 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Poses of People in Art: A Data Set for Human Pose Estimation in Digital Art History
Jan 12, 2023
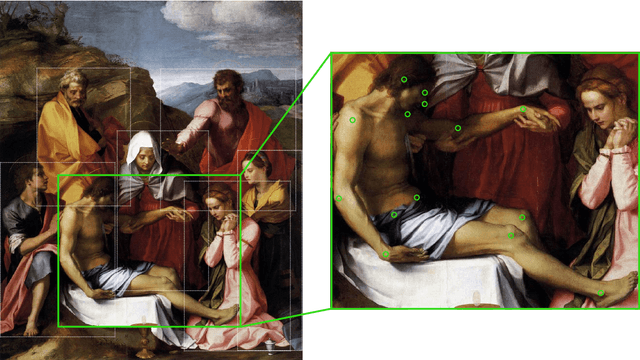
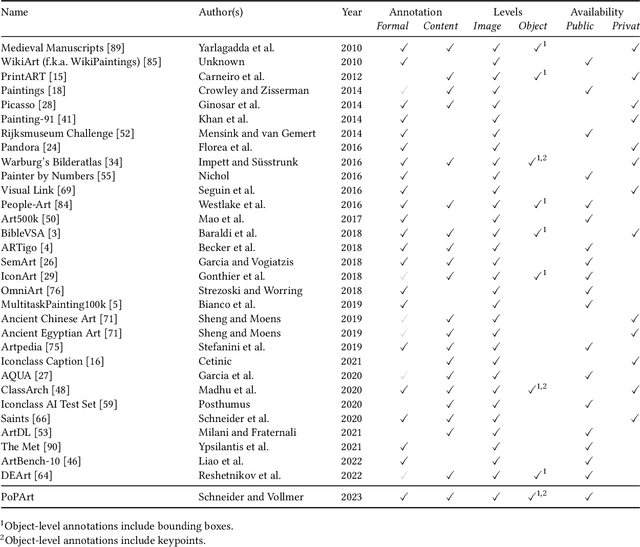

Throughout the history of art, the pose, as the holistic abstraction of the human body's expression, has proven to be a constant in numerous studies. However, due to the enormous amount of data that so far had to be processed by hand, its crucial role to the formulaic recapitulation of art-historical motifs since antiquity could only be highlighted selectively. This is true even for the now automated estimation of human poses, as domain-specific, sufficiently large data sets required for training computational models are either not publicly available or not indexed at a fine enough granularity. With the Poses of People in Art data set, we introduce the first openly licensed data set for estimating human poses in art and validating human pose estimators. It consists of 2,454 images from 22 art-historical depiction styles, including those that have increasingly turned away from lifelike representations of the body since the 19th century. A total of 10,749 human figures are precisely enclosed by rectangular bounding boxes, with a maximum of four per image labeled by up to 17 keypoints; among these are mainly joints such as elbows and knees. For machine learning purposes, the data set is divided into three subsets, training, validation, and testing, that follow the established JSON-based Microsoft COCO format, respectively. Each image annotation, in addition to mandatory fields, provides metadata from the art-historical online encyclopedia WikiArt. With this paper, we elaborate on the acquisition and constitution of the data set, address various application scenarios, and discuss prospects for a digitally