 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPNSR: Prior-Enhanced Diffusion Image Super-Resolution via LR-Guided Noise Prediction
Mar 22, 2026Diffusion-based image super-resolution (SR), which aims to reconstruct high-resolution (HR) images from corresponding low-resolution (LR) observations, faces a fundamental trade-off between inference efficiency and reconstruction quality. The state-of-the-art residual-shifting diffusion framework achieves efficient 4-step inference, yet suffers from severe performance degradation in compact sampling trajectories. This is mainly attributed to two core limitations: the inherent suboptimality of unconstrained random Gaussian noise in intermediate steps, which leads to error accumulation and insufficient LR prior guidance, and the initialization bias caused by naive bicubic upsampling. In this paper, we propose LPNSR, a prior-enhanced efficient diffusion framework to address these issues. We first mathematically derive the closed-form analytical solution of the optimal intermediate noise for the residual-shifting diffusion paradigm, and accordingly design an LR-guided multi-input-aware noise predictor to replace random Gaussian noise, embedding LR structural priors into the reverse process while fully preserving the framework's core efficient residual-shifting mechanism. We further mitigate initial bias with a high-quality pre-upsampling network to optimize the diffusion starting point. With a compact 4-step trajectory, LPNSR can be optimized in an end-to-end manner. Extensive experiments demonstrate that LPNSR achieves state-of-the-art perceptual performance on both synthetic and real-world datasets, without relying on any large-scale text-to-image priors. The source code of our method can be found at https://github.com/Faze-Hsw/LPNSR.
Enhancing Noise Resilience in Face Clustering via Sparse Differential Transformer
Dec 27, 2025The method used to measure relationships between face embeddings plays a crucial role in determining the performance of face clustering. Existing methods employ the Jaccard similarity coefficient instead of the cosine distance to enhance the measurement accuracy. However, these methods introduce too many irrelevant nodes, producing Jaccard coefficients with limited discriminative power and adversely affecting clustering performance. To address this issue, we propose a prediction-driven Top-K Jaccard similarity coefficient that enhances the purity of neighboring nodes, thereby improving the reliability of similarity measurements. Nevertheless, accurately predicting the optimal number of neighbors (Top-K) remains challenging, leading to suboptimal clustering results. To overcome this limitation, we develop a Transformer-based prediction model that examines the relationships between the central node and its neighboring nodes near the Top-K to further enhance the reliability of similarity estimation. However, vanilla Transformer, when applied to predict relationships between nodes, often introduces noise due to their overemphasis on irrelevant feature relationships. To address these challenges, we propose a Sparse Differential Transformer (SDT), instead of the vanilla Transformer, to eliminate noise and enhance the model's anti-noise capabilities. Extensive experiments on multiple datasets, such as MS-Celeb-1M, demonstrate that our approach achieves state-of-the-art (SOTA) performance, outperforming existing methods and providing a more robust solution for face clustering.
From Cradle to Cane: A Two-Pass Framework for High-Fidelity Lifespan Face Aging
Jun 26, 2025



Face aging has become a crucial task in computer vision, with applications ranging from entertainment to healthcare. However, existing methods struggle with achieving a realistic and seamless transformation across the entire lifespan, especially when handling large age gaps or extreme head poses. The core challenge lies in balancing age accuracy and identity preservation--what we refer to as the Age-ID trade-off. Most prior methods either prioritize age transformation at the expense of identity consistency or vice versa. In this work, we address this issue by proposing a two-pass face aging framework, named Cradle2Cane, based on few-step text-to-image (T2I) diffusion models. The first pass focuses on solving age accuracy by introducing an adaptive noise injection (AdaNI) mechanism. This mechanism is guided by including prompt descriptions of age and gender for the given person as the textual condition. Also, by adjusting the noise level, we can control the strength of aging while allowing more flexibility in transforming the face. However, identity preservation is weakly ensured here to facilitate stronger age transformations. In the second pass, we enhance identity preservation while maintaining age-specific features by conditioning the model on two identity-aware embeddings (IDEmb): SVR-ArcFace and Rotate-CLIP. This pass allows for denoising the transformed image from the first pass, ensuring stronger identity preservation without compromising the aging accuracy. Both passes are jointly trained in an end-to-end way. Extensive experiments on the CelebA-HQ test dataset, evaluated through Face++ and Qwen-VL protocols, show that our Cradle2Cane outperforms existing face aging methods in age accuracy and identity consistency.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022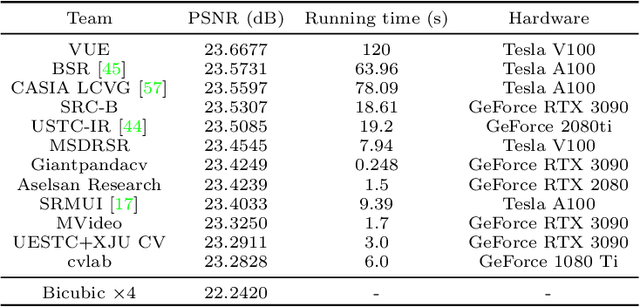
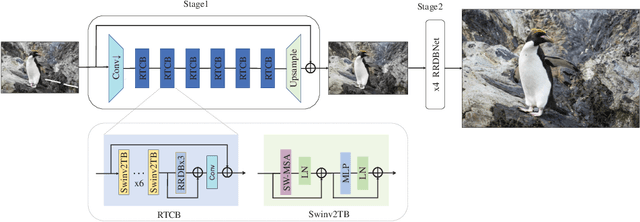

