 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePortraitDirector: A Hierarchical Disentanglement Framework for Controllable and Real-time Facial Reenactment
Apr 21, 2026Existing facial reenactment methods struggle with a trade-off between expressiveness and fine-grained controllability. Holistic facial reenactment models often sacrifice granular control for expressiveness, while methods designed for control may struggle with fidelity and robust disentanglement. Instead of treating facial motion as a monolithic signal, we explore an alternative compositional perspective. In this paper, we introduce PortraitDirector, a novel framework that formulates face reenactment as a hierarchical composition task, achieving high-fidelity and controllable results. We employ a Hierarchical Motion Disentanglement and Composition strategy, deconstructing facial motion into a Spatial Layer for physical movements and a Semantic Layer for emotional content. The Spatial Layer comprises: (i) global head pose, managed via a dedicated representation and injection pathway; (ii) spatially separated local facial expressions, distilled from cropped facial regions and purged of emotional cues via Emotion-Filtering Module leveraging an information bottleneck. The Semantic Layer contains a derived global emotion. The disentangled components are then recomposed into an expressive motion latent. Furthermore, we engineer the framework for real-time performance through a suite of optimizations, including diffusion distillation, causal attention and VAE acceleration. PortraitDirector achieves streaming, high-fidelity, controllable 512 x 512 face reenactment at 20 FPS with a end-to-end 800 ms latency on a single 5090 GPU.
Context-Aware Multimodal Representation Learning for Spatio-Temporally Explicit Environmental Modelling
Nov 18, 2025



Earth observation (EO) foundation models have emerged as an effective approach to derive latent representations of the Earth system from various remote sensing sensors. These models produce embeddings that can be used as analysis-ready datasets, enabling the modelling of ecosystem dynamics without extensive sensor-specific preprocessing. However, existing models typically operate at fixed spatial or temporal scales, limiting their use for ecological analyses that require both fine spatial detail and high temporal fidelity. To overcome these limitations, we propose a representation learning framework that integrates different EO modalities into a unified feature space at high spatio-temporal resolution. We introduce the framework using Sentinel-1 and Sentinel-2 data as representative modalities. Our approach produces a latent space at native 10 m resolution and the temporal frequency of cloud-free Sentinel-2 acquisitions. Each sensor is first modeled independently to capture its sensor-specific characteristics. Their representations are then combined into a shared model. This two-stage design enables modality-specific optimisation and easy extension to new sensors, retaining pretrained encoders while retraining only fusion layers. This enables the model to capture complementary remote sensing data and to preserve coherence across space and time. Qualitative analyses reveal that the learned embeddings exhibit high spatial and semantic consistency across heterogeneous landscapes. Quantitative evaluation in modelling Gross Primary Production reveals that they encode ecologically meaningful patterns and retain sufficient temporal fidelity to support fine-scale analyses. Overall, the proposed framework provides a flexible, analysis-ready representation learning approach for environmental applications requiring diverse spatial and temporal resolutions.
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025



We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Exploring Timeline Control for Facial Motion Generation
May 27, 2025This paper introduces a new control signal for facial motion generation: timeline control. Compared to audio and text signals, timelines provide more fine-grained control, such as generating specific facial motions with precise timing. Users can specify a multi-track timeline of facial actions arranged in temporal intervals, allowing precise control over the timing of each action. To model the timeline control capability, We first annotate the time intervals of facial actions in natural facial motion sequences at a frame-level granularity. This process is facilitated by Toeplitz Inverse Covariance-based Clustering to minimize human labor. Based on the annotations, we propose a diffusion-based generation model capable of generating facial motions that are natural and accurately aligned with input timelines. Our method supports text-guided motion generation by using ChatGPT to convert text into timelines. Experimental results show that our method can annotate facial action intervals with satisfactory accuracy, and produces natural facial motions accurately aligned with timelines.
ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion Model
Mar 27, 2025Real-time interactive video-chat portraits have been increasingly recognized as the future trend, particularly due to the remarkable progress made in text and voice chat technologies. However, existing methods primarily focus on real-time generation of head movements, but struggle to produce synchronized body motions that match these head actions. Additionally, achieving fine-grained control over the speaking style and nuances of facial expressions remains a challenge. To address these limitations, we introduce a novel framework for stylized real-time portrait video generation, enabling expressive and flexible video chat that extends from talking head to upper-body interaction. Our approach consists of the following two stages. The first stage involves efficient hierarchical motion diffusion models, that take both explicit and implicit motion representations into account based on audio inputs, which can generate a diverse range of facial expressions with stylistic control and synchronization between head and body movements. The second stage aims to generate portrait video featuring upper-body movements, including hand gestures. We inject explicit hand control signals into the generator to produce more detailed hand movements, and further perform face refinement to enhance the overall realism and expressiveness of the portrait video. Additionally, our approach supports efficient and continuous generation of upper-body portrait video in maximum 512 * 768 resolution at up to 30fps on 4090 GPU, supporting interactive video-chat in real-time. Experimental results demonstrate the capability of our approach to produce portrait videos with rich expressiveness and natural upper-body movements.
Explainable Earth Surface Forecasting under Extreme Events
Oct 02, 2024