supported art history. We show that the data set enables the investigation of body phenomena in art, whether at the level of individual figures, which can be captured in their subtleties, or entire figure constellations, whose position, distance, or proximity to one another is considered.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022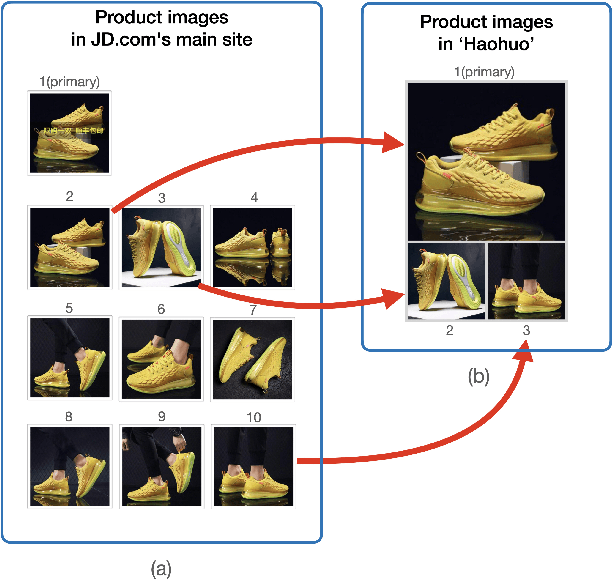

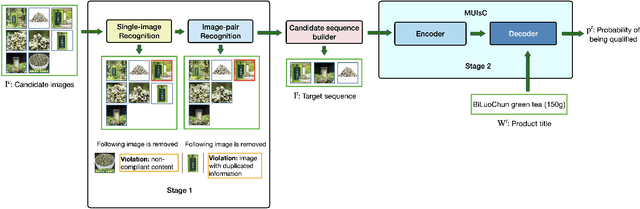
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Trailers12k: Improving Transfer Learning with a Dual Image and Video Transformer for Multi-label Movie Trailer Genre Classification
Oct 19, 2022

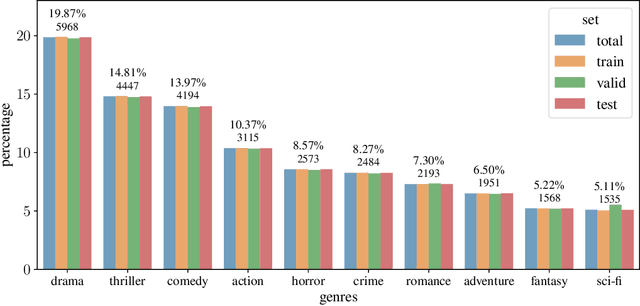
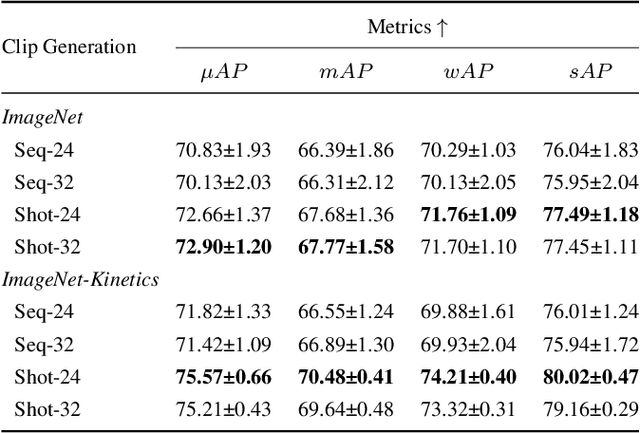
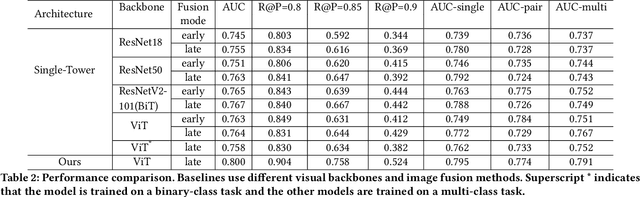
In this paper, we propose Dual Image and Video Transformer Architecture (DIViTA) for multi-label movie trailer genre classification. DIViTA performs an input adaption stage that uses shot detection to segment the trailer into highly correlated clips, providing a more cohesive input that allows to leverage pretrained ImageNet and/or Kinetics backbones. We introduce Trailers12k, a movie trailer dataset with manually verified title-trailer pairs, and present a transferability study of representations learned from ImageNet and Kinetics to Trailers12k. Our results show that DIViTA can reduce the gap between the spatio-temporal structure of the source and target datasets, thus improving transferability. Moreover, representations learned on either ImageNet or Kinetics are comparatively transferable to Trailers12k, although they provide complementary information that can be combined to improve classification performance. Interestingly, pretrained lightweight ConvNets provide competitive classification performance, while using a fraction of the computing resources compared to heavier ConvNets and Transformers.
