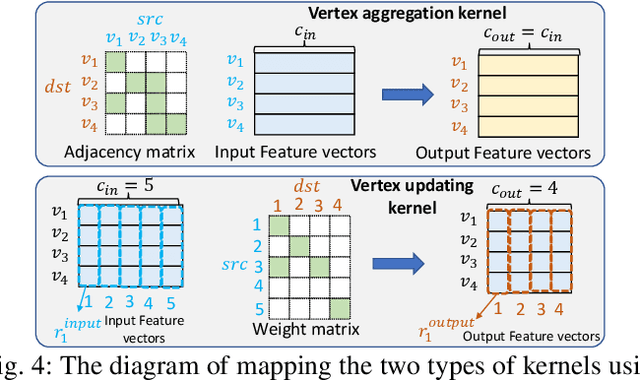
Synthetic aperture radar (SAR) automatic target recognition (ATR) is the key technique for remote-sensing image recognition. The state-of-the-art convolutional neural networks (CNNs) for SAR ATR suffer from \emph{high computation cost} and \emph{large memory footprint}, making them unsuitable to be deployed on resource-limited platforms, such as small/micro satellites. In this paper, we propose a comprehensive GNN-based model-architecture {co-design} on FPGA to address the above issues. \emph{Model design}: we design a novel graph neural network (GNN) for SAR ATR. The proposed GNN model incorporates GraphSAGE layer operators and attention mechanism, achieving comparable accuracy as the state-of-the-art work with near $1/100$ computation cost. Then, we propose a pruning approach including weight pruning and input pruning. While weight pruning through lasso regression reduces most parameters without accuracy drop, input pruning eliminates most input pixels with negligible accuracy drop. \emph{Architecture design}: to fully unleash the computation parallelism within the proposed model, we develop a novel unified hardware architecture that can execute various computation kernels (feature aggregation, feature transformation, graph pooling). The proposed hardware design adopts the Scatter-Gather paradigm to efficiently handle the irregular computation {patterns} of various computation kernels. We deploy the proposed design on an embedded FPGA (AMD Xilinx ZCU104) and evaluate the performance using MSTAR dataset. Compared with the state-of-the-art CNNs, the proposed GNN achieves comparable accuracy with $1/3258$ computation cost and $1/83$ model size. Compared with the state-of-the-art CPU/GPU, our FPGA accelerator achieves $14.8\times$/$2.5\times$ speedup (latency) and is $62\times$/$39\times$ more energy efficient.
Minimizing the Effect of Noise and Limited Dataset Size in Image Classification Using Depth Estimation as an Auxiliary Task with Deep Multitask Learning
Aug 22, 2022
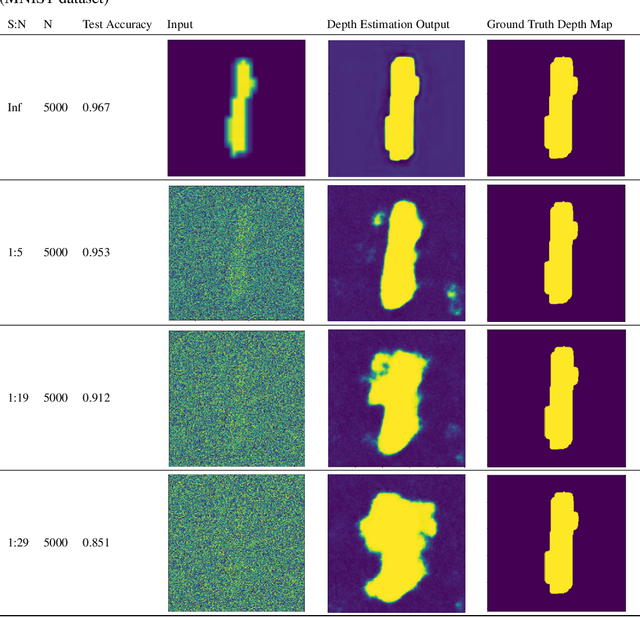

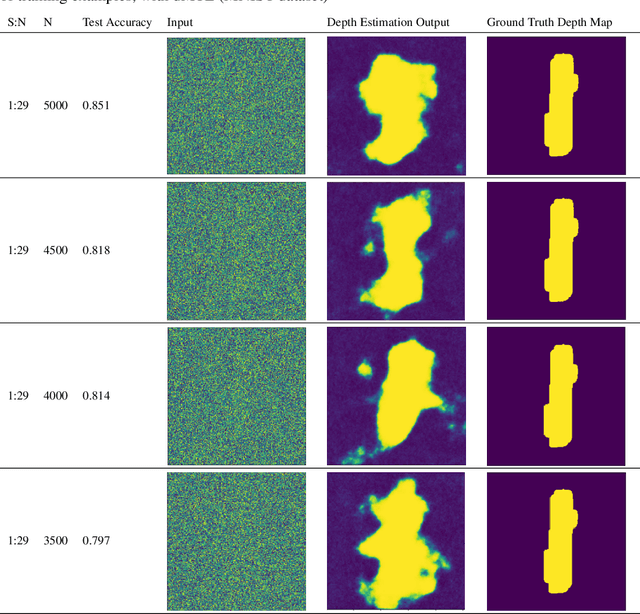
Generalizability is the ultimate goal of Machine Learning (ML) image classifiers, for which noise and limited dataset size are among the major concerns. We tackle these challenges through utilizing the framework of deep Multitask Learning (dMTL) and incorporating image depth estimation as an auxiliary task. On a customized and depth-augmented derivation of the MNIST dataset, we show