 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Grokking a Computational Glass Relaxation?
May 16, 2025



Understanding neural network's (NN) generalizability remains a central question in deep learning research. The special phenomenon of grokking, where NNs abruptly generalize long after the training performance reaches a near-perfect level, offers a unique window to investigate the underlying mechanisms of NNs' generalizability. Here we propose an interpretation for grokking by framing it as a computational glass relaxation: viewing NNs as a physical system where parameters are the degrees of freedom and train loss is the system energy, we find memorization process resembles a rapid cooling of liquid into non-equilibrium glassy state at low temperature and the later generalization is like a slow relaxation towards a more stable configuration. This mapping enables us to sample NNs' Boltzmann entropy (states of density) landscape as a function of training loss and test accuracy. Our experiments in transformers on arithmetic tasks suggests that there is NO entropy barrier in the memorization-to-generalization transition of grokking, challenging previous theory that defines grokking as a first-order phase transition. We identify a high-entropy advantage under grokking, an extension of prior work linking entropy to generalizability but much more significant. Inspired by grokking's far-from-equilibrium nature, we develop a toy optimizer WanD based on Wang-landau molecular dynamics, which can eliminate grokking without any constraints and find high-norm generalizing solutions. This provides strictly-defined counterexamples to theory attributing grokking solely to weight norm evolution towards the Goldilocks zone and also suggests new potential ways for optimizer design.
High-entropy Advantage in Neural Networks' Generalizability
Mar 17, 2025While the 2024 Nobel Prize in Physics ignites a worldwide discussion on the origins of neural networks and their foundational links to physics, modern machine learning research predominantly focuses on computational and algorithmic advancements, overlooking a picture of physics. Here we introduce the concept of entropy into neural networks by reconceptualizing them as hypothetical physical systems where each parameter is a non-interacting 'particle' within a one-dimensional space. By employing a Wang-Landau algorithms, we construct the neural networks' (with up to 1 million parameters) entropy landscapes as functions of training loss and test accuracy (or loss) across four distinct machine learning tasks, including arithmetic question, real-world tabular data, image