 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Chain-of-Thought Search: Searching the Optimal Reasoning Path to Enhance Large Language Models
Jan 16, 2026Chain-of-Thought reasoning has significantly enhanced the problem-solving capabilities of Large Language Models. Unfortunately, current models generate reasoning steps sequentially without foresight, often becoming trapped in suboptimal reasoning paths with redundant steps. In contrast, we introduce Neural Chain-of-Thought Search (NCoTS), a framework that reformulates reasoning as a dynamic search for the optimal thinking strategy. By quantitatively characterizing the solution space, we reveal the existence of sparse superior reasoning paths that are simultaneously more accurate and concise than standard outputs. Our method actively navigates towards these paths by evaluating candidate reasoning operators using a dual-factor heuristic that optimizes for both correctness and computational cost. Consequently, NCoTS achieves a Pareto improvement across diverse reasoning benchmarks, boosting accuracy by over 3.5% while reducing generation length by over 22%. Our code and data are available at https://github.com/MilkThink-Lab/Neural-CoT-Search.
CrossDehaze: Scaling Up Image Dehazing with Cross-Data Vision Alignment and Augmentation
Jul 20, 2024



In recent years, as computer vision tasks have increasingly relied on high-quality image inputs, the task of image dehazing has received significant attention. Previously, many methods based on priors and deep learning have been proposed to address the task of image dehazing. Ignoring the domain gap between different data, former de-hazing methods usually adopt multiple datasets for explicit training, which often makes the methods themselves be violated. To address this problem, we propose a novel method of internal and external data augmentation to improve the existing dehazing methodology. By using cross-data external augmentor. The dataset inherits samples from different domains that are firmly aligned, making the model learn more robust and generalizable features. By using the internal data augmentation method, the model can fully exploit local information within the images, thereby obtaining more image details. To demonstrate the effectiveness of our proposed method, we conduct training on both the Natural Image Dataset (NID) and the Remote Sensing Image Dataset (RSID). Experimental results show that our method clearly resolves the domain gap in different dehazing datasets and presents a new pipeline for joint training in the dehazing task. Our approach significantly outperforms other advanced methods in dehazing and produces dehazed images that are closest to real haze-free images. The code will be available at: https://github.com/wengzp1/ScaleUpDehazing
Diff-Mosaic: Augmenting Realistic Representations in Infrared Small Target Detection via Diffusion Prior
Jun 02, 2024Recently, researchers have proposed various deep learning methods to accurately detect infrared targets with the characteristics of indistinct shape and texture. Due to the limited variety of infrared datasets, training deep learning models with good generalization poses a challenge. To augment the infrared dataset, researchers employ data augmentation techniques, which often involve generating new images by combining images from different datasets. However, these methods are lacking in two respects. In terms of realism, the images generated by mixup-based methods lack realism and are difficult to effectively simulate complex real-world scenarios. In terms of diversity, compared with real-world scenes, borrowing knowledge from another dataset inherently has a limited diversity. Currently, the diffusion model stands out as an innovative generative approach. Large-scale trained diffusion models have a strong generative prior that enables real-world modeling of images to generate diverse and realistic images. In this paper, we propose Diff-Mosaic, a data augmentation method based on the diffusion model. This model effectively alleviates the challenge of diversity and realism of data augmentation methods via diffusion prior. Specifically, our method consists of two stages. Firstly, we introduce an enhancement network called Pixel-Prior, which generates highly coordinated and realistic Mosaic images by harmonizing pixels. In the second stage, we propose an image enhancement strategy named Diff-Prior. This strategy utilizes diffusion priors to model images in the real-world scene, further enhancing the diversity and realism of the images. Extensive experiments have demonstrated that our approach significantly improves the performance of the detection network. The code is available at https://github.com/YupeiLin2388/Diff-Mosaic
SIRST-5K: Exploring Massive Negatives Synthesis with Self-supervised Learning for Robust Infrared Small Target Detection
Mar 08, 2024