Sequential image recovery using joint hierarchical Bayesian learning
Jun 25, 2022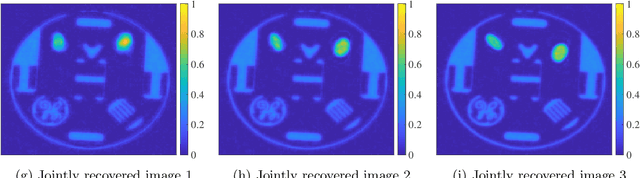
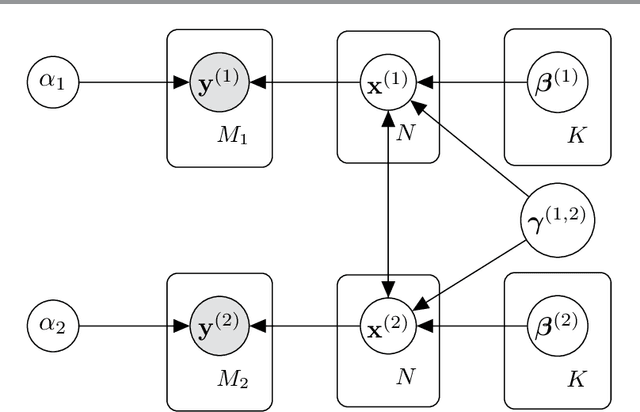
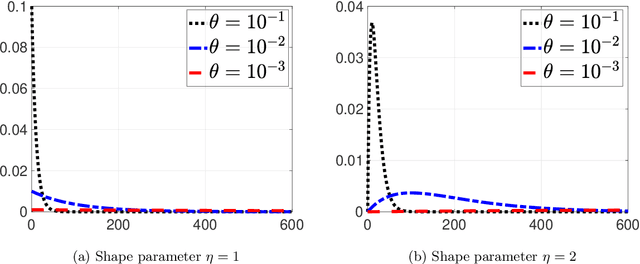
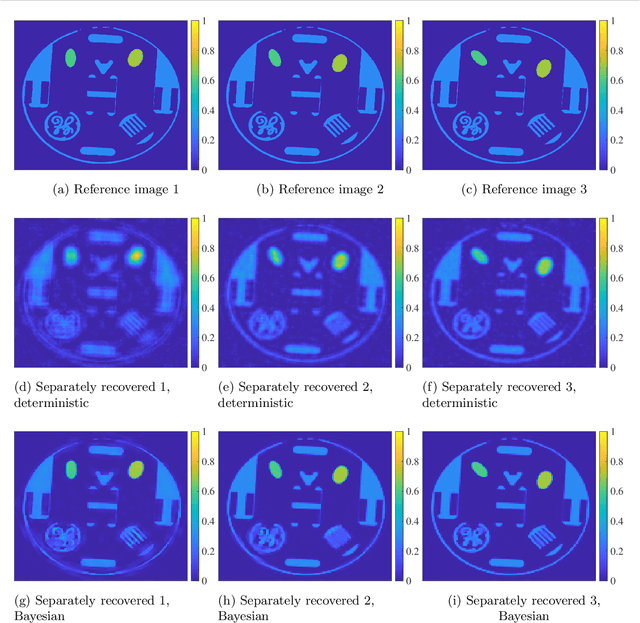
Recovering temporal image sequences (videos) based on indirect, noisy, or incomplete data is an essential yet challenging task. We specifically consider the case where each data set is missing vital information, which prevents the accurate recovery of the individual images. Although some recent (variational) methods have demonstrated high-resolution image recovery based on jointly recovering sequential images, there remain robustness issues due to parameter tuning and restrictions on the type of the sequential images. Here, we present a method based on hierarchical Bayesian learning for the joint recovery of sequential images that incorporates prior intra- and inter-image information. Our method restores the missing information in each image by "borrowing" it from the other images. As a result, \emph{all} of the individual reconstructions yield improved accuracy. Our method can be used for various data acquisitions and allows for uncertainty quantification. Some preliminary results indicate its potential use for sequential deblurring and magnetic resonance imaging.
