 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Local Differential Privacy Image Generation Using Flow-based Deep Generative Models
Dec 20, 2022

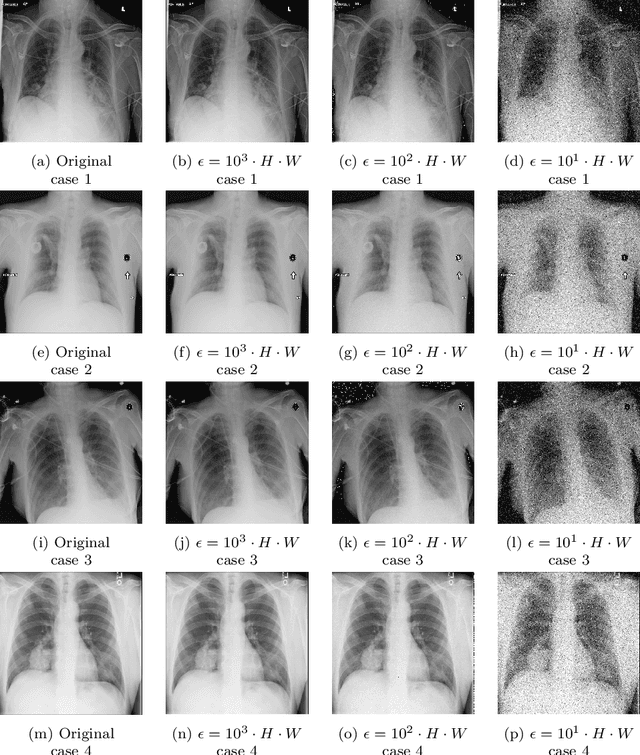

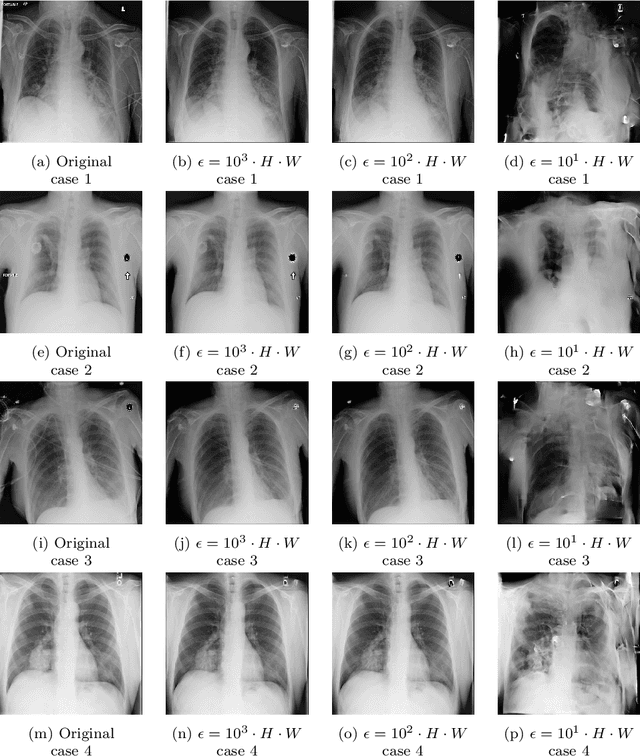
Diagnostic radiologists need artificial intelligence (AI) for medical imaging, but access to medical images required for training in AI has become increasingly restrictive. To release and use medical images, we need an algorithm that can simultaneously protect privacy and preserve pathologies in medical images. To develop such an algorithm, here, we propose DP-GLOW, a hybrid of a local differential privacy (LDP) algorithm and one of the flow-based deep generative models (GLOW). By applying a GLOW model, we disentangle the pixelwise correlation of images, which makes it difficult to protect privacy with straightforward LDP algorithms for images. Specifically, we map images onto the latent vector of the GLOW model, each element of which follows an independent normal distribution, and we apply the Laplace mechanism to the latent vector. Moreover, we applied DP-GLOW to chest X-ray images to generate LDP images while preserving pathologies.
