 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MGIC: A Multi-Label Gradient Inversion Attack based on Canny Edge Detection on Federated Learning
Mar 13, 2024
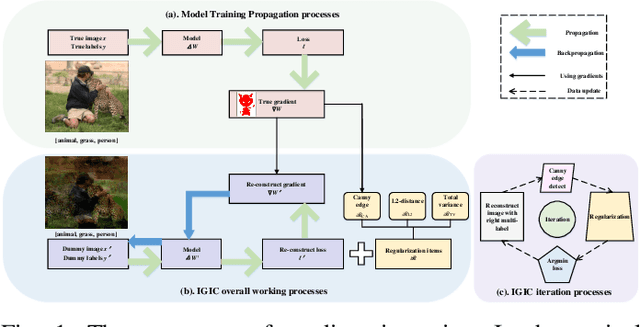
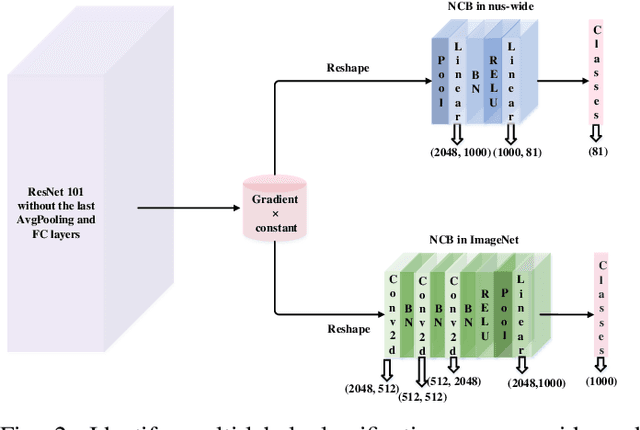


As a new distributed computing framework that can protect data privacy, federated learning (FL) has attracted more and more attention in recent years. It receives gradients from users to train the global model and releases the trained global model to working users. Nonetheless, the gradient inversion (GI) attack reflects the risk of privacy leakage in federated learning. Attackers only need to use gradients through hundreds of thousands of simple iterations to obtain relatively accurate private data stored on users' local devices. For this, some works propose simple but effective strategies to obtain user data under a single-label dataset. However, these strategies induce a satisfactory visual effect of the inversion image at the expense of higher time costs. Due to the semantic limitation of a single label, the image obtained by gradient inversion may have semantic errors. We present a novel gradient inversion strategy based on canny edge detection (MGIC) in both the multi-label and single-label datasets. To reduce semantic errors caused by a single label, we add new convolution layers' blocks in the trained model to obtain the image's multi-label. Through multi-label representation, serious semantic errors in inversion images are reduced. Then, we analyze the impact of parameters on the difficulty of input image reconstruction and discuss how image multi-subjects affect the inversion performance. Our proposed strategy has better visual inversion image results than the most widely used ones, saving more than 78% of time costs in the ImageNet dataset.
Diffusion Models Trained with Large Data Are Transferable Visual Models
Mar 15, 2024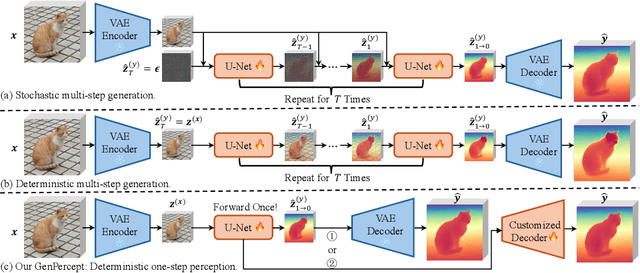
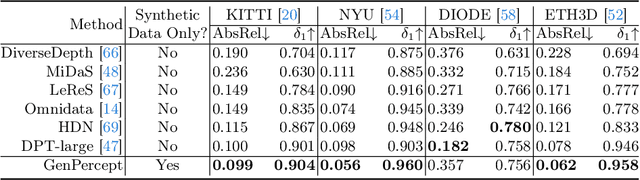

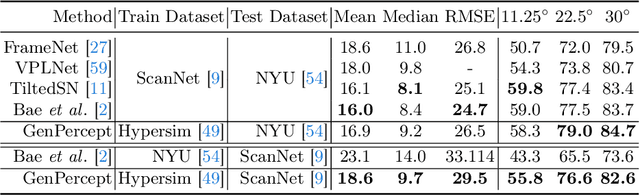
We show that, simply initializing image understanding models using a pre-trained UNet (or transformer) of diffusion models, it is possible to achieve remarkable transferable performance on fundamental vision perception tasks using a moderate amount of target data (even synthetic data only), including monocular depth, surface normal, image segmentation, matting, human pose estimation, among virtually many others. Previous works have adapted diffusion models for various perception tasks, often reformulating these tasks as generation processes to align with the diffusion process. In sharp contrast, we demonstrate that fine-tuning these models with minimal adjustments can be a more effective alternative, offering the advantages of being embarrassingly simple and significantly faster. As the backbone network of Stable Diffusion models is trained on giant datasets comprising billions of images, we observe very robust generalization capabilities of the diffusion backbone. Experimental results showcase the remarkable transferability of the backbone of diffusion models across diverse tasks and real-world datasets.