SwinFIR: Revisiting the SwinIR with Fast Fourier Convolution and Improved Training for Image Super-Resolution
Aug 24, 2022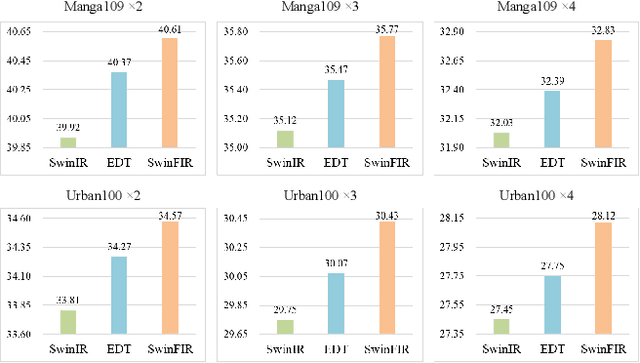
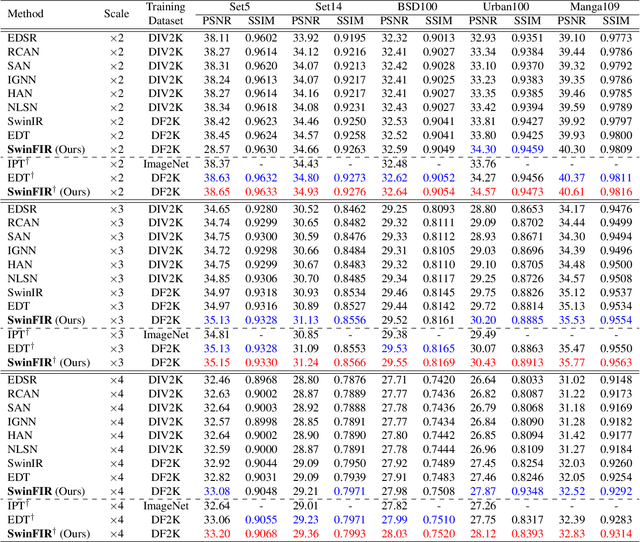


Transformer-based methods have achieved impressive image restoration performance due to their capacities to model long-range dependency compared to CNN-based methods. However, advances like SwinIR adopts the window-based and local attention strategy to balance the performance and computational overhead, which restricts employing large receptive fields to capture global information and establish long dependencies in the early layers. To further improve the efficiency of capturing global information, in this work, we propose SwinFIR to extend SwinIR by replacing Fast Fourier Convolution (FFC) components, which have the image-wide receptive field. We also revisit other advanced techniques, i.e, data augmentation, pre-training, and feature ensemble to improve the effect of image reconstruction. And our feature ensemble method enables the performance of the model to be considerably enhanced without increasing the training and testing time. We applied our algorithm on multiple popular large-scale benchmarks and achieved state-of-the-art performance comparing to the existing methods. For example, our SwinFIR achieves the PSNR of 32.83 dB on Manga109 dataset, which is 0.8 dB higher than the state-of-the-art SwinIR method.