Single-frame infrared small target (SIRST) detection aims to recognize small targets from clutter backgrounds. Recently, convolutional neural networks have achieved significant advantages in general object detection. With the development of Transformer, the scale of SIRST models is constantly increasing. Due to the limited training samples, performance has not been improved accordingly. The quality, quantity, and diversity of the infrared dataset are critical to the detection of small targets. To highlight this issue, we propose a negative sample augmentation method in this paper. Specifically, a negative augmentation approach is proposed to generate massive negatives for self-supervised learning. Firstly, we perform a sequential noise modeling technology to generate realistic infrared data. Secondly, we fuse the extracted noise with the original data to facilitate diversity and fidelity in the generated data. Lastly, we proposed a negative augmentation strategy to enrich diversity as well as maintain semantic invariance. The proposed algorithm produces a synthetic SIRST-5K dataset, which contains massive pseudo-data and corresponding labels. With a rich diversity of infrared small target data, our algorithm significantly improves the model performance and convergence speed. Compared with other state-of-the-art (SOTA) methods, our method achieves outstanding performance in terms of probability of detection (Pd), false-alarm rate (Fa), and intersection over union (IoU).
MirrorDiffusion: Stabilizing Diffusion Process in Zero-shot Image Translation by Prompts Redescription and Beyond
Jan 06, 2024Recently, text-to-image diffusion models become a new paradigm in image processing fields, including content generation, image restoration and image-to-image translation. Given a target prompt, Denoising Diffusion Probabilistic Models (DDPM) are able to generate realistic yet eligible images. With this appealing property, the image translation task has the potential to be free from target image samples for supervision. By using a target text prompt for domain adaption, the diffusion model is able to implement zero-shot image-to-image translation advantageously. However, the sampling and inversion processes of DDPM are stochastic, and thus the inversion process often fail to reconstruct the input content. Specifically, the displacement effect will gradually accumulated during the diffusion and inversion processes, which led to the reconstructed results deviating from the source domain. To make reconstruction explicit, we propose a prompt redescription strategy to realize a mirror effect between the source and reconstructed image in the diffusion model (MirrorDiffusion). More specifically, a prompt redescription mechanism is investigated to align the text prompts with latent code at each time step of the Denoising Diffusion Implicit Models (DDIM) inversion to pursue a structure-preserving reconstruction. With the revised DDIM inversion, MirrorDiffusion is able to realize accurate zero-shot image translation by editing optimized text prompts and latent code. Extensive experiments demonstrate that MirrorDiffusion achieves superior performance over the state-of-the-art methods on zero-shot image translation benchmarks by clear margins and practical model stability.
ReGeneration Learning of Diffusion Models with Rich Prompts for Zero-Shot Image Translation
May 08, 2023Large-scale text-to-image models have demonstrated amazing ability to synthesize diverse and high-fidelity images. However, these models are often violated by several limitations. Firstly, they require the user to provide precise and contextually relevant descriptions for the desired image modifications. Secondly, current models can impose significant changes to the original image content during the editing process. In this paper, we explore ReGeneration learning in an image-to-image Diffusion model (ReDiffuser), that preserves the content of the original image without human prompting and the requisite editing direction is automatically discovered within the text embedding space. To ensure consistent preservation of the shape during image editing, we propose cross-attention guidance based on regeneration learning. This novel approach allows for enhanced expression of the target domain features while preserving the original shape of the image. In addition, we introduce a cooperative update strategy, which allows for efficient preservation of the original shape of an image, thereby improving the quality and consistency of shape preservation throughout the editing process. Our proposed method leverages an existing pre-trained text-image diffusion model without any additional training. Extensive experiments show that the proposed method outperforms existing work in both real and synthetic image editing.
Exploring Negatives in Contrastive Learning for Unpaired Image-to-Image Translation
Apr 23, 2022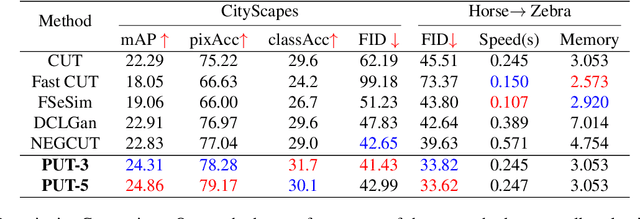
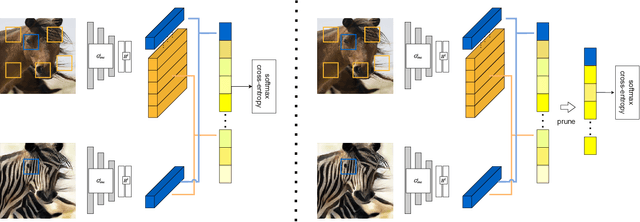

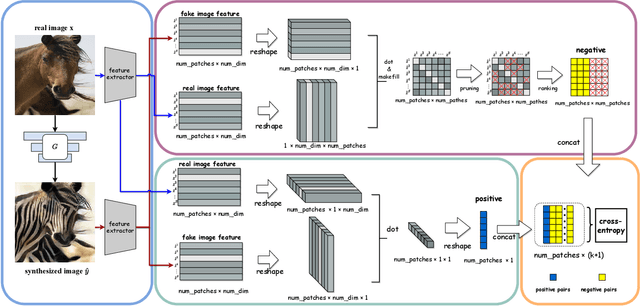
Unpaired image-to-image translation aims to find a mapping between the source domain and the target domain. To alleviate the problem of the lack of supervised labels for the source images, cycle-consistency based methods have been proposed for image structure preservation by assuming a reversible relationship between unpaired images. However, this assumption only uses limited correspondence between image pairs. Recently, contrastive learning (CL) has been used to further investigate the image correspondence in unpaired image translation by using patch-based positive/negative learning. Patch-based contrastive routines obtain the positives by self-similarity computation and recognize the rest patches as negatives. This flexible learning paradigm obtains auxiliary contextualized information at a low cost. As the negatives own an impressive sample number, with curiosity, we make an investigation based on a question: are all negatives necessary for feature contrastive learning? Unlike previous CL approaches that use negatives as much as possible, in this paper, we study the negatives from an information-theoretic perspective and introduce a new negative Pruning technology for Unpaired image-to-image Translation (PUT) by sparsifying and ranking the patches. The proposed algorithm is efficient, flexible and enables the model to learn essential information between corresponding patches stably. By putting quality over quantity, only a few negative patches are required to achieve better results. Lastly, we validate the superiority, stability, and versatility of our model through comparative experiments.