 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Scaling Laws for Optimal Mixture-of-Experts Architecture Optimization
Mar 23, 2026Scaling laws for Large Language Models govern macroscopic resource allocation, yet translating them into precise Mixture-of-Experts (MoE) architectural configurations remains an open problem due to the combinatorially vast design space. Existing MoE scaling studies are constrained by experimental budgets to either augment scaling formulas with extra MoE variables, risking unreliable fits, or fix all non-MoE factors, ignoring global interactions. We propose a reusable framework for holistic MoE architectural optimization that bridges this gap. We first show that FLOPs per token alone is an inadequate fairness metric for MoE models because differing computational densities across layer types can inflate parameters without proportional compute cost, and establish a joint constraint triad of FLOPs per token, active parameters, and total parameters. We then reduce the 16-dimensional architectural search space to two sequential low-dimensional phases through algebraic constraints and a rank-preserving property of the hidden dimension. Validated across hundreds of MoE models spanning six orders of magnitude in compute, our framework yields robust scaling laws that map any compute budget to a complete, optimal MoE architecture. A key finding is that the near-optimal configuration band widens with scale, giving practitioners quantitative flexibility to balance scaling law recommendations against infrastructure constraints.
CamDirector: Towards Long-Term Coherent Video Trajectory Editing
Feb 27, 2026Video (camera) trajectory editing aims to synthesize new videos that follow user-defined camera paths while preserving scene content and plausibly inpainting previously unseen regions, upgrading amateur footage into professionally styled videos. Existing VTE methods struggle with precise camera control and long-range consistency because they either inject target poses through a limited-capacity embedding or rely on single-frame warping with only implicit cross-frame aggregation in video diffusion models. To address these issues, we introduce a new VTE framework that 1) explicitly aggregates information across the entire source video via a hybrid warping scheme. Specifically, static regions are progressively fused into a world cache then rendered to target camera poses, while dynamic regions are directly warped; their fusion yields globally consistent coarse frames that guide refinement. 2) processes video segments jointly with their history via a history-guided autoregressive diffusion model, while the world cache is incrementally updated to reinforce already inpainted content, enabling long-term temporal coherence. Finally, we present iPhone-PTZ, a new VTE benchmark with diverse camera motions and large trajectory variations, and achieve state-of-the-art performance with fewer parameters.
Advanced Black-Box Tuning of Large Language Models with Limited API Calls
Nov 17, 2025



Black-box tuning is an emerging paradigm for adapting large language models (LLMs) to better achieve desired behaviors, particularly when direct access to model parameters is unavailable. Current strategies, however, often present a dilemma of suboptimal extremes: either separately train a small proxy model and then use it to shift the predictions of the foundation model, offering notable efficiency but often yielding limited improvement; or making API calls in each tuning iteration to the foundation model, which entails prohibitive computational costs. Therefore, we propose a novel advanced black-box tuning method for LLMs with limited API calls. Our core strategy involves training a Gaussian Process (GP) surrogate model with "LogitMap Pairs" derived from querying the foundation model on a minimal but highly informative training subset. This surrogate can approximate the outputs of the foundation model to guide the training of the proxy model, thereby effectively reducing the need for direct queries to the foundation model. Extensive experiments verify that our approach elevates pre-trained language model accuracy from 55.92% to 86.85%, reducing the frequency of API queries to merely 1.38%. This significantly outperforms offline approaches that operate entirely without API access. Notably, our method also achieves comparable or superior accuracy to query-intensive approaches, while significantly reducing API costs. This offers a robust and high-efficiency paradigm for language model adaptation.
Explore and Establish Synergistic Effects Between Weight Pruning and Coreset Selection in Neural Network Training
Nov 17, 2025Modern deep neural networks rely heavily on massive model weights and training samples, incurring substantial computational costs. Weight pruning and coreset selection are two emerging paradigms proposed to improve computational efficiency. In this paper, we first explore the interplay between redundant weights and training samples through a transparent analysis: redundant samples, particularly noisy ones, cause model weights to become unnecessarily overtuned to fit them, complicating the identification of irrelevant weights during pruning; conversely, irrelevant weights tend to overfit noisy data, undermining coreset selection effectiveness. To further investigate and harness this interplay in deep learning, we develop a Simultaneous Weight and Sample Tailoring mechanism (SWaST) that alternately performs weight pruning and coreset selection to establish a synergistic effect in training. During this investigation, we observe that when simultaneously removing a large number of weights and samples, a phenomenon we term critical double-loss can occur, where important weights and their supportive samples are mistakenly eliminated at the same time, leading to model instability and nearly irreversible degradation that cannot be recovered in subsequent training. Unlike classic machine learning models, this issue can arise in deep learning due to the lack of theoretical guarantees on the correctness of weight pruning and coreset selection, which explains why these paradigms are often developed independently. We mitigate this by integrating a state preservation mechanism into SWaST, enabling stable joint optimization. Extensive experiments reveal a strong synergy between pruning and coreset selection across varying prune rates and coreset sizes, delivering accuracy boosts of up to 17.83% alongside 10% to 90% FLOPs reductions.
CoMo: Controllable Motion Generation through Language Guided Pose Code Editing
Mar 20, 2024Text-to-motion models excel at efficient human motion generation, but existing approaches lack fine-grained controllability over the generation process. Consequently, modifying subtle postures within a motion or inserting new actions at specific moments remains a challenge, limiting the applicability of these methods in diverse scenarios. In light of these challenges, we introduce CoMo, a Controllable Motion generation model, adept at accurately generating and editing motions by leveraging the knowledge priors of large language models (LLMs). Specifically, CoMo decomposes motions into discrete and semantically meaningful pose codes, with each code encapsulating the semantics of a body part, representing elementary information such as "left knee slightly bent". Given textual inputs, CoMo autoregressively generates sequences of pose codes, which are then decoded into 3D motions. Leveraging pose codes as interpretable representations, an LLM can directly intervene in motion editing by adjusting the pose codes according to editing instructions. Experiments demonstrate that CoMo achieves competitive performance in motion generation compared to state-of-the-art models while, in human studies, CoMo substantially surpasses previous work in motion editing abilities.
Out-of-Distribution Detection using Neural Activation Prior
Mar 06, 2024