Exploring Negatives in Contrastive Learning for Unpaired Image-to-Image Translation
Apr 23, 2022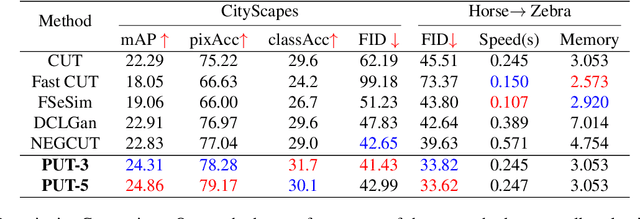
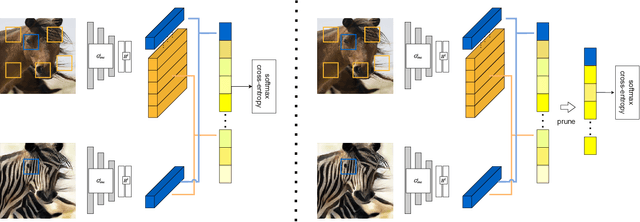

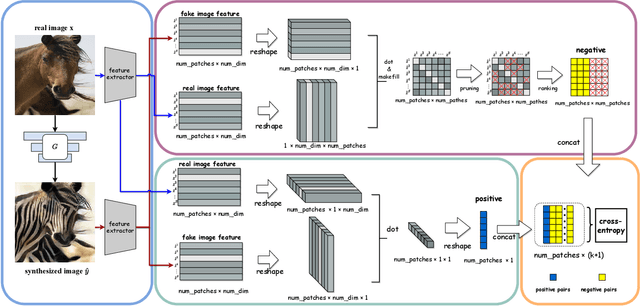
Unpaired image-to-image translation aims to find a mapping between the source domain and the target domain. To alleviate the problem of the lack of supervised labels for the source images, cycle-consistency based methods have been proposed for image structure preservation by assuming a reversible relationship between unpaired images. However, this assumption only uses limited correspondence between image pairs. Recently, contrastive learning (CL) has been used to further investigate the image correspondence in unpaired image translation by using patch-based positive/negative learning. Patch-based contrastive routines obtain the positives by self-similarity computation and recognize the rest patches as negatives. This flexible learning paradigm obtains auxiliary contextualized information at a low cost. As the negatives own an impressive sample number, with curiosity, we make an investigation based on a question: are all negatives necessary for feature contrastive learning? Unlike previous CL approaches that use negatives as much as possible, in this paper, we study the negatives from an information-theoretic perspective and introduce a new negative Pruning technology for Unpaired image-to-image Translation (PUT) by sparsifying and ranking the patches. The proposed algorithm is efficient, flexible and enables the model to learn essential information between corresponding patches stably. By putting quality over quantity, only a few negative patches are required to achieve better results. Lastly, we validate the superiority, stability, and versatility of our model through comparative experiments.
Audio-Visual Segmentation with Semantics
Jan 30, 2023
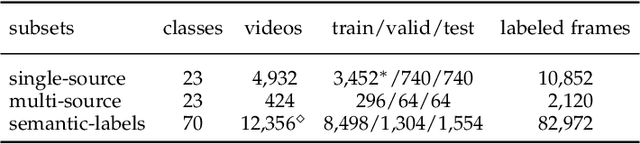
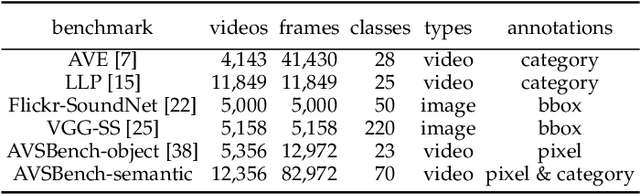
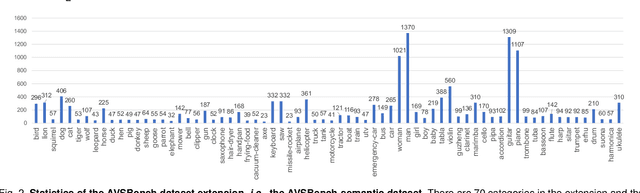
We propose a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark, i.e., AVSBench, providing pixel-wise annotations for sounding objects in audible videos. It contains three subsets: AVSBench-object (Single-source subset, Multi-sources subset) and AVSBench-semantic (Semantic-labels subset). Accordingly, three settings are studied: 1) semi-supervised audio-visual segmentation with a single sound source; 2) fully-supervised audio-visual segmentation with multiple sound sources, and 3) fully-supervised audio-visual semantic segmentation. The first two settings need to generate binary masks of sounding objects indicating pixels corresponding to the audio, while the third setting further requires generating semantic maps indicating the object category. To deal with these problems, we propose a new baseline method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage audio-visual mapping during training. Quantitative and qualitative experiments on AVSBench compare our approach to several existing methods for related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench. Online benchmark is available at http://www.avlbench.opennlplab.cn.