a) multitask loss functions are the most effective approach of implementing dMTL, b) limited dataset size primarily contributes to classification inaccuracy, and c) depth estimation is mostly impacted by noise. In order to further validate the results, we manually labeled the NYU Depth V2 dataset for scene classification tasks. As a contribution to the field, we have made the data in python native format publicly available as an open-source dataset and provided the scene labels. Our experiments on MNIST and NYU-Depth-V2 show dMTL improves generalizability of the classifiers when the dataset is noisy and the number of examples is limited.
SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
Nov 22, 2022
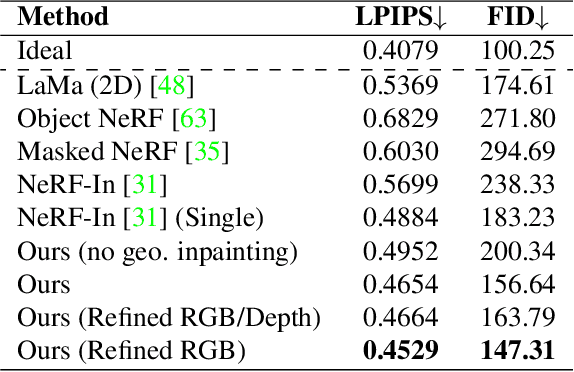
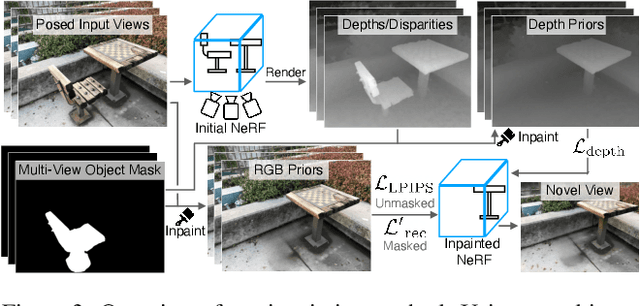
Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimizationbased approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRFbased methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-ofthe-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter baseline
Simple Baselines for Image Restoration
Apr 10, 2022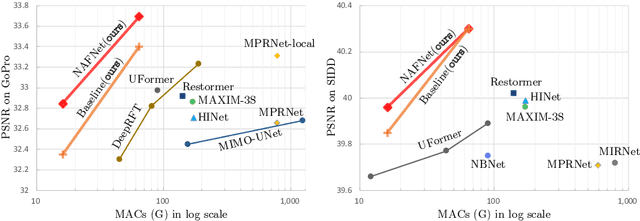

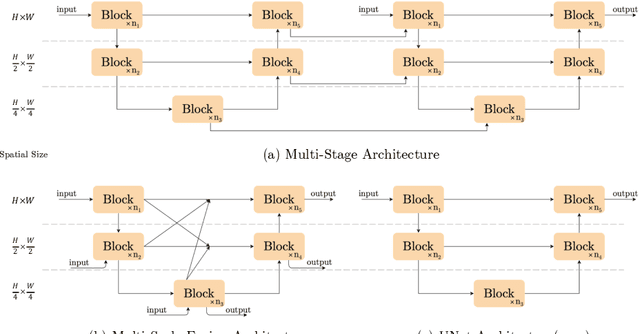
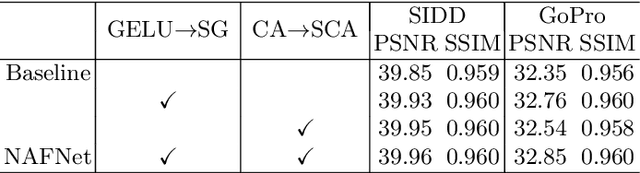
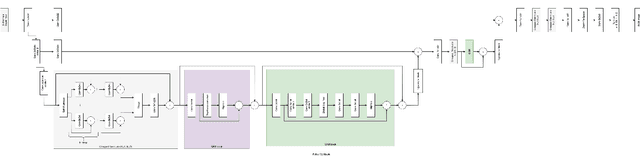
Although there have been significant advances in the field of image restoration recently, the system complexity of the state-of-the-art (SOTA) methods is increasing as well, which may hinder the convenient analysis and comparison of methods. In this paper, we propose a simple baseline that exceeds the SOTA methods and is computationally efficient. To further simplify the baseline, we reveal that the nonlinear activation functions, e.g. Sigmoid, ReLU, GELU, Softmax, etc. are not necessary: they could be replaced by multiplication or removed. Thus, we derive a Nonlinear Activation Free Network, namely NAFNet, from the baseline. SOTA results are achieved on various challenging benchmarks, e.g. 33.69 dB PSNR on GoPro (for image deblurring), exceeding the previous SOTA 0.38 dB with only 8.4% of its computational costs; 40.30 dB PSNR on SIDD (for image denoising), exceeding the previous SOTA 0.28 dB with less than half of its computational costs. The code and the pretrained models will be released at https://github.com/megvii-research/NAFNet.
PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks
Nov 08, 2022


