 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturb-and-Restore: Simulation-driven Structural Augmentation Framework for Imbalance Chromosomal Anomaly Detection
Apr 01, 2026Detecting structural chromosomal abnormalities is crucial for accurate diagnosis and management of genetic disorders. However, collecting sufficient structural abnormality data is extremely challenging and costly in clinical practice, and not all abnormal types can be readily collected. As a result, deep learning approaches face significant performance degradation due to the severe imbalance and scarcity of abnormal chromosome data. To address this challenge, we propose a Perturb-and-Restore (P&R), a simulation-driven structural augmentation framework that effectively alleviates data imbalance in chromosome anomaly detection. The P&R framework comprises two key components: (1) Structure Perturbation and Restoration Simulation, which generates synthetic abnormal chromosomes by perturbing chromosomal banding patterns of normal chromosomes followed by a restoration diffusion network that reconstructs continuous chromosome content and edges, thus eliminating reliance on rare abnormal samples; and (2) Energy-guided Adaptive Sampling, an energy score-based online selection strategy that dynamically prioritizes high-quality synthetic samples by referencing the energy distribution of real samples. To evaluate our method, we construct a comprehensive structural anomaly dataset consisting of over 260,000 chromosome images, including 4,242 abnormal samples spanning 24 categories. Experimental results demonstrate that the P&R framework achieves state-of-the-art (SOTA) performance, surpassing existing methods with an average improvement of 8.92% in sensitivity, 8.89% in precision, and 13.79% in F1-score across all categories.
Colon-Bench: An Agentic Workflow for Scalable Dense Lesion Annotation in Full-Procedure Colonoscopy Videos
Mar 26, 2026Early screening via colonoscopy is critical for colon cancer prevention, yet developing robust AI systems for this domain is hindered by the lack of densely annotated, long-sequence video datasets. Existing datasets predominantly focus on single-class polyp detection and lack the rich spatial, temporal, and linguistic annotations required to evaluate modern Multimodal Large Language Models (MLLMs). To address this critical gap, we introduce Colon-Bench, generated via a novel multi-stage agentic workflow. Our pipeline seamlessly integrates temporal proposals, bounding-box tracking, AI-driven visual confirmation, and human-in-the-loop review to scalably annotate full-procedure videos. The resulting verified benchmark is unprecedented in scope, encompassing 528 videos, 14 distinct lesion categories (including polyps, ulcers, and bleeding), over 300,000 bounding boxes, 213,000 segmentation masks, and 133,000 words of clinical descriptions. We utilize Colon-Bench to rigorously evaluate state-of-the-art MLLMs across lesion classification, Open-Vocabulary Video Object Segmentation (OV-VOS), and video Visual Question Answering (VQA). The MLLM results demonstrate surprisingly high localization performance in medical domains compared to SAM-3. Finally, we analyze common VQA errors from MLLMs to introduce a novel "colon-skill" prompting strategy, improving zero-shot MLLM performance by up to 9.7% across most MLLMs. The dataset and the code are available at https://abdullahamdi.com/colon-bench .
PAST: A multimodal single-cell foundation model for histopathology and spatial transcriptomics in cancer
Jul 08, 2025While pathology foundation models have transformed cancer image analysis, they often lack integration with molecular data at single-cell resolution, limiting their utility for precision oncology. Here, we present PAST, a pan-cancer single-cell foundation model trained on 20 million paired histopathology images and single-cell transcriptomes spanning multiple tumor types and tissue contexts. By jointly encoding cellular morphology and gene expression, PAST learns unified cross-modal representations that capture both spatial and molecular heterogeneity at the cellular level. This approach enables accurate prediction of single-cell gene expression, virtual molecular staining, and multimodal survival analysis directly from routine pathology slides. Across diverse cancers and downstream tasks, PAST consistently exceeds the performance of existing approaches, demonstrating robust generalizability and scalability. Our work establishes a new paradigm for pathology foundation models, providing a versatile tool for high-resolution spatial omics, mechanistic discovery, and precision cancer research.
An Inclusive Foundation Model for Generalizable Cytogenetics in Precision Oncology
May 21, 2025Chromosome analysis is vital for diagnosing genetic disorders and guiding cancer therapy decisions through the identification of somatic clonal aberrations. However, developing an AI model are hindered by the overwhelming complexity and diversity of chromosomal abnormalities, requiring extensive annotation efforts, while automated methods remain task-specific and lack generalizability due to the scarcity of comprehensive datasets spanning diverse resource conditions. Here, we introduce CHROMA, a foundation model for cytogenomics, designed to overcome these challenges by learning generalizable representations of chromosomal abnormalities. Pre-trained on over 84,000 specimens (~4 million chromosomal images) via self-supervised learning, CHROMA outperforms other methods across all types of abnormalities, even when trained on fewer labelled data and more imbalanced datasets. By facilitating comprehensive mapping of instability and clonal leisons across various aberration types, CHROMA offers a scalable and generalizable solution for reliable and automated clinical analysis, reducing the annotation workload for experts and advancing precision oncology through the early detection of rare genomic abnormalities, enabling broad clinical AI applications and making advanced genomic analysis more accessible.