AugNet: Dynamic Test-Time Augmentation via Differentiable Functions
Dec 09, 2022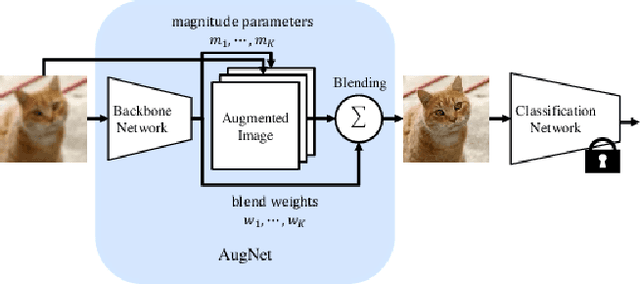
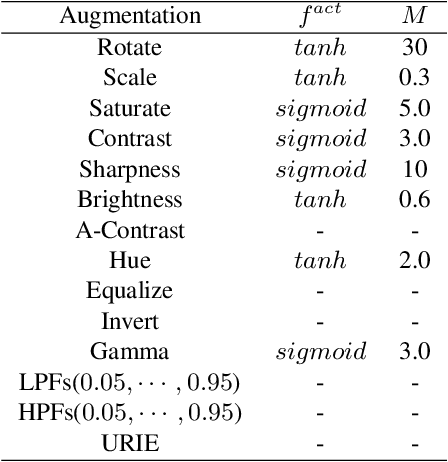
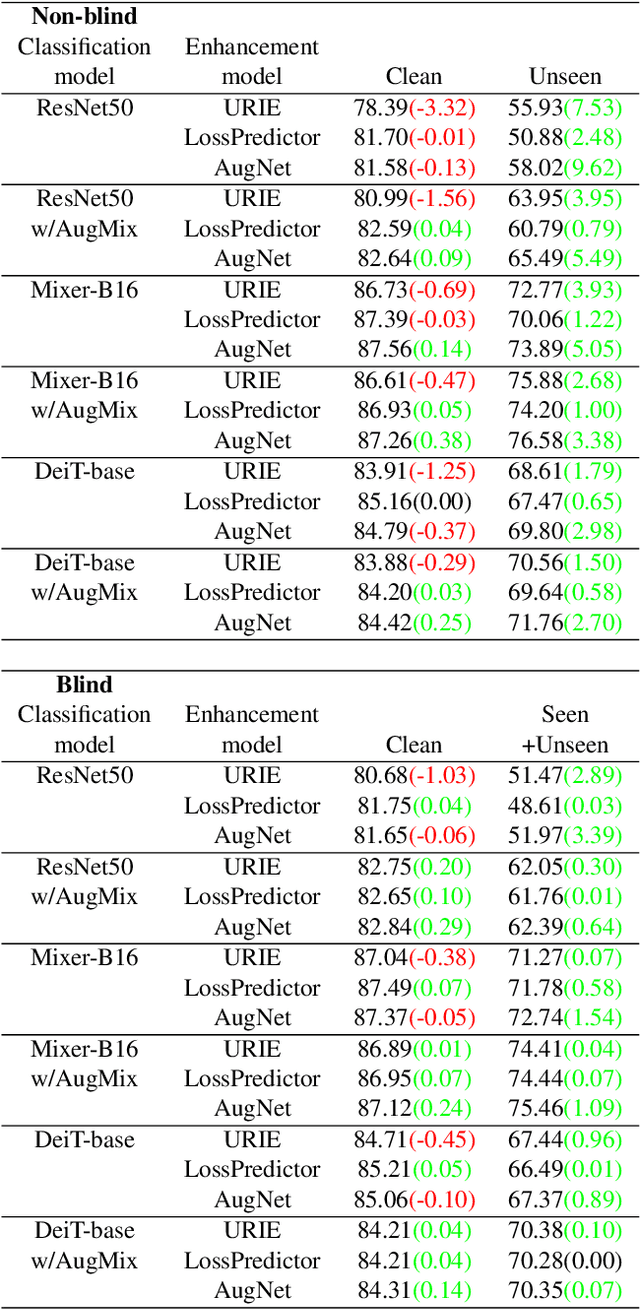
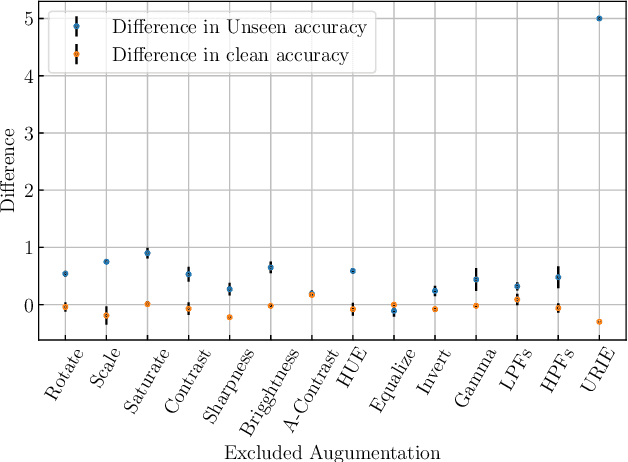
Distribution shifts, which often occur in the real world, degrade the accuracy of deep learning systems, and thus improving robustness is essential for practical applications. To improve robustness, we study an image enhancement method that generates recognition-friendly images without retraining the recognition model. We propose a novel image enhancement method, AugNet, which is based on differentiable data augmentation techniques and generates a blended image from many augmented images to improve the recognition accuracy under distribution shifts. In addition to standard data augmentations, AugNet can also incorporate deep neural network-based image transformation, which further improves the robustness. Because AugNet is composed of differentiable functions, AugNet can be directly trained with the classification loss of the recognition model. AugNet is evaluated on widely used image recognition datasets using various classification models, including Vision Transformer and MLP-Mixer. AugNet improves the robustness with almost no reduction in classification accuracy for clean images, which is a better result than the existing methods. Furthermore, we show that interpretation of distribution shifts using AugNet and retraining based on that interpretation can greatly improve robustness.
VertXNet: An Ensemble Method for Vertebrae Segmentation and Identification of Spinal X-Ray
Feb 07, 2023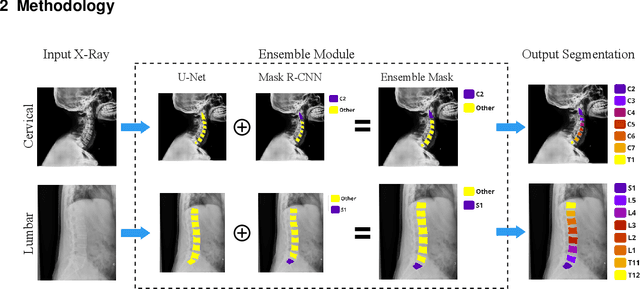
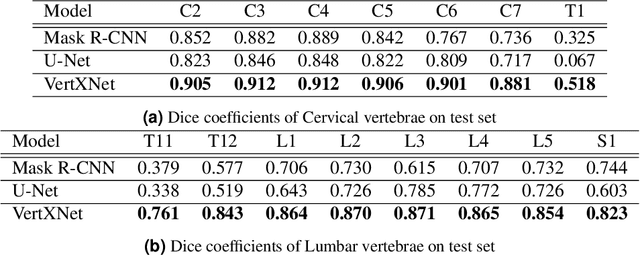