The increased importance of mobile photography created a need for fast and performant RAW image processing pipelines capable of producing good visual results in spite of the mobile camera sensor limitations. While deep learning-based approaches can efficiently solve this problem, their computational requirements usually remain too large for high-resolution on-device image processing. To address this limitation, we propose a novel PyNET-V2 Mobile CNN architecture designed specifically for edge devices, being able to process RAW 12MP photos directly on mobile phones under 1.5 second and producing high perceptual photo quality. To train and to evaluate the performance of the proposed solution, we use the real-world Fujifilm UltraISP dataset consisting on thousands of RAW-RGB image pairs captured with a professional medium-format 102MP Fujifilm camera and a popular Sony mobile camera sensor. The results demonstrate that the PyNET-V2 Mobile model can substantially surpass the quality of tradition ISP pipelines, while outperforming the previously introduced neural network-based solutions designed for fast image processing. Furthermore, we show that the proposed architecture is also compatible with the latest mobile AI accelerators such as NPUs or APUs that can be used to further reduce the latency of the model to as little as 0.5 second. The dataset, code and pre-trained models used in this paper are available on the project website: https://github.com/gmalivenko/PyNET-v2
The Hateful Memes Challenge Next Move
Dec 18, 2022
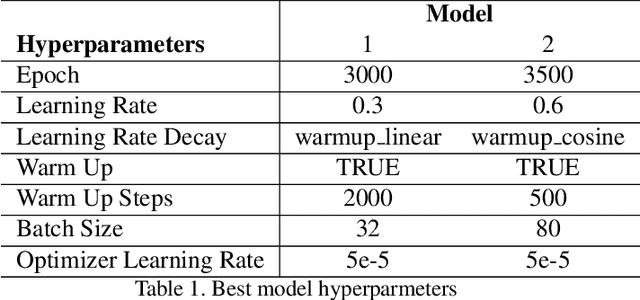
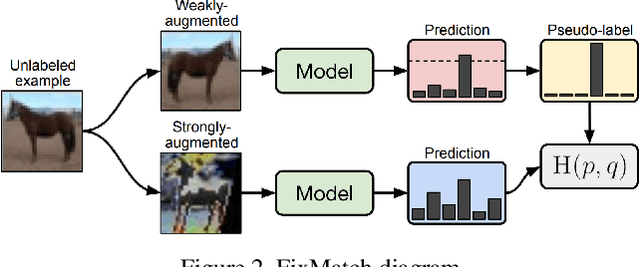
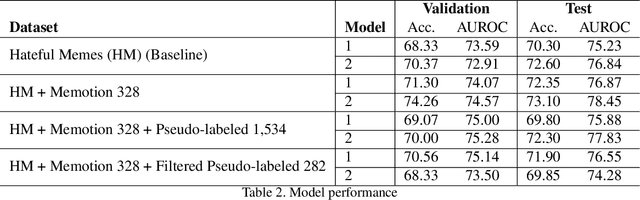
State-of-the-art image and text classification models, such as Convolutional Neural Networks and Transformers, have long been able to classify their respective unimodal reasoning satisfactorily with accuracy close to or exceeding human accuracy. However, images embedded with text, such as hateful memes, are hard to classify using unimodal reasoning when difficult examples, such as benign confounders, are incorporated into the data set. We attempt to generate more labeled memes in addition to the Hateful Memes data set from Facebook AI, based on the framework of a winning team from the Hateful Meme Challenge. To increase the number of labeled memes, we explore semi-supervised learning using pseudo-labels for newly introduced, unlabeled memes gathered from the Memotion Dataset 7K. We find that the semi-supervised learning task on unlabeled data required human intervention and filtering and that adding a limited amount of new data yields no extra classification performance.