Improving Representation of High-frequency Components for Medical Foundation Models
Jul 26, 2024



Foundation models have recently attracted significant attention for their impressive generalizability across diverse downstream tasks. However, these models are demonstrated to exhibit great limitations in representing high-frequency components and fine-grained details. In many medical imaging tasks, the precise representation of such information is crucial due to the inherently intricate anatomical structures, sub-visual features, and complex boundaries involved. Consequently, the limited representation of prevalent foundation models can result in significant performance degradation or even failure in these tasks. To address these challenges, we propose a novel pretraining strategy, named Frequency-advanced Representation Autoencoder (Frepa). Through high-frequency masking and low-frequency perturbation combined with adversarial learning, Frepa encourages the encoder to effectively represent and preserve high-frequency components in the image embeddings. Additionally, we introduce an innovative histogram-equalized image masking strategy, extending the Masked Autoencoder approach beyond ViT to other architectures such as Swin Transformer and convolutional networks. We develop Frepa across nine medical modalities and validate it on 32 downstream tasks for both 2D images and 3D volume data. Without fine-tuning, Frepa can outperform other self-supervised pretraining methods and, in some cases, even surpasses task-specific trained models. This improvement is particularly significant for tasks involving fine-grained details, such as achieving up to a +15% increase in DSC for retina vessel segmentation and a +7% increase in IoU for lung nodule detection. Further experiments quantitatively reveal that Frepa enables superior high-frequency representations and preservation in the embeddings, underscoring its potential for developing more generalized and universal medical image foundation models.
Deep learning-driven pulmonary arteries and veins segmentation reveals demography-associated pulmonary vasculature anatomy
Apr 11, 2024Pulmonary artery-vein segmentation is crucial for diagnosing pulmonary diseases and surgical planning, and is traditionally achieved by Computed Tomography Pulmonary Angiography (CTPA). However, concerns regarding adverse health effects from contrast agents used in CTPA have constrained its clinical utility. In contrast, identifying arteries and veins using non-contrast CT, a conventional and low-cost clinical examination routine, has long been considered impossible. Here we propose a High-abundant Pulmonary Artery-vein Segmentation (HiPaS) framework achieving accurate artery-vein segmentation on both non-contrast CT and CTPA across various spatial resolutions. HiPaS first performs spatial normalization on raw CT scans via a super-resolution module, and then iteratively achieves segmentation results at different branch levels by utilizing the low-level vessel segmentation as a prior for high-level vessel segmentation. We trained and validated HiPaS on our established multi-centric dataset comprising 1,073 CT volumes with meticulous manual annotation. Both quantitative experiments and clinical evaluation demonstrated the superior performance of HiPaS, achieving a dice score of 91.8% and a sensitivity of 98.0%. Further experiments demonstrated the non-inferiority of HiPaS segmentation on non-contrast CT compared to segmentation on CTPA. Employing HiPaS, we have conducted an anatomical study of pulmonary vasculature on 10,613 participants in China (five sites), discovering a new association between pulmonary vessel abundance and sex and age: vessel abundance is significantly higher in females than in males, and slightly decreases with age, under the controlling of lung volumes (p < 0.0001). HiPaS realizing accurate artery-vein segmentation delineates a promising avenue for clinical diagnosis and understanding pulmonary physiology in a non-invasive manner.
Efficient Bayesian Uncertainty Estimation for nnU-Net
Dec 12, 2022The self-configuring nnU-Net has achieved leading performance in a large range of medical image segmentation challenges. It is widely considered as the model of choice and a strong baseline for medical image segmentation. However, despite its extraordinary performance, nnU-Net does not supply a measure of uncertainty to indicate its possible failure. This can be problematic for large-scale image segmentation applications, where data are heterogeneous and nnU-Net may fail without notice. In this work, we introduce a novel method to estimate nnU-Net uncertainty for medical image segmentation. We propose a highly effective scheme for posterior sampling of weight space for Bayesian uncertainty estimation. Different from previous baseline methods such as Monte Carlo Dropout and mean-field Bayesian Neural Networks, our proposed method does not require a variational architecture and keeps the original nnU-Net architecture intact, thereby preserving its excellent performance and ease of use. Additionally, we boost the segmentation performance over the original nnU-Net via marginalizing multi-modal posterior models. We applied our method on the public ACDC and M&M datasets of cardiac MRI and demonstrated improved uncertainty estimation over a range of baseline methods. The proposed method further strengthens nnU-Net for medical image segmentation in terms of both segmentation accuracy and quality control.