recognition, and language modeling. Our results reveal the existence of \textit{entropy advantage}, where the high-entropy states generally outperform the states reached via classical training optimizer like stochastic gradient descent. We also find this advantage is more pronounced in narrower networks, indicating a need of different training optimizers tailored to different sizes of neural networks.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022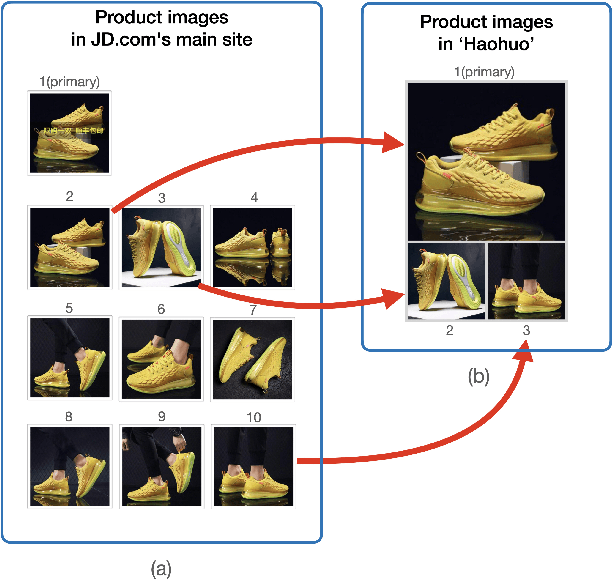

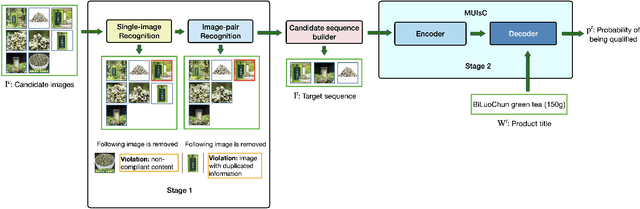
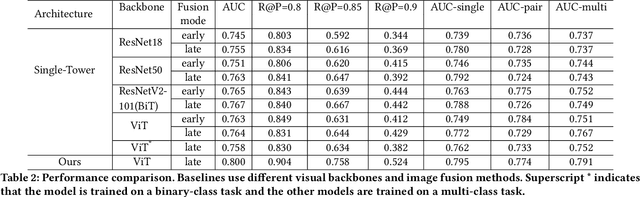
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
TeKo: Text-Rich Graph Neural Networks with External Knowledge
Jun 15, 2022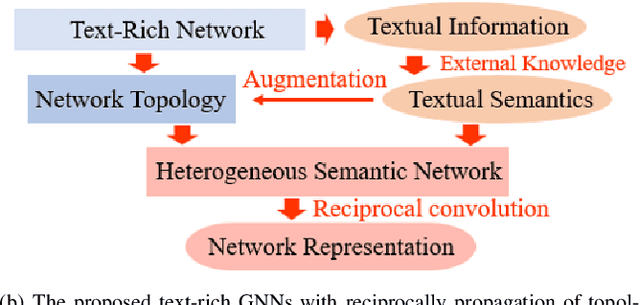
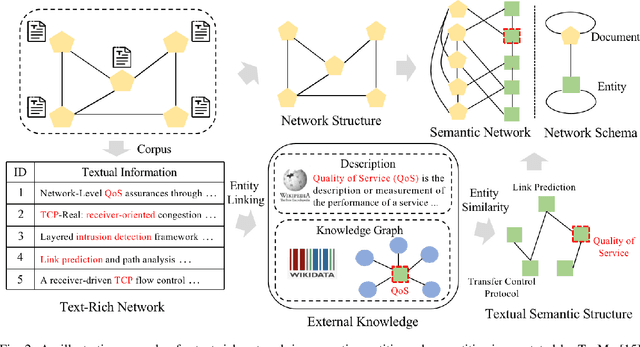
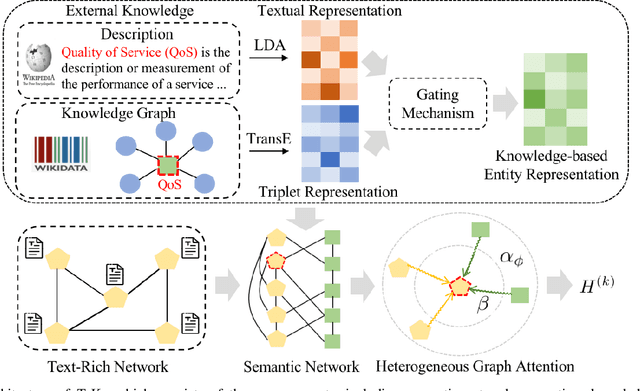

Graph Neural Networks (GNNs) have gained great popularity in tackling various analytical tasks on graph-structured data (i.e., networks). Typical GNNs and their variants follow a message-passing manner that obtains network representations by the feature propagation process along network topology, which however ignore the rich textual semantics (e.g., local word-sequence) that exist in many real-world networks. Existing methods for text-rich networks integrate textual semantics by mainly utilizing internal information such as topics or phrases/words, which often suffer from an inability to comprehensively mine the text semantics, limiting the reciprocal guidance between network structure and text semantics. To address these problems, we propose a novel text-rich graph neural network with external knowledge (TeKo), in order to take full advantage of both structural and textual information within text-rich networks. Specifically, we first present a flexible heterogeneous semantic network that incorporates high-quality entities and interactions among documents and entities. We then introduce two types of external knowledge, that is, structured triplets and unstructured entity description, to gain a deeper insight into textual semantics. We further design a reciprocal convolutional mechanism for the constructed heterogeneous semantic network, enabling network structure and textual semantics to collaboratively enhance each other and learn high-level network representations. Extensive experimental results on four public text-rich networks as well as a large-scale e-commerce searching dataset illustrate the superior performance of TeKo over state-of-the-art baselines.
DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021



We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.