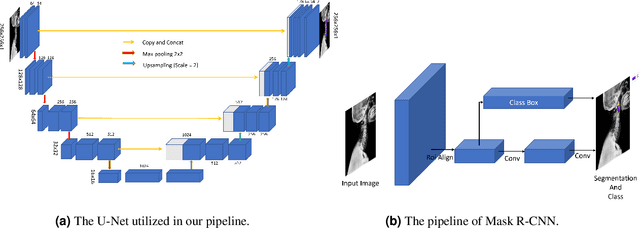
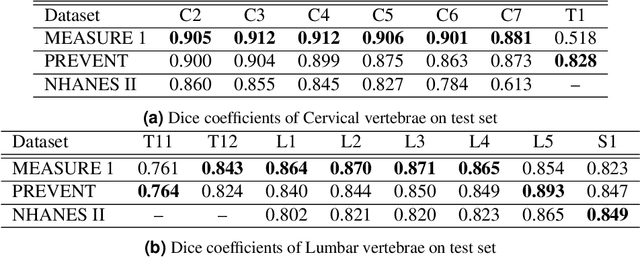
Reliable vertebrae annotations are key to perform analysis of spinal X-ray images. However, obtaining annotation of vertebrae from those images is usually carried out manually due to its complexity (i.e. small structures with varying shape), making it a costly and tedious process. To accelerate this process, we proposed an ensemble pipeline, VertXNet, that combines two state-of-the-art (SOTA) segmentation models (respectively U-Net and Mask R-CNN) to automatically segment and label vertebrae in X-ray spinal images. Moreover, VertXNet introduces a rule-based approach that allows to robustly infer vertebrae labels (by locating the 'reference' vertebrae which are easier to segment than others) for a given spinal X-ray image. We evaluated the proposed pipeline on three spinal X-ray datasets (two internal and one publicly available), and compared against vertebrae annotated by radiologists. Our experimental results have shown that the proposed pipeline outperformed two SOTA segmentation models on our test dataset (MEASURE 1) with a mean Dice of 0.90, vs. a mean Dice of 0.73 for Mask R-CNN and 0.72 for U-Net. To further evaluate the generalization ability of VertXNet, the pre-trained pipeline was directly tested on two additional datasets (PREVENT and NHANES II) and consistent performance was observed with a mean Dice of 0.89 and 0.88, respectively. Overall, VertXNet demonstrated significantly improved performance for vertebra segmentation and labeling for spinal X-ray imaging, and evaluation on both in-house clinical trial data and publicly available data further proved its generalization.
