 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Language Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023
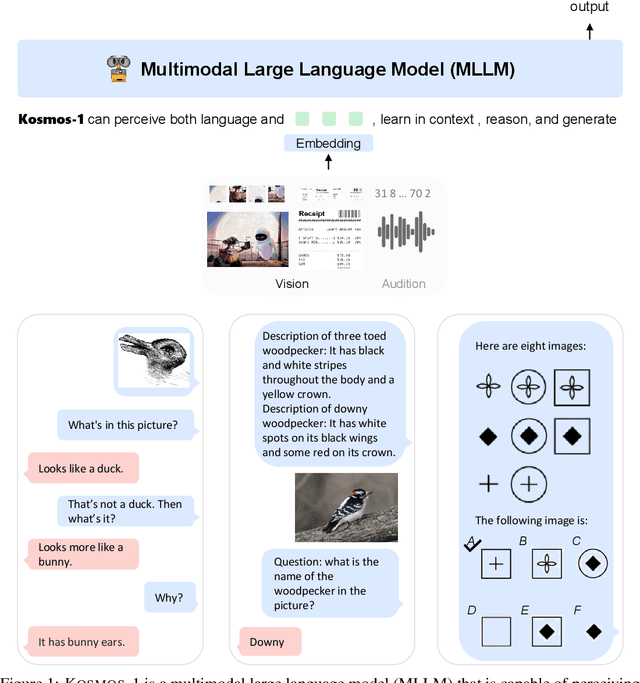
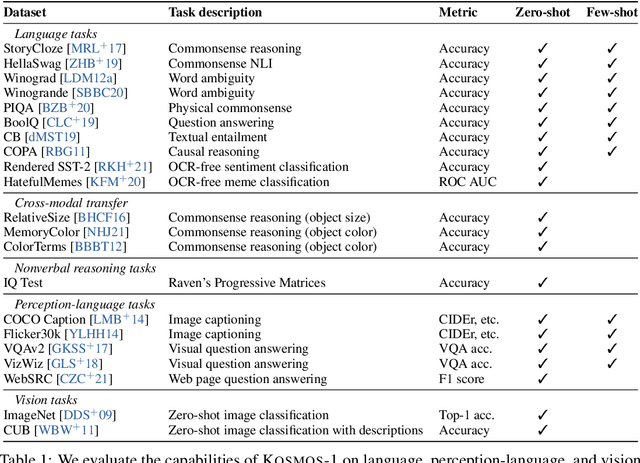

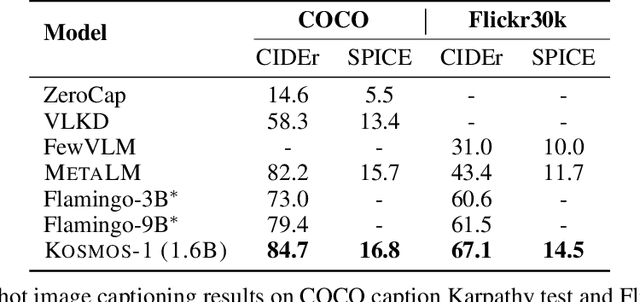
A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
Learning Generative Models with Goal-conditioned Reinforcement Learning
Mar 26, 2023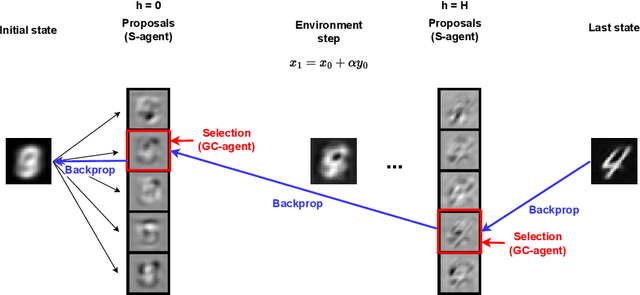
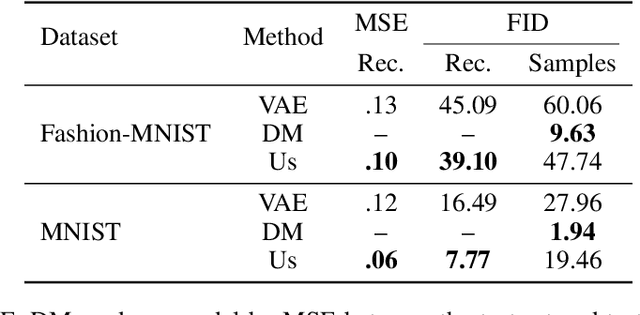


We present a novel, alternative framework for learning generative models with goal-conditioned reinforcement learning. We define two agents, a goal conditioned agent (GC-agent) and a supervised agent (S-agent). Given a user-input initial state, the GC-agent learns to reconstruct the training set. In this context, elements in the training set are the goals. During training, the S-agent learns to imitate the GC-agent while remaining agnostic of the goals. At inference we generate new samples with the S-agent. Following a similar route as in variational auto-encoders, we derive an upper bound on the negative log-likelihood that consists of a reconstruction term and a divergence between the GC-agent policy and the (goal-agnostic) S-agent policy. We empirically demonstrate that our method is able to generate diverse and high quality samples in the task of image synthesis.