RL4RS: A Real-World Benchmark for Reinforcement Learning based Recommender System
Oct 18, 2021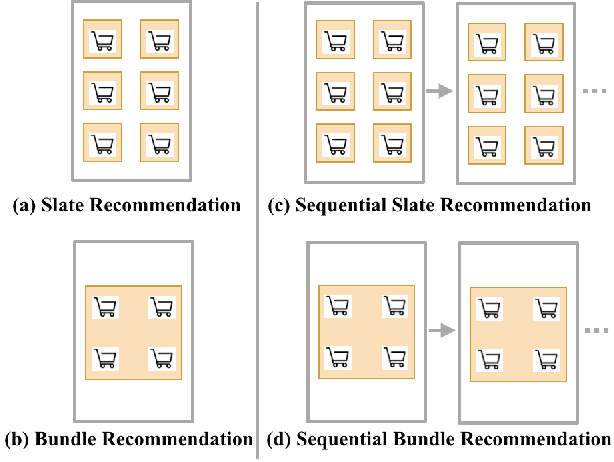
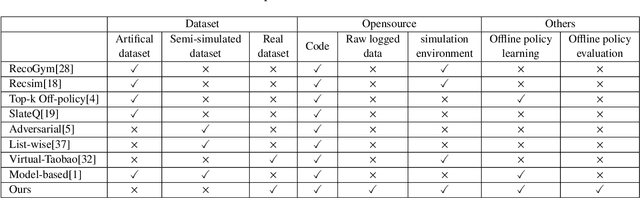
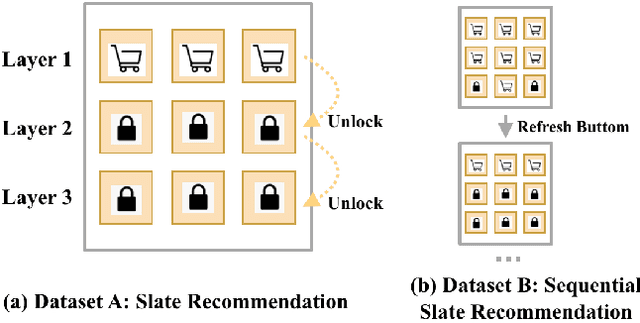
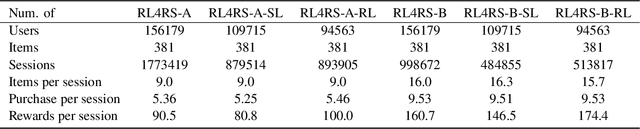
Reinforcement learning based recommender systems (RL-based RS) aims at learning a good policy from a batch of collected data, with casting sequential recommendation to multi-step decision-making tasks. However, current RL-based RS benchmarks commonly have a large reality gap, because they involve artificial RL datasets or semi-simulated RS datasets, and the trained policy is directly evaluated in the simulation environment. In real-world situations, not all recommendation problems are suitable to be transformed into reinforcement learning problems. Unlike previous academic RL researches, RL-based RS suffer from extrapolation error and the difficulties of being well validated before deployment. In this paper, we introduce the RL4RS (Reinforcement Learning for Recommender Systems) benchmark - a new resource fully collected from industrial applications to train and evaluate RL algorithms with special concerns on the above issues. It contains two datasets, tuned simulation environments, related advanced RL baselines, data understanding tools, and counterfactual policy evaluation algorithms. The RL4RS suit can be found at https://github.com/fuxiAIlab/RL4RS. In addition to the RL-based recommender systems, we expect the resource to contribute to research in reinforcement learning and neural combinatorial optimization.
A unified Neural Network Approach to E-CommerceRelevance Learning
Apr 26, 2021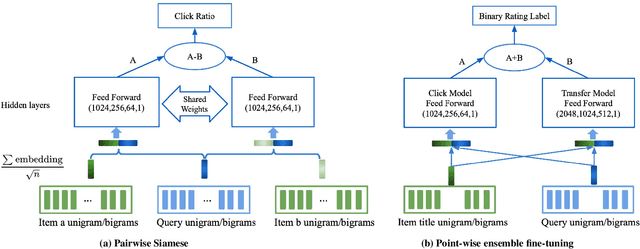



Result relevance scoring is critical to e-commerce search user experience. Traditional information retrieval methods focus on keyword matching and hand-crafted or counting-based numeric features, with limited understanding of item semantic relevance. We describe a highly-scalable feed-forward neural model to provide relevance score for (query, item) pairs, using only user query and item title as features, and both user click feedback as well as limited human ratings as labels. Several general enhancements were applied to further optimize eval/test metrics, including Siamese pairwise architecture, random batch negative co-training, and point-wise fine-tuning. We found significant improvement over GBDT baseline as well as several off-the-shelf deep-learning baselines on an independently constructed ratings dataset. The GBDT model relies on 10 times more features. We also present metrics for select subset combinations of techniques mentioned above.