Learning Dual-Level Deformable Implicit Representation for Real-World Scale Arbitrary Super-Resolution
Mar 16, 2024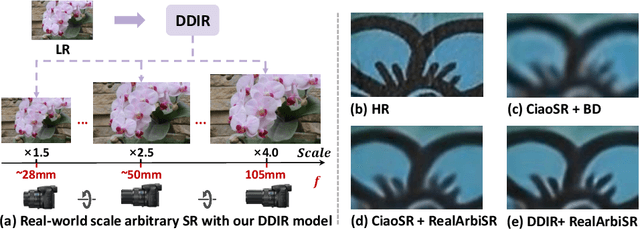
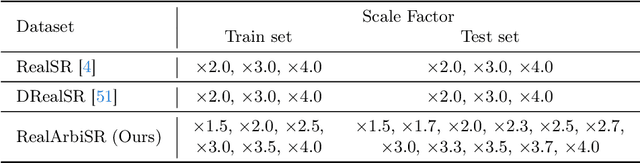

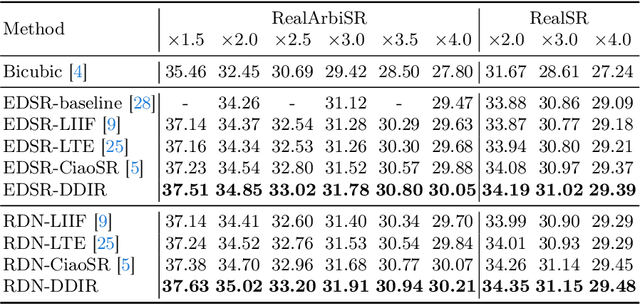
Scale arbitrary super-resolution based on implicit image function gains increasing popularity since it can better represent the visual world in a continuous manner. However, existing scale arbitrary works are trained and evaluated on simulated datasets, where low-resolution images are generated from their ground truths by the simplest bicubic downsampling. These models exhibit limited generalization to real-world scenarios due to the greater complexity of real-world degradations. To address this issue, we build a RealArbiSR dataset, a new real-world super-resolution benchmark with both integer and non-integer scaling factors for the training and evaluation of real-world scale arbitrary super-resolution. Moreover, we propose a Dual-level Deformable Implicit Representation (DDIR) to solve real-world scale arbitrary super-resolution. Specifically, we design the appearance embedding and deformation field to handle both image-level and pixel-level deformations caused by real-world degradations. The appearance embedding models the characteristics of low-resolution inputs to deal with photometric variations at different scales, and the pixel-based deformation field learns RGB differences which result from the deviations between the real-world and simulated degradations at arbitrary coordinates. Extensive experiments show our trained model achieves state-of-the-art performance on the RealArbiSR and RealSR benchmarks for real-world scale arbitrary super-resolution. Our dataset as well as source code will be publicly available.