ShadowDiffusion: When Degradation Prior Meets Diffusion Model for Shadow Removal
Dec 09, 2022
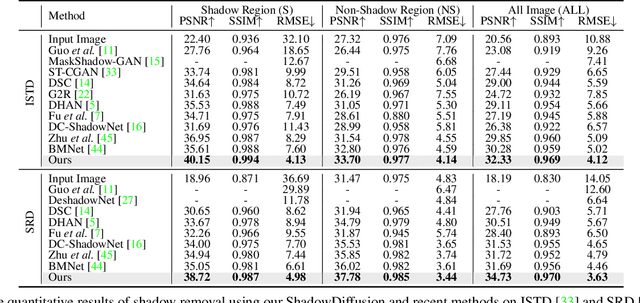
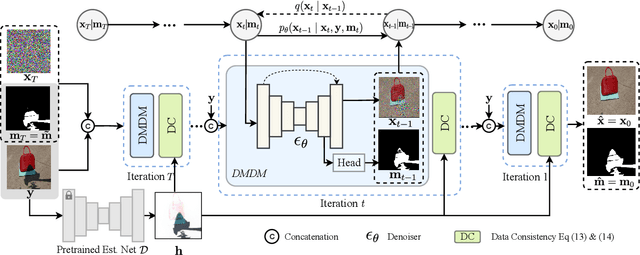
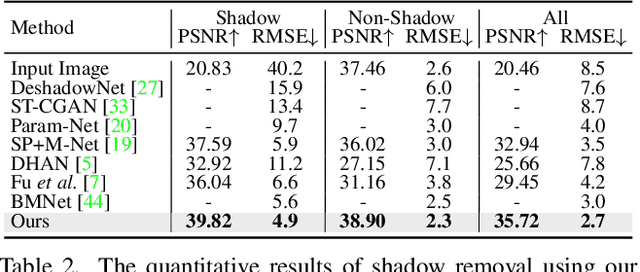
Recent deep learning methods have achieved promising results in image shadow removal. However, their restored images still suffer from unsatisfactory boundary artifacts, due to the lack of degradation prior embedding and the deficiency in modeling capacity. Our work addresses these issues by proposing a unified diffusion framework that integrates both the image and degradation priors for highly effective shadow removal. In detail, we first propose a shadow degradation model, which inspires us to build a novel unrolling diffusion model, dubbed ShandowDiffusion. It remarkably improves the model's capacity in shadow removal via progressively refining the desired output with both degradation prior and diffusive generative prior, which by nature can serve as a new strong baseline for image restoration. Furthermore, ShadowDiffusion progressively refines the estimated shadow mask as an auxiliary task of the diffusion generator, which leads to more accurate and robust shadow-free image generation. We conduct extensive experiments on three popular public datasets, including ISTD, ISTD+, and SRD, to validate our method's effectiveness. Compared to the state-of-the-art methods, our model achieves a significant improvement in terms of PSNR, increasing from 31.69dB to 34.73dB over SRD dataset.