A Unified Image Preprocessing Framework For Image Compression
Aug 15, 2022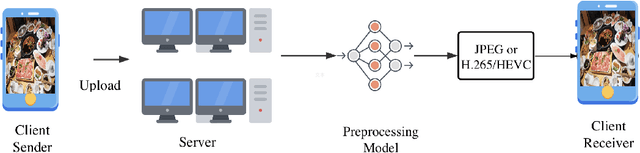
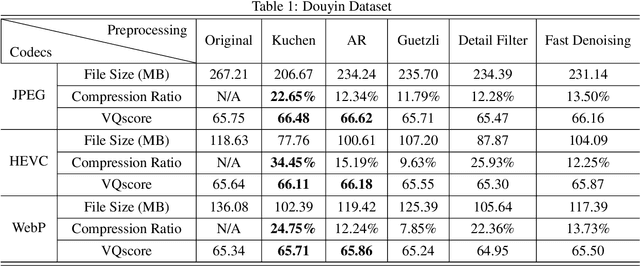
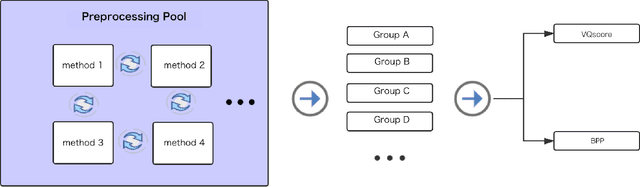
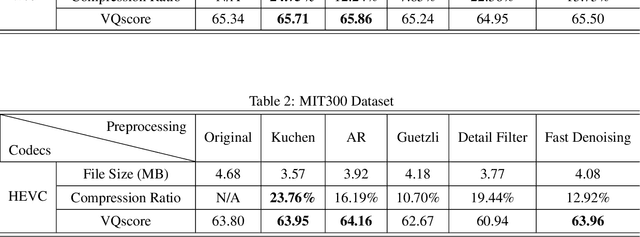
With the development of streaming media technology, increasing communication relies on sound and visual information, which puts a massive burden on online media. Data compression becomes increasingly important to reduce the volume of data transmission and storage. To further improve the efficiency of image compression, researchers utilize various image processing methods to compensate for the limitations of conventional codecs and advanced learning-based compression methods. Instead of modifying the image compression oriented approaches, we propose a unified image compression preprocessing framework, called Kuchen, which aims to further improve the performance of existing codecs. The framework consists of a hybrid data labeling system along with a learning-based backbone to simulate personalized preprocessing. As far as we know, this is the first exploration of setting a unified preprocessing benchmark in image compression tasks. Results demonstrate that the modern codecs optimized by our unified preprocessing framework constantly improve the efficiency of the state-of-the-art compression.