TORE: Token Reduction for Efficient Human Mesh Recovery with Transformer
Nov 23, 2022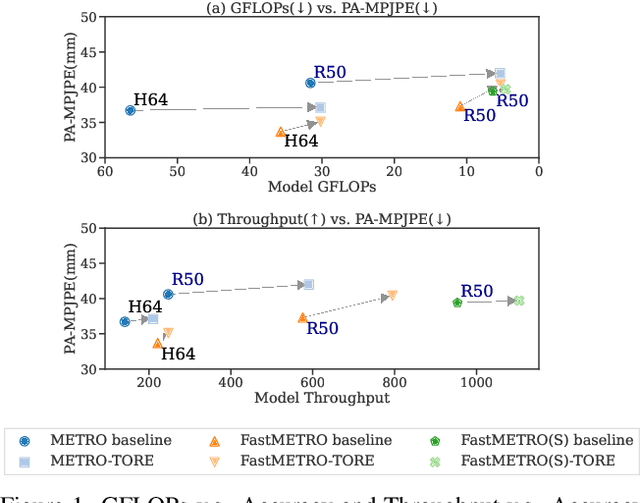
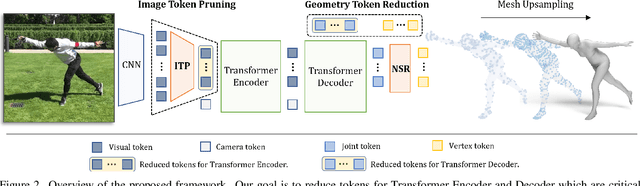
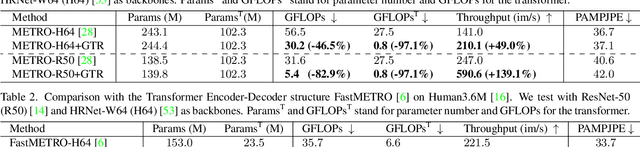
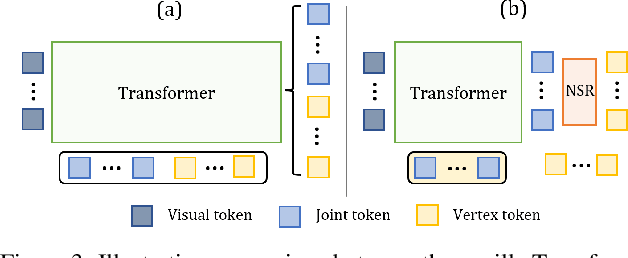
In this paper, we introduce a set of effective TOken REduction (TORE) strategies for Transformer-based Human Mesh Recovery from monocular images. Current SOTA performance is achieved by Transformer-based structures. However, they suffer from high model complexity and computation cost caused by redundant tokens. We propose token reduction strategies based on two important aspects, i.e., the 3D geometry structure and 2D image feature, where we hierarchically recover the mesh geometry with priors from body structure and conduct token clustering to pass fewer but more discriminative image feature tokens to the Transformer. As a result, our method vastly reduces the number of tokens involved in high-complexity interactions in the Transformer, achieving competitive accuracy of shape recovery at a significantly reduced computational cost. We conduct extensive experiments across a wide range of benchmarks to validate the proposed method and further demonstrate the generalizability of our method on hand mesh recovery. Our code will be publicly available once the paper is published.
Semantics-Preserving Sketch Embedding for Face Generation
Nov 23, 2022



With recent advances in image-to-image translation tasks, remarkable progress has been witnessed in generating face images from sketches. However, existing methods frequently fail to generate images with details that are semantically and geometrically consistent with the input sketch, especially when various decoration strokes are drawn. To address this issue, we introduce a novel W-W+ encoder architecture to take advantage of the high expressive power of W+ space and semantic controllability of W space. We introduce an explicit intermediate representation for sketch semantic embedding. With a semantic feature matching loss for effective semantic supervision, our sketch embedding precisely conveys the semantics in the input sketches to the synthesized images. Moreover, a novel sketch semantic interpretation approach is designed to automatically extract semantics from vectorized sketches. We conduct extensive experiments on both synthesized sketches and hand-drawn sketches, and the results demonstrate the superiority of our method over existing approaches on both semantics-preserving and generalization ability.