Meta-Registration: Learning Test-Time Optimization for Single-Pair Image Registration
Jul 22, 2022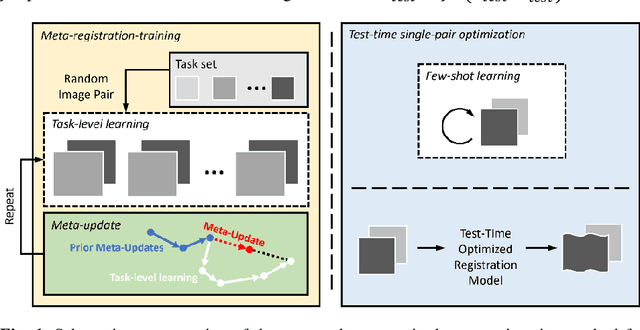
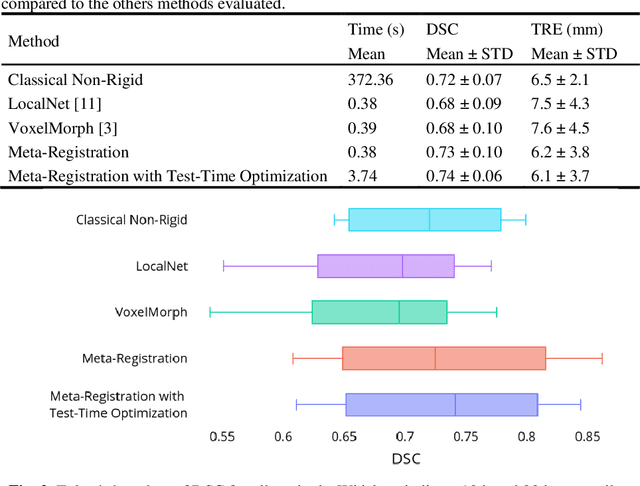
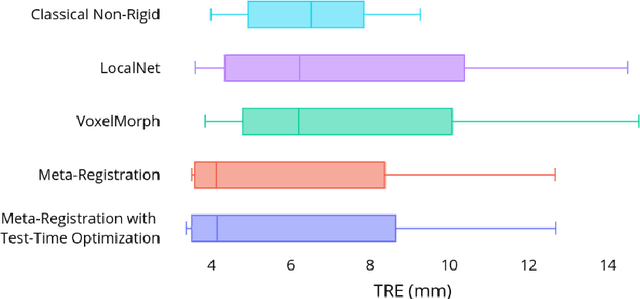

Neural networks have been proposed for medical image registration by learning, with a substantial amount of training data, the optimal transformations between image pairs. These trained networks can further be optimized on a single pair of test images - known as test-time optimization. This work formulates image registration as a meta-learning algorithm. Such networks can be trained by aligning the training image pairs while simultaneously improving test-time optimization efficacy; tasks which were previously considered two independent training and optimization processes. The proposed meta-registration is hypothesized to maximize the efficiency and effectiveness of the test-time optimization in the "outer" meta-optimization of the networks. For image guidance applications that often are time-critical yet limited in training data, the potentially gained speed and accuracy are compared with classical registration algorithms, registration networks without meta-learning, and single-pair optimization without test-time optimization data. Experiments are presented in this paper using clinical transrectal ultrasound image data from 108 prostate cancer patients. These experiments demonstrate the effectiveness of a meta-registration protocol, which yields significantly improved performance relative to existing learning-based methods. Furthermore, the meta-registration achieves comparable results to classical iterative methods in a fraction of the time, owing to its rapid test-time optimization process.