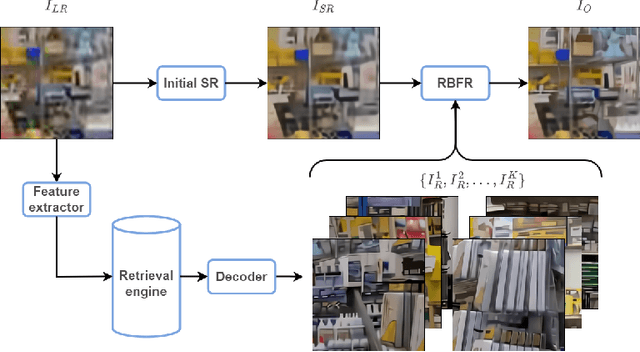
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
SwinFIR: Revisiting the SwinIR with Fast Fourier Convolution and Improved Training for Image Super-Resolution
Aug 24, 2022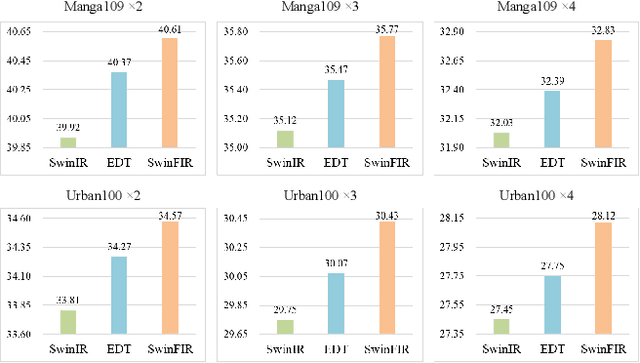
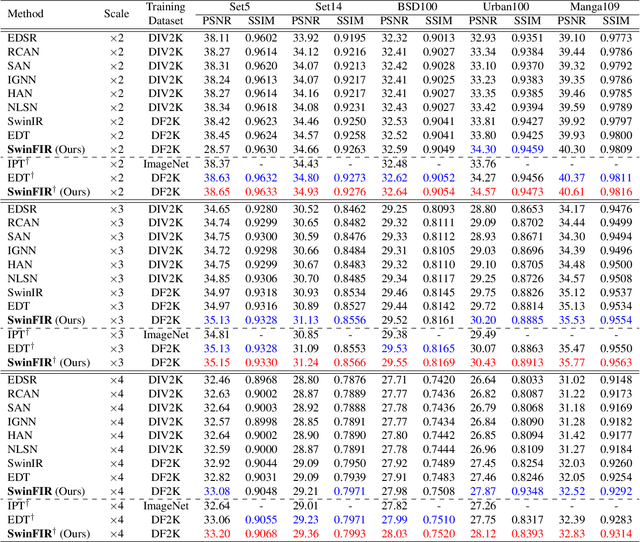


Transformer-based methods have achieved impressive image restoration performance due to their capacities to model long-range dependency compared to CNN-based methods. However, advances like SwinIR adopts the window-based and local attention strategy to balance the performance and computational overhead, which restricts employing large receptive fields to capture global information and establish long dependencies in the early layers. To further improve the efficiency of capturing global information, in this work, we propose SwinFIR to extend SwinIR by replacing Fast Fourier Convolution (FFC) components, which have the image-wide receptive field. We also revisit other advanced techniques, i.e, data augmentation, pre-training, and feature ensemble to improve the effect of image reconstruction. And our feature ensemble method enables the performance of the model to be considerably enhanced without increasing the training and testing time. We applied our algorithm on multiple popular large-scale benchmarks and achieved state-of-the-art performance comparing to the existing methods. For example, our SwinFIR achieves the PSNR of 32.83 dB on Manga109 dataset, which is 0.8 dB higher than the state-of-the-art SwinIR method.