* 6 pages
Heterogeneous Network Embedding for Deep Semantic Relevance Match in E-commerce Search
Jan 13, 2021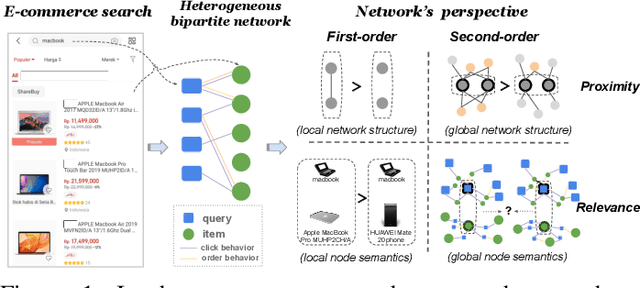
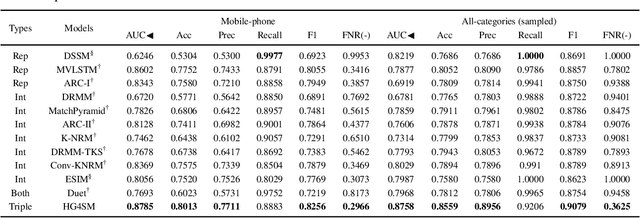
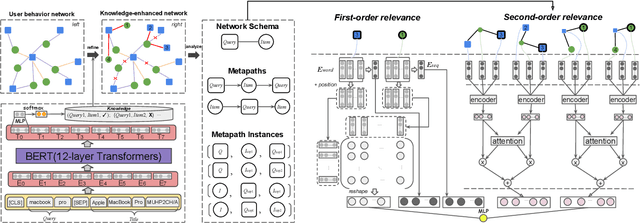
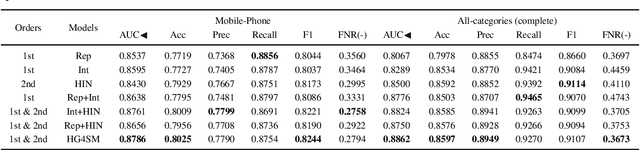
Result relevance prediction is an essential task of e-commerce search engines to boost the utility of search engines and ensure smooth user experience. The last few years eyewitnessed a flurry of research on the use of Transformer-style models and deep text-match models to improve relevance. However, these two types of models ignored the inherent bipartite network structures that are ubiquitous in e-commerce search logs, making these models ineffective. We propose in this paper a novel Second-order Relevance, which is fundamentally different from the previous First-order Relevance, to improve result relevance prediction. We design, for the first time, an end-to-end First-and-Second-order Relevance prediction model for e-commerce item relevance. The model is augmented by the neighborhood structures of bipartite networks that are built using the information of user behavioral feedback, including clicks and purchases. To ensure that edges accurately encode relevance information, we introduce external knowledge generated from BERT to refine the network of user behaviors. This allows the new model to integrate information from neighboring items and queries, which are highly relevant to the focus query-item pair under consideration. Results of offline experiments showed that the new model significantly improved the prediction accuracy in terms of human relevance judgment. An ablation study showed that the First-and-Second-order model gained a 4.3% average gain over the First-order model. Results of an online A/B test revealed that the new model derived more commercial benefits compared to the base model.
BERT2DNN: BERT Distillation with Massive Unlabeled Data for Online E-Commerce Search
Oct 20, 2020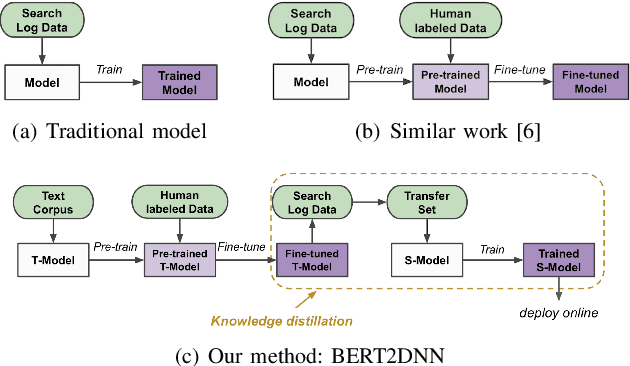

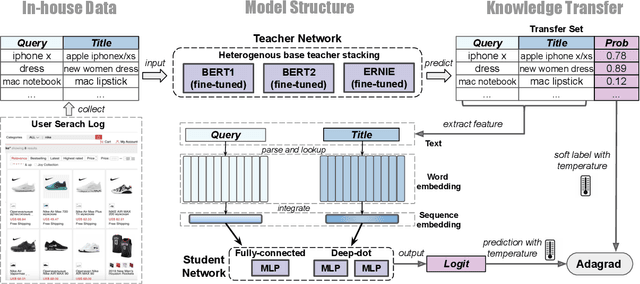
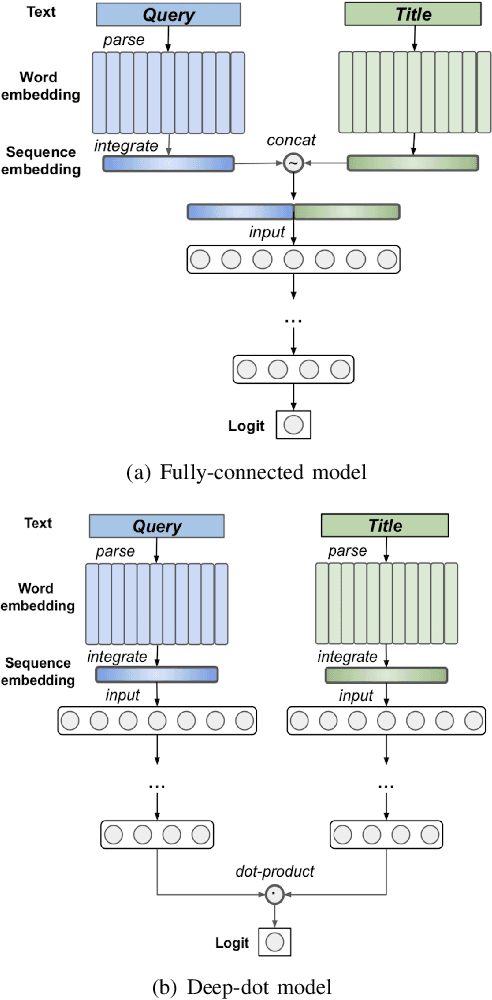