Out-of-distribution detection (OOD) is a crucial technique for deploying machine learning models in the real world to handle the unseen scenarios. In this paper, we first propose a simple yet effective Neural Activation Prior (NAP) for OOD detection. Our neural activation prior is based on a key observation that, for a channel before the global pooling layer of a fully trained neural network, the probability of a few neurons being activated with a large response by an in-distribution (ID) sample is significantly higher than that by an OOD sample. An intuitive explanation is that for a model fully trained on ID dataset, each channel would play a role in detecting a certain pattern in the ID dataset, and a few neurons can be activated with a large response when the pattern is detected in an input sample. Then, a new scoring function based on this prior is proposed to highlight the role of these strongly activated neurons in OOD detection. Our approach is plug-and-play and does not lead to any performance degradation on ID data classification and requires no extra training or statistics from training or external datasets. Notice that previous methods primarily rely on post-global-pooling features of the neural networks, while the within-channel distribution information we leverage would be discarded by the global pooling operator. Consequently, our method is orthogonal to existing approaches and can be effectively combined with them in various applications. Experimental results show that our method achieves the state-of-the-art performance on CIFAR benchmark and ImageNet dataset, which demonstrates the power of the proposed prior. Finally, we extend our method to Transformers and the experimental findings indicate that NAP can also significantly enhance the performance of OOD detection on Transformers, thereby demonstrating the broad applicability of this prior knowledge.
DiffusionPhase: Motion Diffusion in Frequency Domain
Dec 07, 2023



In this study, we introduce a learning-based method for generating high-quality human motion sequences from text descriptions (e.g., ``A person walks forward"). Existing techniques struggle with motion diversity and smooth transitions in generating arbitrary-length motion sequences, due to limited text-to-motion datasets and the pose representations used that often lack expressiveness or compactness. To address these issues, we propose the first method for text-conditioned human motion generation in the frequency domain of motions. We develop a network encoder that converts the motion space into a compact yet expressive parameterized phase space with high-frequency details encoded, capturing the local periodicity of motions in time and space with high accuracy. We also introduce a conditional diffusion model for predicting periodic motion parameters based on text descriptions and a start pose, efficiently achieving smooth transitions between motion sequences associated with different text descriptions. Experiments demonstrate that our approach outperforms current methods in generating a broader variety of high-quality motions, and synthesizing long sequences with natural transitions.
TLControl: Trajectory and Language Control for Human Motion Synthesis
Nov 30, 2023Controllable human motion synthesis is essential for applications in AR/VR, gaming, movies, and embodied AI. Existing methods often focus solely on either language or full trajectory control, lacking precision in synthesizing motions aligned with user-specified trajectories, especially for multi-joint control. To address these issues, we present TLControl, a new method for realistic human motion synthesis, incorporating both low-level trajectory and high-level language semantics controls. Specifically, we first train a VQ-VAE to learn a compact latent motion space organized by body parts. We then propose a Masked Trajectories Transformer to make coarse initial predictions of full trajectories of joints based on the learned latent motion space, with user-specified partial trajectories and text descriptions as conditioning. Finally, we introduce an efficient test-time optimization to refine these coarse predictions for accurate trajectory control. Experiments demonstrate that TLControl outperforms the state-of-the-art in trajectory accuracy and time efficiency, making it practical for interactive and high-quality animation generation.
TORE: Token Reduction for Efficient Human Mesh Recovery with Transformer
Nov 23, 2022