Rule-driven News Captioning
Mar 14, 2024
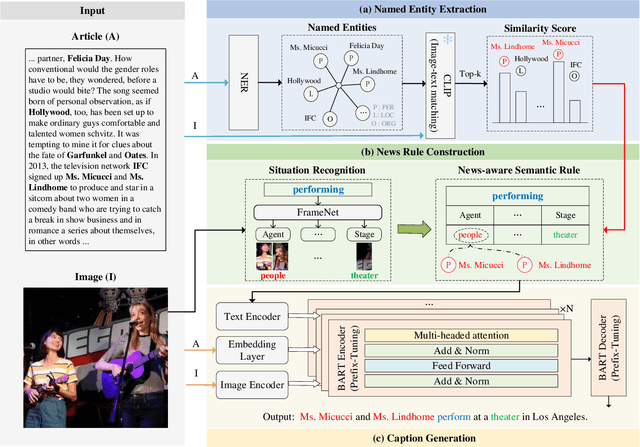
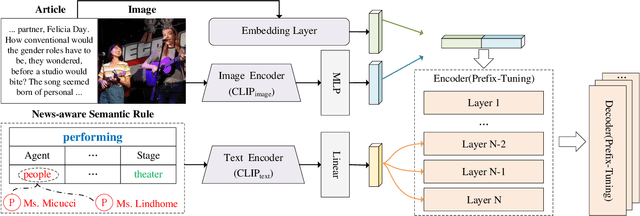
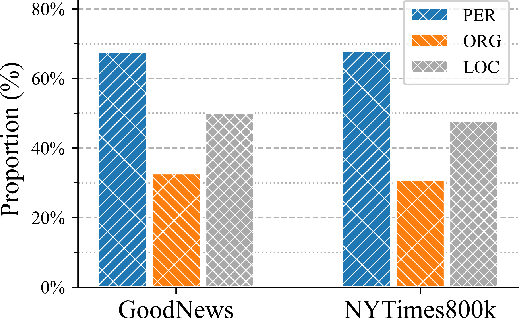
News captioning task aims to generate sentences by describing named entities or concrete events for an image with its news article. Existing methods have achieved remarkable results by relying on the large-scale pre-trained models, which primarily focus on the correlations between the input news content and the output predictions. However, the news captioning requires adhering to some fundamental rules of news reporting, such as accurately describing the individuals and actions associated with the event. In this paper, we propose the rule-driven news captioning method, which can generate image descriptions following designated rule signal. Specifically, we first design the news-aware semantic rule for the descriptions. This rule incorporates the primary action depicted in the image (e.g., "performing") and the roles played by named entities involved in the action (e.g., "Agent" and "Place"). Second, we inject this semantic rule into the large-scale pre-trained model, BART, with the prefix-tuning strategy, where multiple encoder layers are embedded with news-aware semantic rule. Finally, we can effectively guide BART to generate news sentences that comply with the designated rule. Extensive experiments on two widely used datasets (i.e., GoodNews and NYTimes800k) demonstrate the effectiveness of our method.
Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
Mar 14, 2024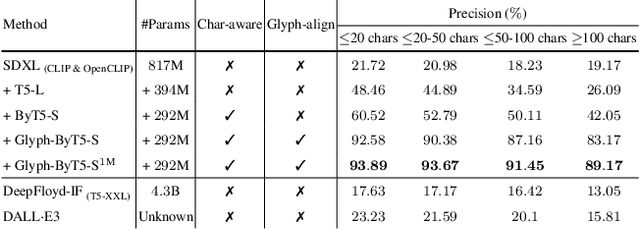

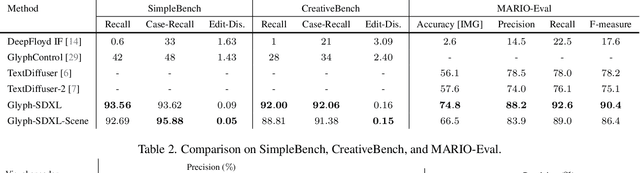

Visual text rendering poses a fundamental challenge for contemporary text-to-image generation models, with the core problem lying in text encoder deficiencies. To achieve accurate text rendering, we identify two crucial requirements for text encoders: character awareness and alignment with glyphs. Our solution involves crafting a series of customized text encoder, Glyph-ByT5, by fine-tuning the character-aware ByT5 encoder using a meticulously curated paired glyph-text dataset. We present an effective method for integrating Glyph-ByT5 with SDXL, resulting in the creation of the Glyph-SDXL model for design image generation. This significantly enhances text rendering accuracy, improving it from less than $20\%$ to nearly $90\%$ on our design image benchmark. Noteworthy is Glyph-SDXL's newfound ability for text paragraph rendering, achieving high spelling accuracy for tens to hundreds of characters with automated multi-line layouts. Finally, through fine-tuning Glyph-SDXL with a small set of high-quality, photorealistic images featuring visual text, we showcase a substantial improvement in scene text rendering capabilities in open-domain real images. These compelling outcomes aim to encourage further exploration in designing customized text encoders for diverse and challenging tasks.
When Do We Not Need Larger Vision Models?