Nonlinear Equivariant Imaging: Learning Multi-Parametric Tissue Mapping without Ground Truth for Compressive Quantitative MRI
Nov 23, 2022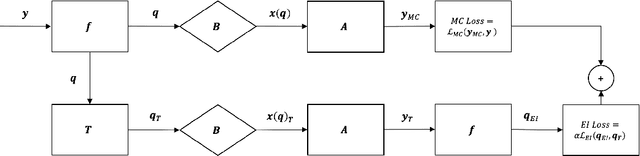
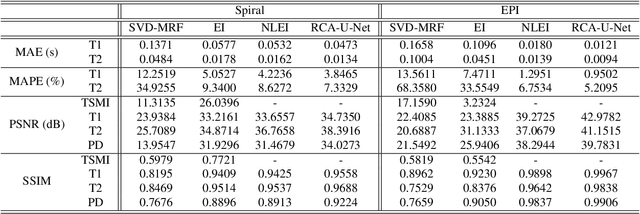
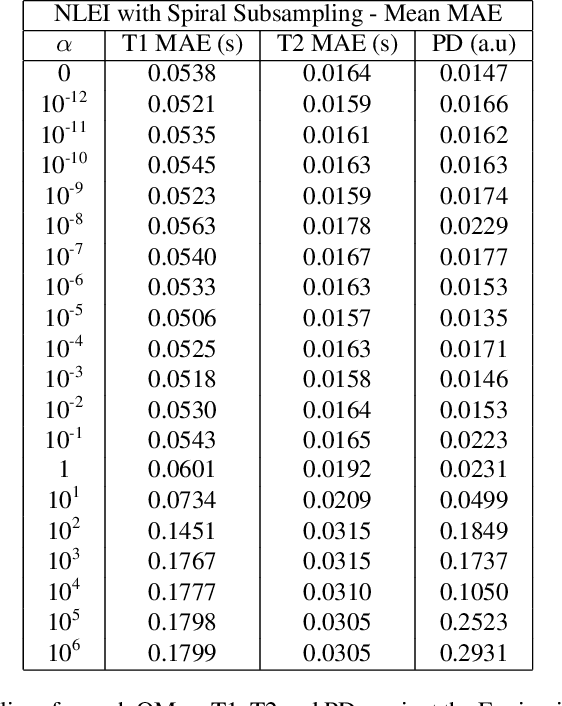
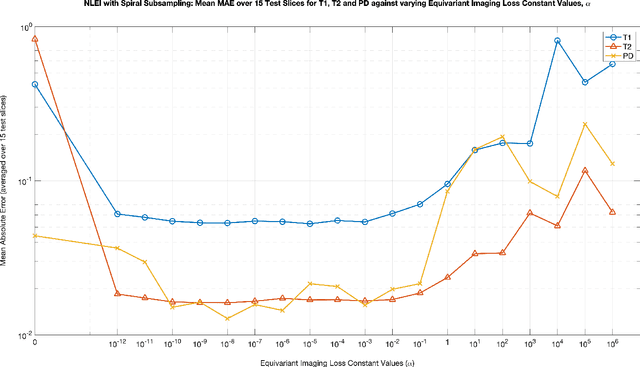
Current state-of-the-art reconstruction for quantitative tissue maps from fast, compressive, Magnetic Resonance Fingerprinting (MRF), use supervised deep learning, with the drawback of requiring high-fidelity ground truth tissue map training data which is limited. This paper proposes NonLinear Equivariant Imaging (NLEI), a self-supervised learning approach to eliminate the need for ground truth for deep MRF image reconstruction. NLEI extends the recent Equivariant Imaging framework to nonlinear inverse problems such as MRF. Only fast, compressed-sampled MRF scans are used for training. NLEI learns tissue mapping using spatiotemporal priors: spatial priors are obtained from the invariance of MRF data to a group of geometric image transformations, while temporal priors are obtained from a nonlinear Bloch response model approximated by a pre-trained neural network. Tested retrospectively on two acquisition settings, we observe that NLEI (self-supervised learning) closely approaches the performance of supervised learning, despite not using ground truth during training.