With climate change-related extreme events on the rise, high dimensional Earth observation data presents a unique opportunity for forecasting and understanding impacts on ecosystems. This is, however, impeded by the complexity of processing, visualizing, modeling, and explaining this data. To showcase how this challenge can be met, here we train a convolutional long short-term memory-based architecture on the novel DeepExtremeCubes dataset. DeepExtremeCubes includes around 40,000 long-term Sentinel-2 minicubes (January 2016-October 2022) worldwide, along with labeled extreme events, meteorological data, vegetation land cover, and topography map, sampled from locations affected by extreme climate events and surrounding areas. When predicting future reflectances and vegetation impacts through kernel normalized difference vegetation index, the model achieved an R$^2$ score of 0.9055 in the test set. Explainable artificial intelligence was used to analyze the model's predictions during the October 2020 Central South America compound heatwave and drought event. We chose the same area exactly one year before the event as counterfactual, finding that the average temperature and surface pressure are generally the best predictors under normal conditions. In contrast, minimum anomalies of evaporation and surface latent heat flux take the lead during the event. A change of regime is also observed in the attributions before the event, which might help assess how long the event was brewing before happening. The code to replicate all experiments and figures in this paper is publicly available at https://github.com/DeepExtremes/txyXAI
Earth System Data Cubes: Avenues for advancing Earth system research
Aug 05, 2024Recent advancements in Earth system science have been marked by the exponential increase in the availability of diverse, multivariate datasets characterised by moderate to high spatio-temporal resolutions. Earth System Data Cubes (ESDCs) have emerged as one suitable solution for transforming this flood of data into a simple yet robust data structure. ESDCs achieve this by organising data into an analysis-ready format aligned with a spatio-temporal grid, facilitating user-friendly analysis and diminishing the need for extensive technical data processing knowledge. Despite these significant benefits, the completion of the entire ESDC life cycle remains a challenging task. Obstacles are not only of a technical nature but also relate to domain-specific problems in Earth system research. There exist barriers to realising the full potential of data collections in light of novel cloud-based technologies, particularly in curating data tailored for specific application domains. These include transforming data to conform to a spatio-temporal grid with minimum distortions and managing complexities such as spatio-temporal autocorrelation issues. Addressing these challenges is pivotal for the effective application of Artificial Intelligence (AI) approaches. Furthermore, adhering to open science principles for data dissemination, reproducibility, visualisation, and reuse is crucial for fostering sustainable research. Overcoming these challenges offers a substantial opportunity to advance data-driven Earth system research, unlocking the full potential of an integrated, multidimensional view of Earth system processes. This is particularly true when such research is coupled with innovative research paradigms and technological progress.
DeepExtremeCubes: Integrating Earth system spatio-temporal data for impact assessment of climate extremes
Jun 26, 2024