Few-shot Font Generation by Learning Style Difference and Similarity
Jan 24, 2023
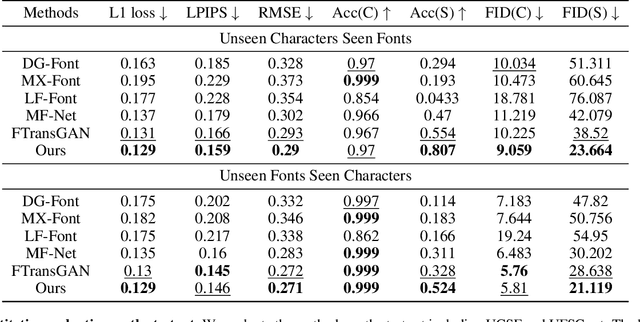
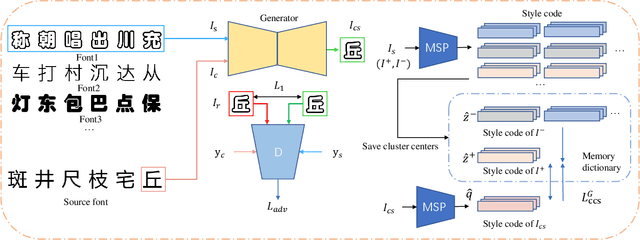
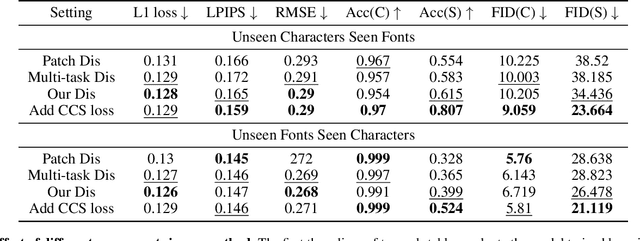
Few-shot font generation (FFG) aims to preserve the underlying global structure of the original character while generating target fonts by referring to a few samples. It has been applied to font library creation, a personalized signature, and other scenarios. Existing FFG methods explicitly disentangle content and style of reference glyphs universally or component-wisely. However, they ignore the difference between glyphs in different styles and the similarity of glyphs in the same style, which results in artifacts such as local distortions and style inconsistency. To address this issue, we propose a novel font generation approach by learning the Difference between different styles and the Similarity of the same style (DS-Font). We introduce contrastive learning to consider the positive and negative relationship between styles. Specifically, we propose a multi-layer style projector for style encoding and realize a distinctive style representation via our proposed Cluster-level Contrastive Style (CCS) loss. In addition, we design a multi-task patch discriminator, which comprehensively considers different areas of the image and ensures that each style can be distinguished independently. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results than state-of-the-art methods.
Stabilised Inverse Flowline Evolution for Anisotropic Image Sharpening
Jul 20, 2022


The central limit theorem suggests Gaussian convolution as a generic blur model for images. Since Gaussian convolution is equivalent to homogeneous diffusion filtering, one way to deblur such images is to diffuse them backwards in time. However, backward diffusion is highly ill-posed. Thus, it requires stabilisation in the model as well as highly sophisticated numerical algorithms. Moreover, sharpening is often only desired across image edges but not along them, since it may cause very irregular contours. This creates the need to model a stabilised anisotropic backward evolution and to devise an appropriate numerical algorithm for this ill-posed process. We address both challenges. First we introduce stabilised inverse flowline evolution (SIFE) as an anisotropic image sharpening flow. Outside extrema, its partial differential equation (PDE) is backward parabolic in gradient direction. Interestingly, it is sufficient to stabilise it in extrema by imposing a zero flow there. We show that morphological derivatives - which are not common in the numerics of PDEs - are ideal for the numerical approximation of SIFE: They effortlessly approximate directional derivatives in gradient direction. Our scheme adapts one-sided morphological derivatives to the underlying image structure. It allows to progress in subpixel accuracy and enables us to prove stability properties. Our experiments show that SIFE allows nonflat steady states and outperforms other sharpening flows.