Counterfactual Image Synthesis for Discovery of Personalized Predictive Image Markers
Aug 03, 2022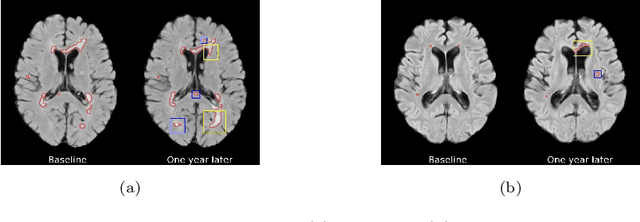

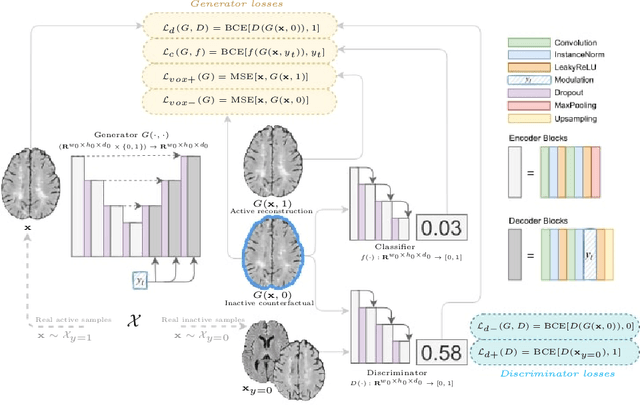

The discovery of patient-specific imaging markers that are predictive of future disease outcomes can help us better understand individual-level heterogeneity of disease evolution. In fact, deep learning models that can provide data-driven personalized markers are much more likely to be adopted in medical practice. In this work, we demonstrate that data-driven biomarker discovery can be achieved through a counterfactual synthesis process. We show how a deep conditional generative model can be used to perturb local imaging features in baseline images that are pertinent to subject-specific future disease evolution and result in a counterfactual image that is expected to have a different future outcome. Candidate biomarkers, therefore, result from examining the set of features that are perturbed in this process. Through several experiments on a large-scale, multi-scanner, multi-center multiple sclerosis (MS) clinical trial magnetic resonance imaging (MRI) dataset of relapsing-remitting (RRMS) patients, we demonstrate that our model produces counterfactuals with changes in imaging features that reflect established clinical markers predictive of future MRI lesional activity at the population level. Additional qualitative results illustrate that our model has the potential to discover novel and subject-specific predictive markers of future activity.