Mar 19, 2024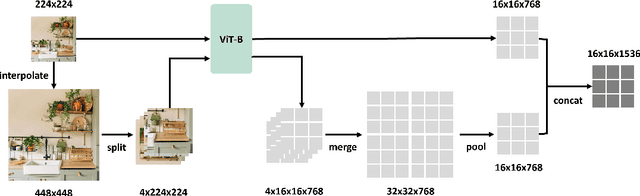
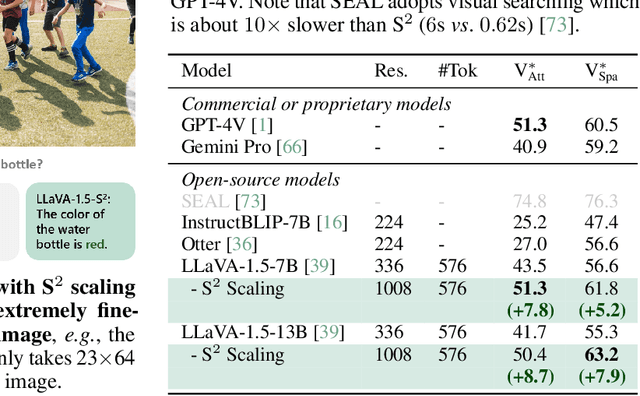
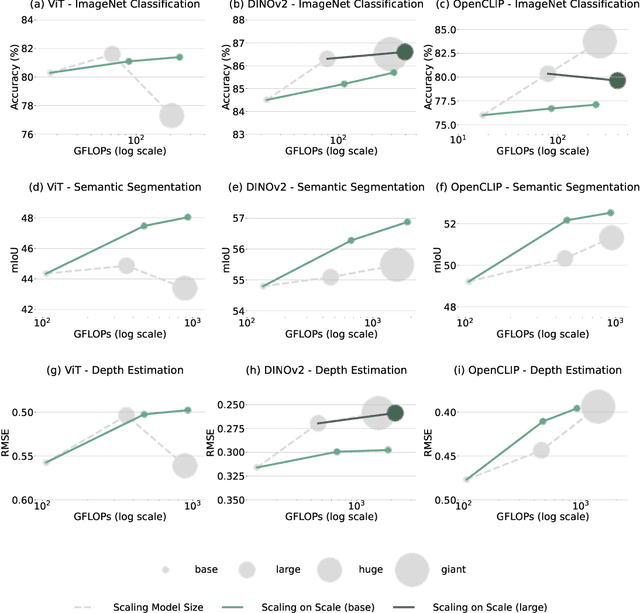
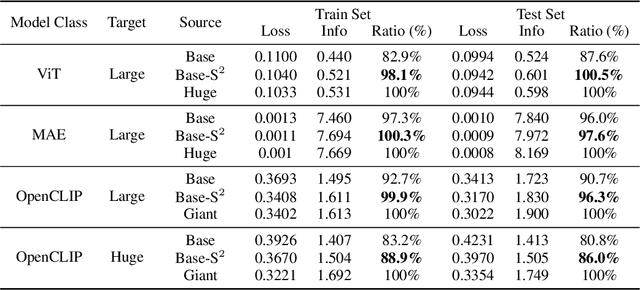
Scaling up the size of vision models has been the de facto standard to obtain more powerful visual representations. In this work, we discuss the point beyond which larger vision models are not necessary. First, we demonstrate the power of Scaling on Scales (S$^2$), whereby a pre-trained and frozen smaller vision model (e.g., ViT-B or ViT-L), run over multiple image scales, can outperform larger models (e.g., ViT-H or ViT-G) on classification, segmentation, depth estimation, Multimodal LLM (MLLM) benchmarks, and robotic manipulation. Notably, S$^2$ achieves state-of-the-art performance in detailed understanding of MLLM on the V* benchmark, surpassing models such as GPT-4V. We examine the conditions under which S$^2$ is a preferred scaling approach compared to scaling on model size. While larger models have the advantage of better generalization on hard examples, we show that features of larger vision models can be well approximated by those of multi-scale smaller models. This suggests most, if not all, of the representations learned by current large pre-trained models can also be obtained from multi-scale smaller models. Our results show that a multi-scale smaller model has comparable learning capacity to a larger model, and pre-training smaller models with S$^2$ can match or even exceed the advantage of larger models. We release a Python package that can apply S$^2$ on any vision model with one line of code: https://github.com/bfshi/scaling_on_scales.