With climate extremes' rising frequency and intensity, robust analytical tools are crucial to predict their impacts on terrestrial ecosystems. Machine learning techniques show promise but require well-structured, high-quality, and curated analysis-ready datasets. Earth observation datasets comprehensively monitor ecosystem dynamics and responses to climatic extremes, yet the data complexity can challenge the effectiveness of machine learning models. Despite recent progress in deep learning to ecosystem monitoring, there is a need for datasets specifically designed to analyse compound heatwave and drought extreme impact. Here, we introduce the DeepExtremeCubes database, tailored to map around these extremes, focusing on persistent natural vegetation. It comprises over 40,000 spatially sampled small data cubes (i.e. minicubes) globally, with a spatial coverage of 2.5 by 2.5 km. Each minicube includes (i) Sentinel-2 L2A images, (ii) ERA5-Land variables and generated extreme event cube covering 2016 to 2022, and (iii) ancillary land cover and topography maps. The paper aims to (1) streamline data accessibility, structuring, pre-processing, and enhance scientific reproducibility, and (2) facilitate biosphere dynamics forecasting in response to compound extremes.
On-Demand Earth System Data Cubes
Apr 19, 2024



Advancements in Earth system science have seen a surge in diverse datasets. Earth System Data Cubes (ESDCs) have been introduced to efficiently handle this influx of high-dimensional data. ESDCs offer a structured, intuitive framework for data analysis, organising information within spatio-temporal grids. The structured nature of ESDCs unlocks significant opportunities for Artificial Intelligence (AI) applications. By providing well-organised data, ESDCs are ideally suited for a wide range of sophisticated AI-driven tasks. An automated framework for creating AI-focused ESDCs with minimal user input could significantly accelerate the generation of task-specific training data. Here we introduce cubo, an open-source Python tool designed for easy generation of AI-focused ESDCs. Utilising collections in SpatioTemporal Asset Catalogs (STAC) that are stored as Cloud Optimised GeoTIFFs (COGs), cubo efficiently creates ESDCs, requiring only central coordinates, spatial resolution, edge size, and time range.
Geometry-aware Single-image Full-body Human Relighting
Jul 12, 2022
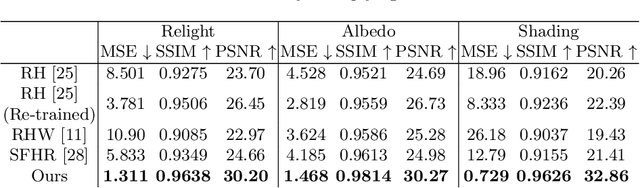
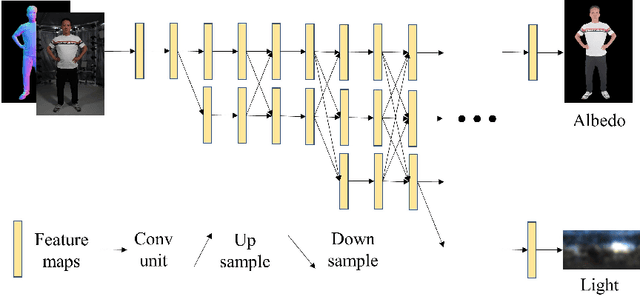
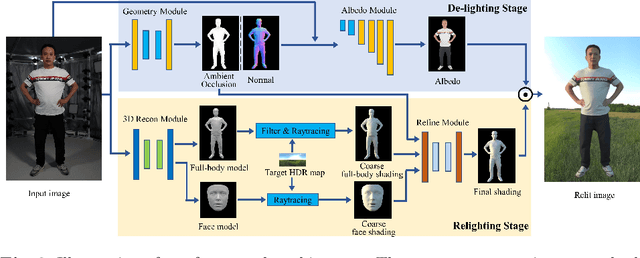
Single-image human relighting aims to relight a target human under new lighting conditions by decomposing the input image into albedo, shape and lighting. Although plausible relighting results can be achieved, previous methods suffer from both the entanglement between albedo and lighting and the lack of hard shadows, which significantly decrease the realism. To tackle these two problems, we propose a geometry-aware single-image human relighting framework that leverages single-image geometry reconstruction for joint deployment of traditional graphics rendering and neural rendering techniques. For the de-lighting, we explore the shortcomings of UNet architecture and propose a modified HRNet, achieving better disentanglement between albedo and lighting. For the relighting, we introduce a ray tracing-based per-pixel lighting representation that explicitly models high-frequency shadows and propose a learning-based shading refinement module to restore realistic shadows (including hard cast shadows) from the ray-traced shading maps. Our framework is able to generate photo-realistic high-frequency shadows such as cast shadows under challenging lighting conditions. Extensive experiments demonstrate that our proposed method outperforms previous methods on both synthetic and real images.