Text-to-Image Generation via Implicit Visual Guidance and Hypernetwork
Aug 17, 2022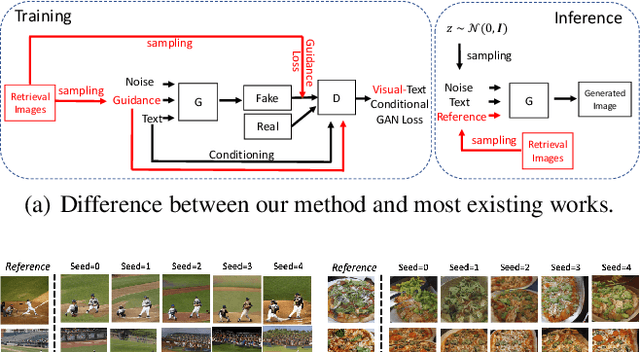
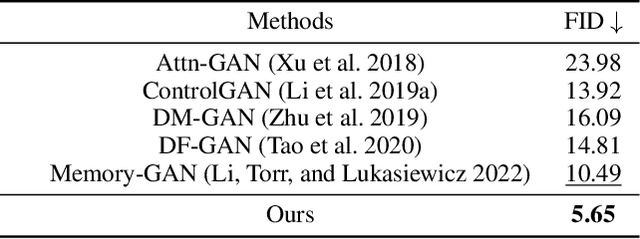
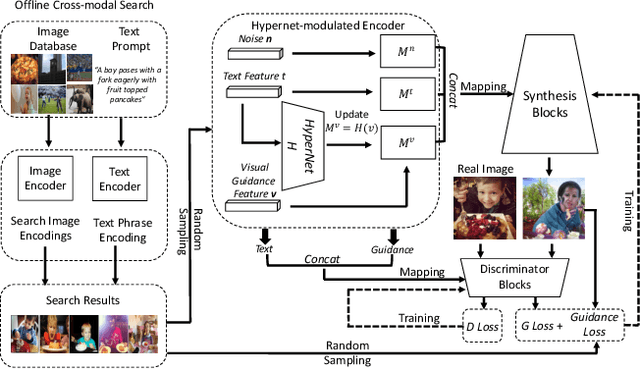
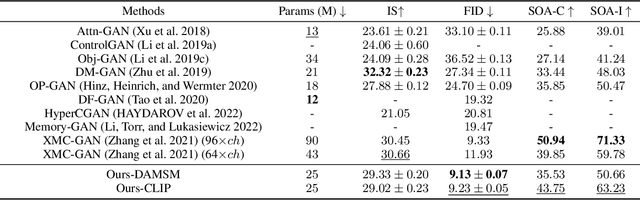
We develop an approach for text-to-image generation that embraces additional retrieval images, driven by a combination of implicit visual guidance loss and generative objectives. Unlike most existing text-to-image generation methods which merely take the text as input, our method dynamically feeds cross-modal search results into a unified training stage, hence improving the quality, controllability and diversity of generation results. We propose a novel hypernetwork modulated visual-text encoding scheme to predict the weight update of the encoding layer, enabling effective transfer from visual information (e.g. layout, content) into the corresponding latent domain. Experimental results show that our model guided with additional retrieval visual data outperforms existing GAN-based models. On COCO dataset, we achieve better FID of $9.13$ with up to $3.5 \times$ fewer generator parameters, compared with the state-of-the-art method.
Geometry-aware Single-image Full-body Human Relighting
Jul 12, 2022
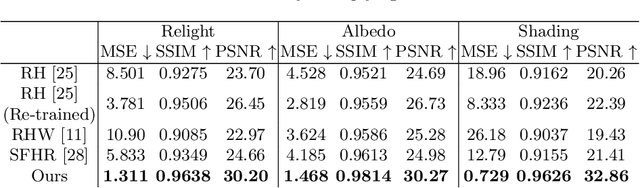
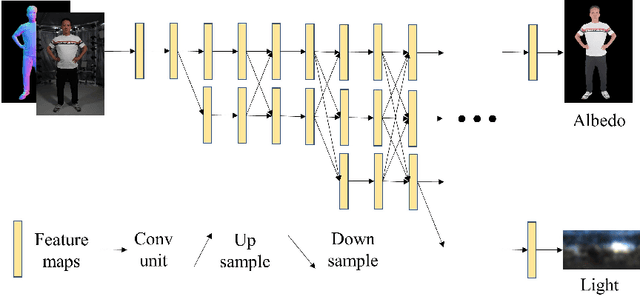
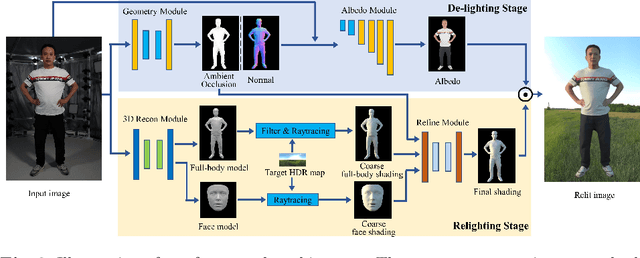
Single-image human relighting aims to relight a target human under new lighting conditions by decomposing the input image into albedo, shape and lighting. Although plausible relighting results can be achieved, previous methods suffer from both the entanglement between albedo and lighting and the lack of hard shadows, which significantly decrease the realism. To tackle these two problems, we propose a geometry-aware single-image human relighting framework that leverages single-image geometry reconstruction for joint deployment of traditional graphics rendering and neural rendering techniques. For the de-lighting, we explore the shortcomings of UNet architecture and propose a modified HRNet, achieving better disentanglement between albedo and lighting. For the relighting, we introduce a ray tracing-based per-pixel lighting representation that explicitly models high-frequency shadows and propose a learning-based shading refinement module to restore realistic shadows (including hard cast shadows) from the ray-traced shading maps. Our framework is able to generate photo-realistic high-frequency shadows such as cast shadows under challenging lighting conditions. Extensive experiments demonstrate that our proposed method outperforms previous methods on both synthetic and real images.