VL-ICL Bench: The Devil in the Details of Benchmarking Multimodal In-Context Learning
Mar 19, 2024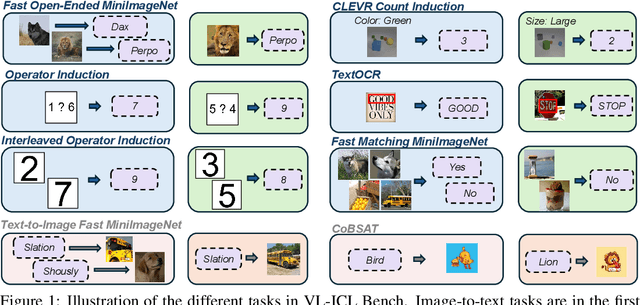

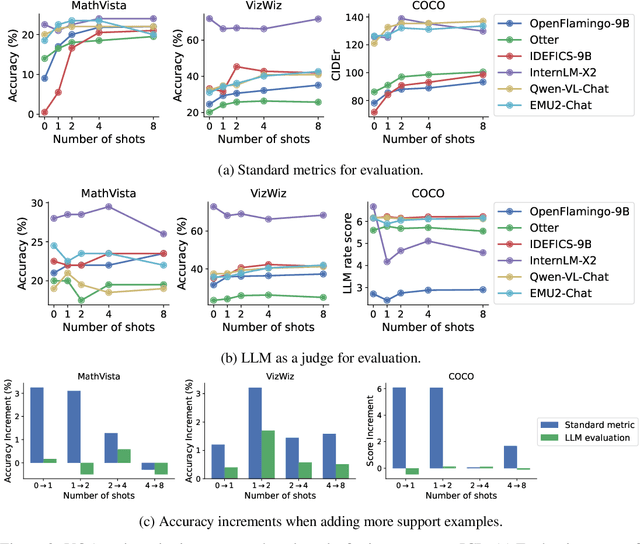
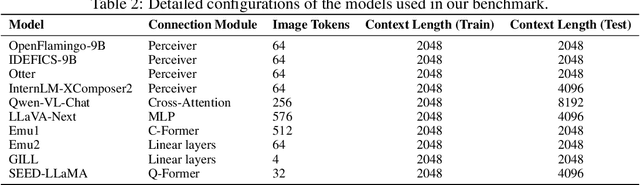
Large language models (LLMs) famously exhibit emergent in-context learning (ICL) -- the ability to rapidly adapt to new tasks using few-shot examples provided as a prompt, without updating the model's weights. Built on top of LLMs, vision large language models (VLLMs) have advanced significantly in areas such as recognition, reasoning, and grounding. However, investigations into \emph{multimodal ICL} have predominantly focused on few-shot visual question answering (VQA), and image captioning, which we will show neither exploit the strengths of ICL, nor test its limitations. The broader capabilities and limitations of multimodal ICL remain under-explored. In this study, we introduce a comprehensive benchmark VL-ICL Bench for multimodal in-context learning, encompassing a broad spectrum of tasks that involve both images and text as inputs and outputs, and different types of challenges, from {perception to reasoning and long context length}. We evaluate the abilities of state-of-the-art VLLMs against this benchmark suite, revealing their diverse strengths and weaknesses, and showing that even the most advanced models, such as GPT-4, find the tasks challenging. By highlighting a range of new ICL tasks, and the associated strengths and limitations of existing models, we hope that our dataset will inspire future work on enhancing the in-context learning capabilities of VLLMs, as well as inspire new applications that leverage VLLM ICL. The code and dataset are available at https://github.com/ys-zong/VL-ICL.
Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
Mar 19, 2024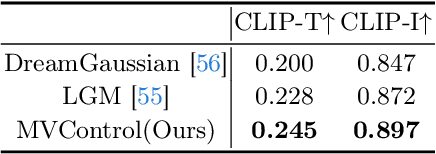
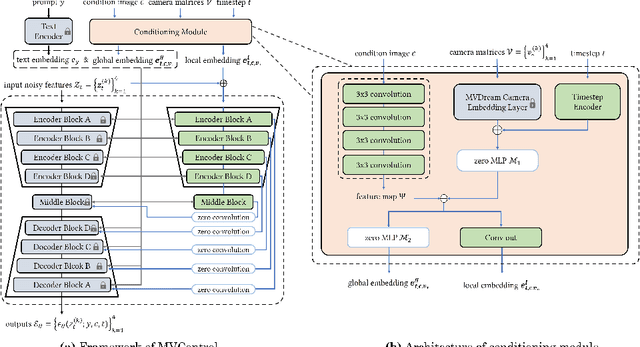
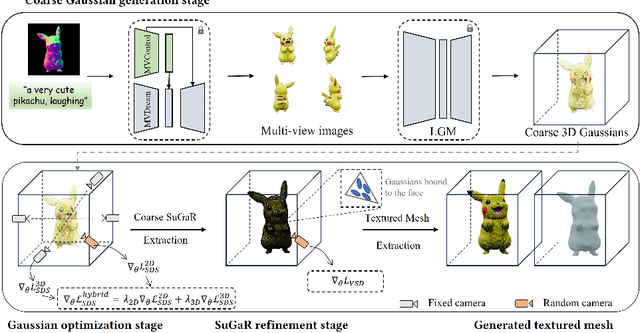

While text-to-3D and image-to-3D generation tasks have received considerable attention, one important but under-explored field between them is controllable text-to-3D generation, which we mainly focus on in this work. To address this task, 1) we introduce Multi-view ControlNet (MVControl), a novel neural network architecture designed to enhance existing pre-trained multi-view diffusion models by integrating additional input conditions, such as edge, depth, normal, and scribble maps. Our innovation lies in the introduction of a conditioning module that controls the base diffusion model using both local and global embeddings, which are computed from the input condition images and camera poses. Once trained, MVControl is able to offer 3D diffusion guidance for optimization-based 3D generation. And, 2) we propose an efficient multi-stage 3D generation pipeline that leverages the benefits of recent large reconstruction models and score distillation algorithm. Building upon our MVControl architecture, we employ a unique hybrid diffusion guidance method to direct the optimization process. In pursuit of efficiency, we adopt 3D Gaussians as our representation instead of the commonly used implicit representations. We also pioneer the use of SuGaR, a hybrid representation that binds Gaussians to mesh triangle faces. This approach alleviates the issue of poor geometry in 3D Gaussians and enables the direct sculpting of fine-grained geometry on the mesh. Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content.
GGRt: Towards Pose-free Generalizable 3D Gaussian Splatting in Real-time
Mar 19, 2024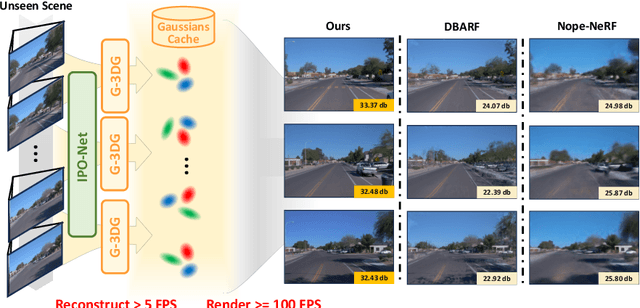
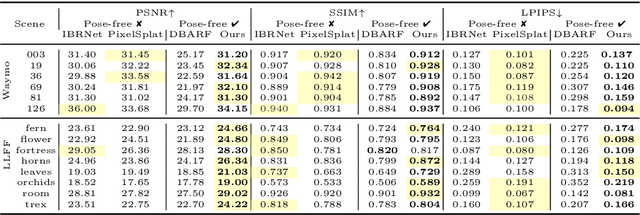
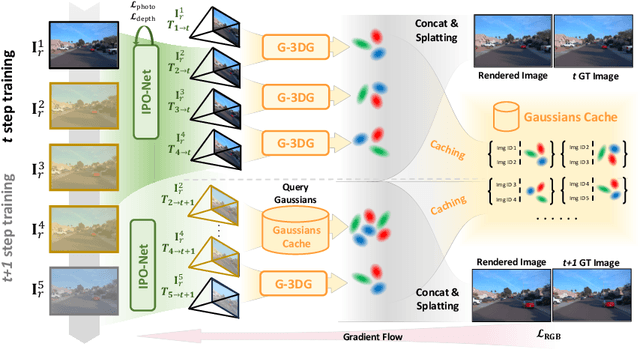

This paper presents GGRt, a novel approach to generalizable novel view synthesis that alleviates the need for real camera poses, complexity in processing high-resolution images, and lengthy optimization processes, thus facilitating stronger applicability of 3D Gaussian Splatting (3D-GS) in real-world scenarios. Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model. With the joint learning mechanism, the proposed framework can inherently estimate robust relative pose information from the image observations and thus primarily alleviate the requirement of real camera poses. Moreover, we implement a deferred back-propagation mechanism that enables high-resolution training and inference, overcoming the resolution constraints of previous methods. To enhance the speed and efficiency, we further introduce a progressive Gaussian cache module that dynamically adjusts during training and inference. As the first pose-free generalizable 3D-GS framework, GGRt achieves inference at $\ge$ 5 FPS and real-time rendering at $\ge$ 100 FPS. Through extensive experimentation, we demonstrate that our method outperforms existing NeRF-based pose-free techniques in terms of inference speed and effectiveness. It can also approach the real pose-based 3D-GS methods. Our contributions provide a significant leap forward for the integration of computer vision and computer graphics into practical applications, offering state-of-the-art results on LLFF, KITTI, and Waymo Open datasets and enabling real-time rendering for immersive experiences.