Prior-RadGraphFormer: A Prior-Knowledge-Enhanced Transformer for Generating Radiology Graphs from X-Rays
Mar 27, 2023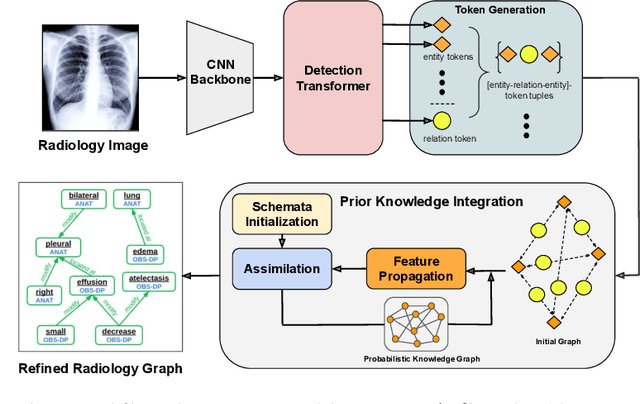
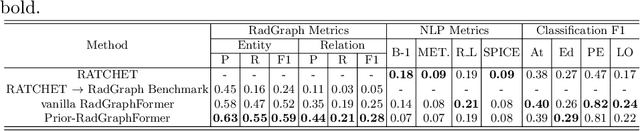
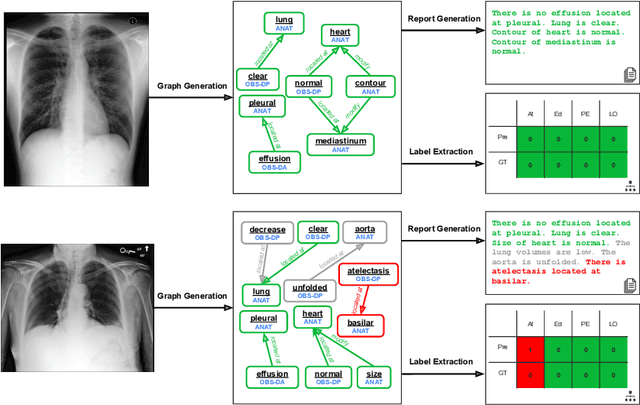
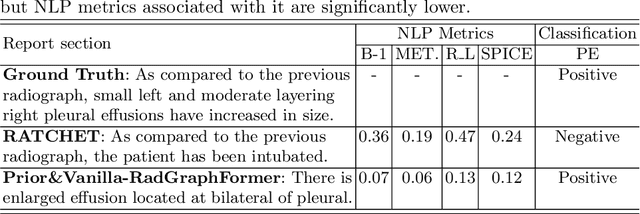
The extraction of structured clinical information from free-text radiology reports in the form of radiology graphs has been demonstrated to be a valuable approach for evaluating the clinical correctness of report-generation methods. However, the direct generation of radiology graphs from chest X-ray (CXR) images has not been attempted. To address this gap, we propose a novel approach called Prior-RadGraphFormer that utilizes a transformer model with prior knowledge in the form of a probabilistic knowledge graph (PKG) to generate radiology graphs directly from CXR images. The PKG models the statistical relationship between radiology entities, including anatomical structures and medical observations. This additional contextual information enhances the accuracy of entity and relation extraction. The generated radiology graphs can be applied to various downstream tasks, such as free-text or structured reports generation and multi-label classification of pathologies. Our approach represents a promising method for generating radiology graphs directly from CXR images, and has significant potential for improving medical image analysis and clinical decision-making.
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 27, 2023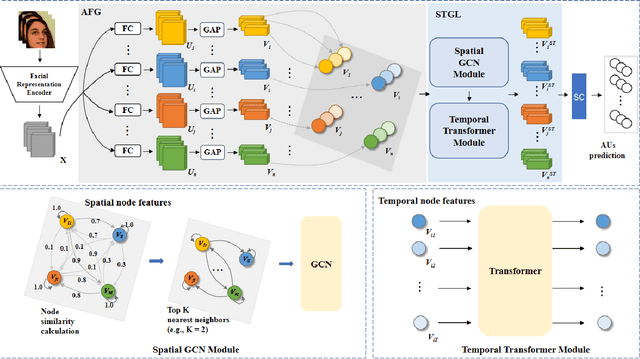

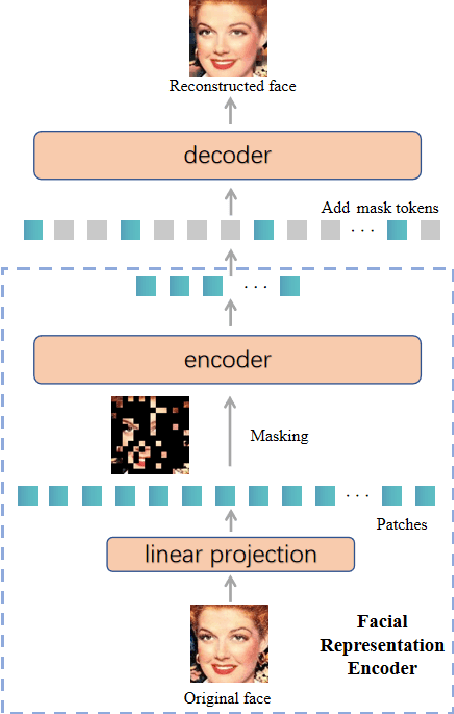

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows our model to generate the best results among all ablated systems. Our model ranks at the 4th place in the AU recognition track at the 5th ABAW Competition.