In this paper, we introduce a set of effective TOken REduction (TORE) strategies for Transformer-based Human Mesh Recovery from monocular images. Current SOTA performance is achieved by Transformer-based structures. However, they suffer from high model complexity and computation cost caused by redundant tokens. We propose token reduction strategies based on two important aspects, i.e., the 3D geometry structure and 2D image feature, where we hierarchically recover the mesh geometry with priors from body structure and conduct token clustering to pass fewer but more discriminative image feature tokens to the Transformer. As a result, our method vastly reduces the number of tokens involved in high-complexity interactions in the Transformer, achieving competitive accuracy of shape recovery at a significantly reduced computational cost. We conduct extensive experiments across a wide range of benchmarks to validate the proposed method and further demonstrate the generalizability of our method on hand mesh recovery. Our code will be publicly available once the paper is published.
Learn to Predict How Humans Manipulate Large-sized Objects from Interactive Motions
Jun 25, 2022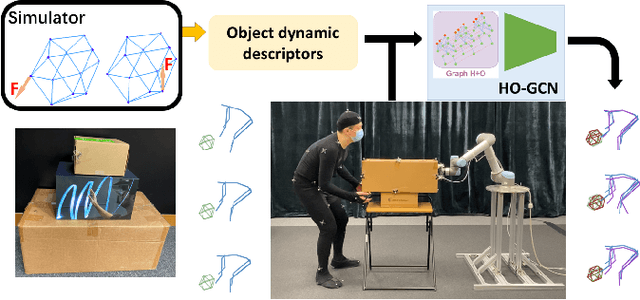

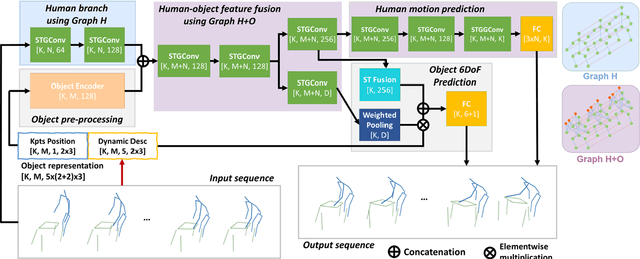
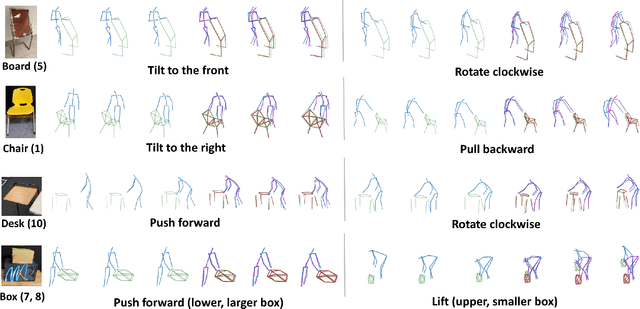
Understanding human intentions during interactions has been a long-lasting theme, that has applications in human-robot interaction, virtual reality and surveillance. In this study, we focus on full-body human interactions with large-sized daily objects and aim to predict the future states of objects and humans given a sequential observation of human-object interaction. As there is no such dataset dedicated to full-body human interactions with large-sized daily objects, we collected a large-scale dataset containing thousands of interactions for training and evaluation purposes. We also observe that an object's intrinsic physical properties are useful for the object motion prediction, and thus design a set of object dynamic descriptors to encode such intrinsic properties. We treat the object dynamic descriptors as a new modality and propose a graph neural network, HO-GCN, to fuse motion data and dynamic descriptors for the prediction task. We show the proposed network that consumes dynamic descriptors can achieve state-of-the-art prediction results and help the network better generalize to unseen objects. We also demonstrate the predicted results are useful for human-robot collaborations.