Biophysics Informed Pathological Regularisation for Brain Tumour Segmentation
Mar 18, 2024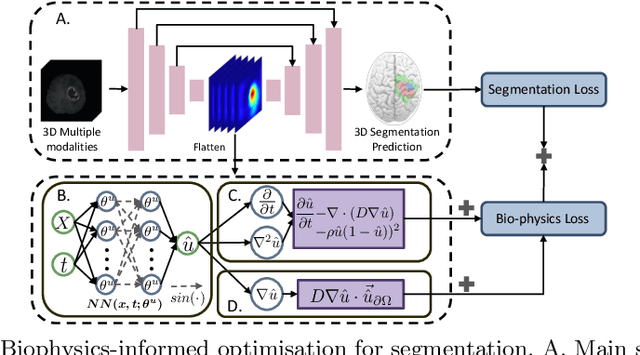
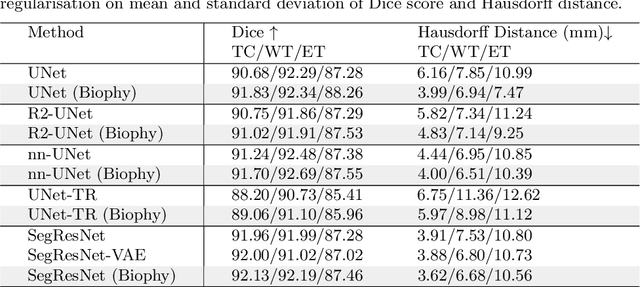
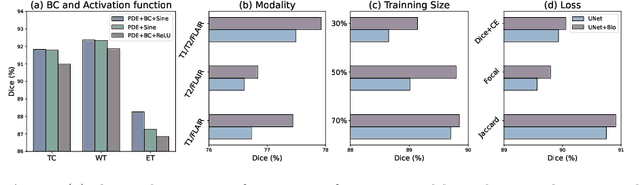
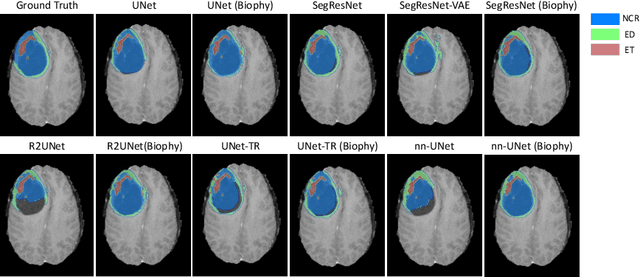
Recent advancements in deep learning have significantly improved brain tumour segmentation techniques; however, the results still lack confidence and robustness as they solely consider image data without biophysical priors or pathological information. Integrating biophysics-informed regularisation is one effective way to change this situation, as it provides an prior regularisation for automated end-to-end learning. In this paper, we propose a novel approach that designs brain tumour growth Partial Differential Equation (PDE) models as a regularisation with deep learning, operational with any network model. Our method introduces tumour growth PDE models directly into the segmentation process, improving accuracy and robustness, especially in data-scarce scenarios. This system estimates tumour cell density using a periodic activation function. By effectively integrating this estimation with biophysical models, we achieve a better capture of tumour characteristics. This approach not only aligns the segmentation closer to actual biological behaviour but also strengthens the model's performance under limited data conditions. We demonstrate the effectiveness of our framework through extensive experiments on the BraTS 2023 dataset, showcasing significant improvements in both precision and reliability of tumour segmentation.