Efficient Bayesian Uncertainty Estimation for nnU-Net
Dec 12, 2022The self-configuring nnU-Net has achieved leading performance in a large range of medical image segmentation challenges. It is widely considered as the model of choice and a strong baseline for medical image segmentation. However, despite its extraordinary performance, nnU-Net does not supply a measure of uncertainty to indicate its possible failure. This can be problematic for large-scale image segmentation applications, where data are heterogeneous and nnU-Net may fail without notice. In this work, we introduce a novel method to estimate nnU-Net uncertainty for medical image segmentation. We propose a highly effective scheme for posterior sampling of weight space for Bayesian uncertainty estimation. Different from previous baseline methods such as Monte Carlo Dropout and mean-field Bayesian Neural Networks, our proposed method does not require a variational architecture and keeps the original nnU-Net architecture intact, thereby preserving its excellent performance and ease of use. Additionally, we boost the segmentation performance over the original nnU-Net via marginalizing multi-modal posterior models. We applied our method on the public ACDC and M&M datasets of cardiac MRI and demonstrated improved uncertainty estimation over a range of baseline methods. The proposed method further strengthens nnU-Net for medical image segmentation in terms of both segmentation accuracy and quality control.
What Decreases Editing Capability? Domain-Specific Hybrid Refinement for Improved GAN Inversion
Jan 28, 2023
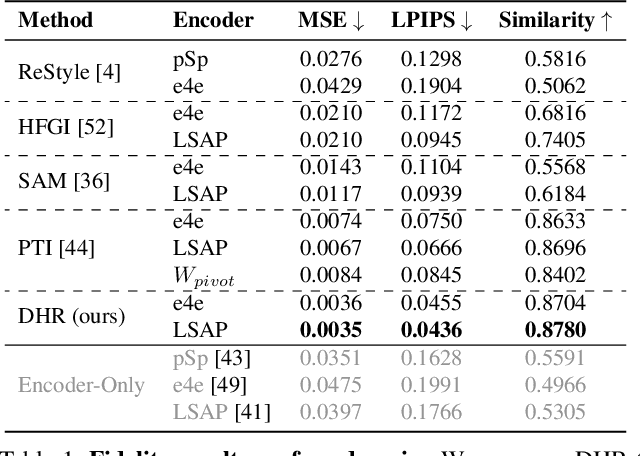
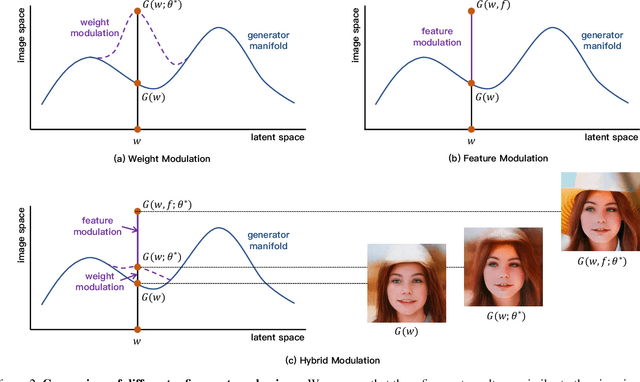
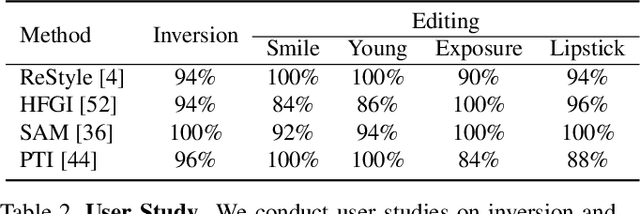