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Mar 27, 2023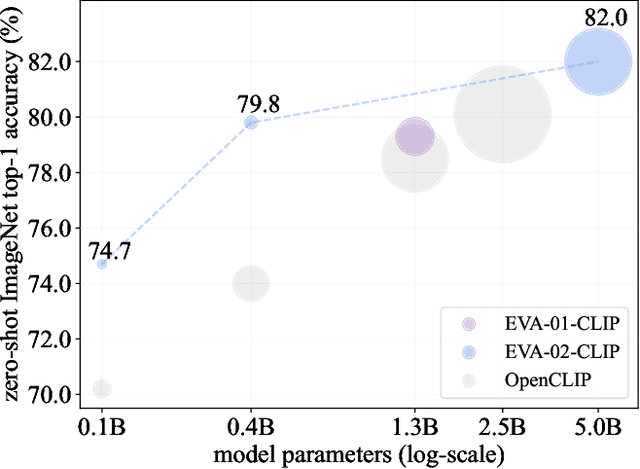
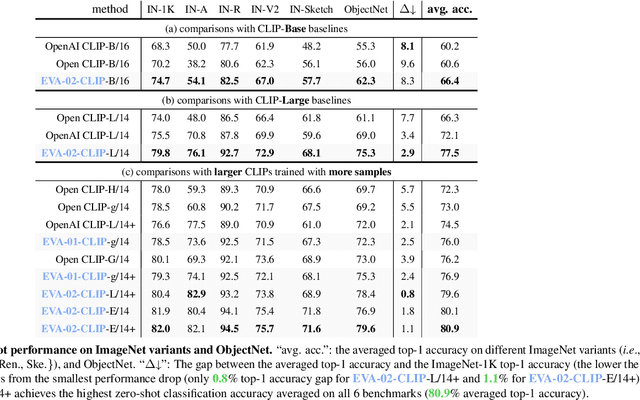
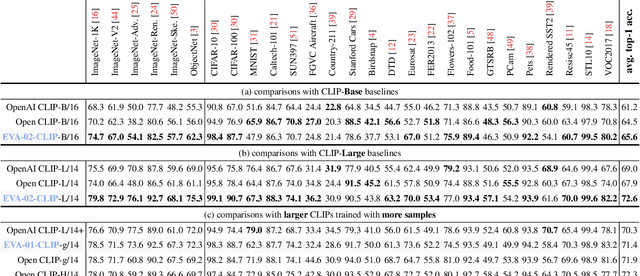
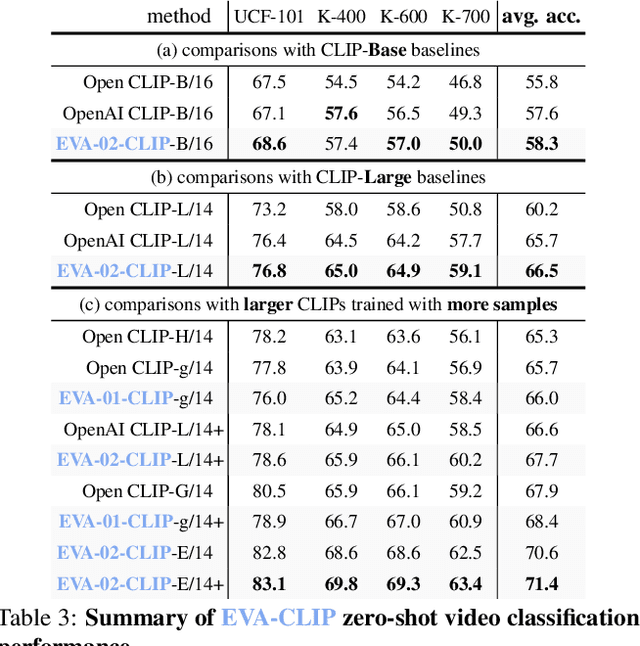
Contrastive language-image pre-training, CLIP for short, has gained increasing attention for its potential in various scenarios. In this paper, we propose EVA-CLIP, a series of models that significantly improve the efficiency and effectiveness of CLIP training. Our approach incorporates new techniques for representation learning, optimization, and augmentation, enabling EVA-CLIP to achieve superior performance compared to previous CLIP models with the same number of parameters but significantly smaller training costs. Notably, our largest 5.0B-parameter EVA-02-CLIP-E/14+ with only 9 billion seen samples achieves 82.0 zero-shot top-1 accuracy on ImageNet-1K val. A smaller EVA-02-CLIP-L/14+ with only 430 million parameters and 6 billion seen samples achieves 80.4 zero-shot top-1 accuracy on ImageNet-1K val. To facilitate open access and open research, we release the complete suite of EVA-CLIP to the community at https://github.com/baaivision/EVA/tree/master/EVA-CLIP.