Relevance has significant impact on user experience and business profit for e-commerce search platform. In this work, we propose a data-driven framework for search relevance prediction, by distilling knowledge from BERT and related multi-layer Transformer teacher models into simple feed-forward networks with large amount of unlabeled data. The distillation process produces a student model that recovers more than 97\% test accuracy of teacher models on new queries, at a serving cost that's several magnitude lower (latency 150x lower than BERT-Base and 15x lower than the most efficient BERT variant, TinyBERT). The applications of temperature rescaling and teacher model stacking further boost model accuracy, without increasing the student model complexity. We present experimental results on both in-house e-commerce search relevance data as well as a public data set on sentiment analysis from the GLUE benchmark. The latter takes advantage of another related public data set of much larger scale, while disregarding its potentially noisy labels. Embedding analysis and case study on the in-house data further highlight the strength of the resulting model. By making the data processing and model training source code public, we hope the techniques presented here can help reduce energy consumption of the state of the art Transformer models and also level the playing field for small organizations lacking access to cutting edge machine learning hardwares.
Fine-tune BERT for E-commerce Non-Default Search Ranking
Aug 21, 2020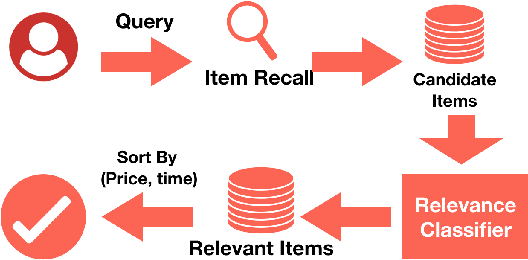
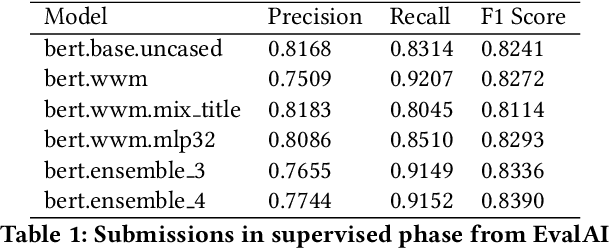
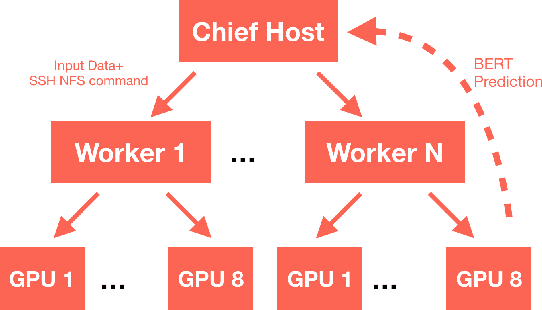
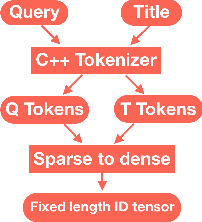
The quality of non-default ranking on e-commerce platforms, such as based on ascending item price or descending historical sales volume, often suffers from acute relevance problems, since the irrelevant items are much easier to be exposed at the top of the ranking results. In this work, we propose a two-stage ranking scheme, which first recalls wide range of candidate items through refined query/title keyword matching, and then classifies the recalled items using BERT-Large fine-tuned on human label data. We also implemented parallel prediction on multiple GPU hosts and a C++ tokenization custom op of Tensorflow. In this data challenge, our model won the 1st place in the supervised phase (based on overall F1 score) and 2nd place in the final phase (based on average per query F1 score).