Recently, inversion methods have focused on additional high-rate information in the generator (e.g., weights or intermediate features) to refine inversion and editing results from embedded latent codes. Although these techniques gain reasonable improvement in reconstruction, they decrease editing capability, especially on complex images (e.g., containing occlusions, detailed backgrounds, and artifacts). A vital crux is refining inversion results, avoiding editing capability degradation. To tackle this problem, we introduce Domain-Specific Hybrid Refinement (DHR), which draws on the advantages and disadvantages of two mainstream refinement techniques to maintain editing ability with fidelity improvement. Specifically, we first propose Domain-Specific Segmentation to segment images into two parts: in-domain and out-of-domain parts. The refinement process aims to maintain the editability for in-domain areas and improve two domains' fidelity. We refine these two parts by weight modulation and feature modulation, which we call Hybrid Modulation Refinement. Our proposed method is compatible with all latent code embedding methods. Extension experiments demonstrate that our approach achieves state-of-the-art in real image inversion and editing. Code is available at https://github.com/caopulan/Domain-Specific_Hybrid_Refinement_Inversion.
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
Aug 22, 2022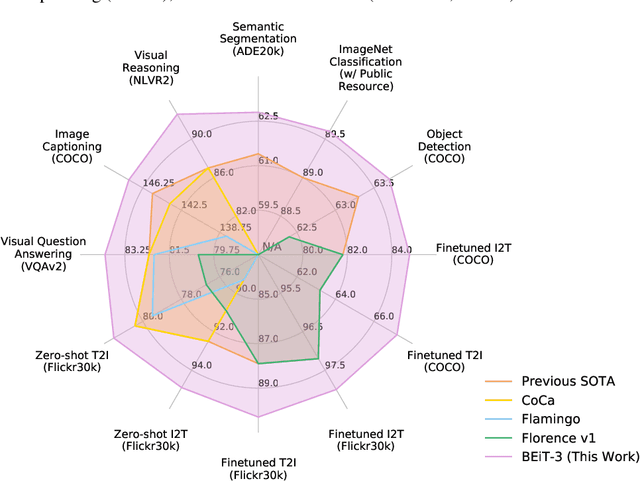
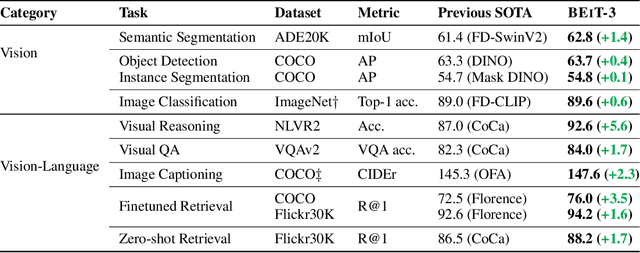
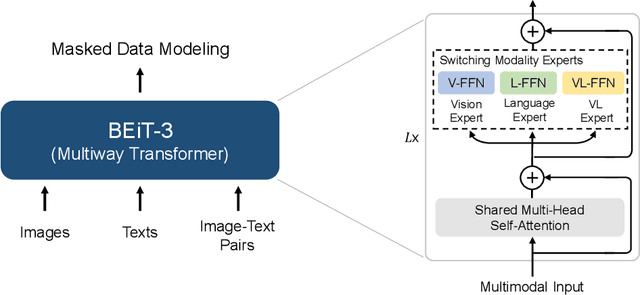

A big convergence of language, vision, and multimodal pretraining is emerging. In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked "language" modeling on images (Imglish), texts (English), and image-text pairs ("parallel sentences") in a unified manner. Experimental results show that BEiT-3 obtains state-of-the-art performance on object detection (COCO), semantic segmentation (ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), image captioning (COCO), and cross-modal retrieval (Flickr30K, COCO).