Photoacoustic digital brain: numerical modelling and image reconstruction via deep learning
Sep 19, 2021
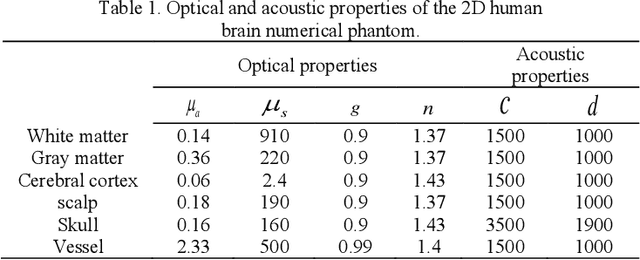
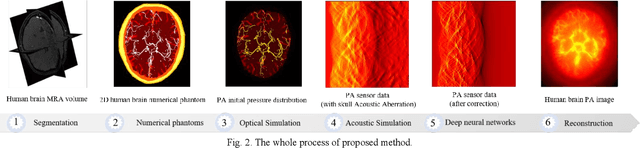
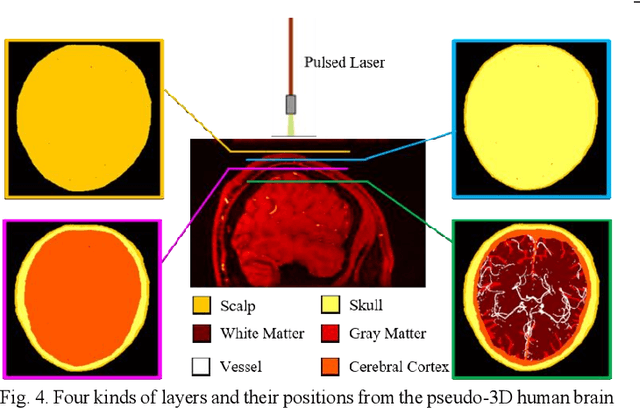
Photoacoustic tomography (PAT) is a newly developed medical imaging modality, which combines the advantages of pure optical imaging and ultrasound imaging, owning both high optical contrast and deep penetration depth. Very recently, PAT is studied in human brain imaging. Nevertheless, while ultrasound waves are passing through the human skull tissues, the strong acoustic attenuation and aberration will happen, which causes photoacoustic signals' distortion. In this work, we use 10 magnetic resonance angiography (MRA) human brain volumes, and manually segment them to obtain the 2D human brain numerical phantoms for PAT. The numerical phantoms contain six kinds of tissues which are scalp, skull, white matter, gray matter, blood vessel and cerebral cortex. For every numerical phantom, optical properties are assigned to every kind of tissues. Then, Monte-Carlo based optical simulation is deployed to obtain the photoacoustic initial pressure. Then, we made two k-wave simulation cases: one takes inhomogeneous medium and uneven sound velocity into consideration, and the other not. Then we use the sensor data of the former one as the input of U-net, and the sensor data of the latter one as the output of U-net to train the network. We randomly choose 7 human brain PA sinograms as the training dataset and 3 human brain PA sinograms as the testing set. The testing result shows that our method could correct the skull acoustic aberration and obtain the blood vessel distribution inside the human brain satisfactorily.
Compressed Sensing for Photoacoustic Computed Tomography Using an Untrained Neural Network
May 29, 2021
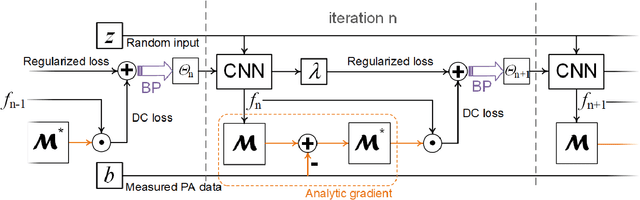
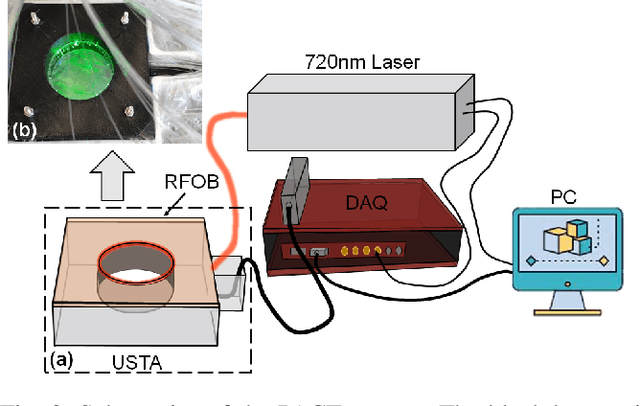
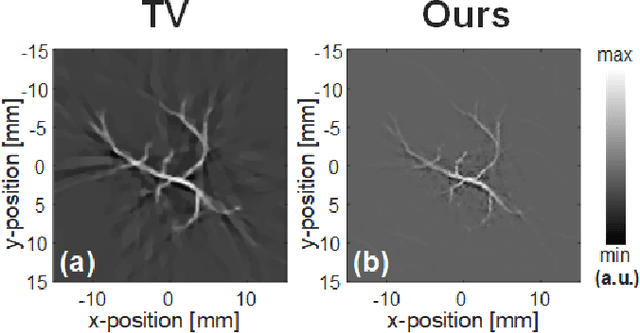
Photoacoustic (PA) computed tomography (PACT) shows great potentials in various preclinical and clinical applications. A great number of measurements are the premise that obtains a high-quality image, which implies a low imaging rate or a high system cost. The artifacts or sidelobes could pollute the image if we decrease the number of measured channels or limit the detected view. In this paper, a novel compressed sensing method for PACT using an untrained neural network is proposed, which decreases half number of the measured channels and recoveries enough details. This method uses a neural network to reconstruct without the requirement for any additional learning based on the deep image prior. The model can reconstruct the image only using a few detections with gradient descent. Our method can cooperate with other existing regularization, and further improve the quality. In addition, we introduce a shape prior to easily converge the model to the image. We verify the feasibility of untrained network based compressed sensing in PA image reconstruction, and compare this method with a conventional method using total variation minimization. The experimental results show that our proposed method outperforms 32.72% (SSIM) with the traditional compressed sensing method in the same regularization. It could dramatically reduce the requirement for the number of transducers, by sparsely sampling the raw PA data, and improve the quality of PA image significantly.
AS-Net: Fast Photoacoustic Reconstruction with Multi-feature Fusion from Sparse Data
Jan 22, 2021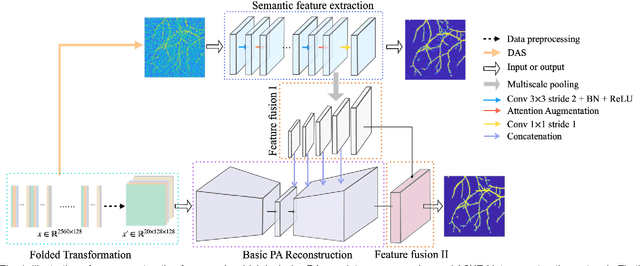
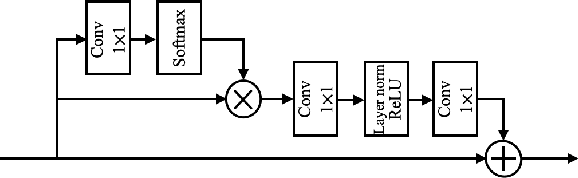

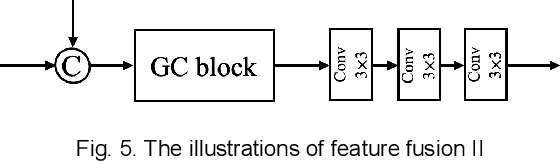
Photoacoustic (PA) imaging is a biomedical imaging modality capable of acquiring high contrast images of optical absorption at depths much greater than traditional optical imaging techniques. However, practical instrumentation and geometry limit the number of available acoustic sensors surrounding the imaging target, which results in sparsity of sensor data. Conventional PA image reconstruction methods give severe artifacts when they are applied directly to these sparse data. In this paper, we first employ a novel signal processing method to make sparse PA raw data more suitable for the neural network, and concurrently speeding up image reconstruction. Then we propose Attention Steered Network (AS-Net) for PA reconstruction with multi-feature fusion. AS-Net is validated on different datasets, including simulated photoacoustic data from fundus vasculature phantoms and real data from in vivo fish and mice imaging experiments. Notably, the method is also able to eliminate some artifacts present in the ground-truth for in vivo data. Results demonstrated that our method provides superior reconstructions at a faster speed.