Manifold Learning by Mixture Models of VAEs for Inverse Problems
Mar 27, 2023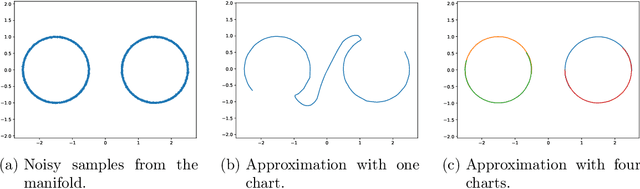
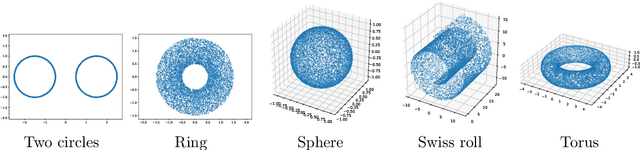
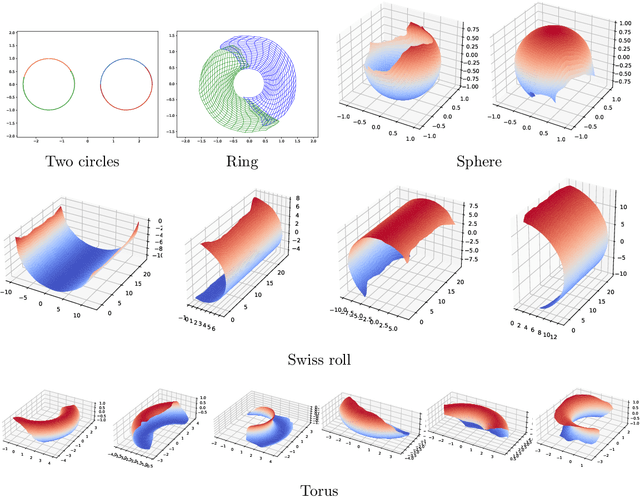
Representing a manifold of very high-dimensional data with generative models has been shown to be computationally efficient in practice. However, this requires that the data manifold admits a global parameterization. In order to represent manifolds of arbitrary topology, we propose to learn a mixture model of variational autoencoders. Here, every encoder-decoder pair represents one chart of a manifold. We propose a loss function for maximum likelihood estimation of the model weights and choose an architecture that provides us the analytical expression of the charts and of their inverses. Once the manifold is learned, we use it for solving inverse problems by minimizing a data fidelity term restricted to the learned manifold. To solve the arising minimization problem we propose a Riemannian gradient descent algorithm on the learned manifold. We demonstrate the performance of our method for low-dimensional toy examples as well as for deblurring and electrical impedance tomography on certain image manifolds.
Intersection over Union with smoothing for bounding box regression
Mar 27, 2023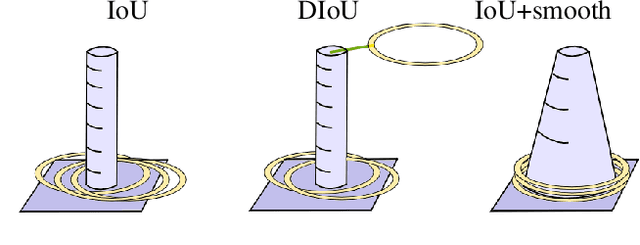



We focus on the construction of a loss function for the bounding box regression. The Intersection over Union (IoU) metric is improved to converge faster, to make the surface of the loss function smooth and continuous over the whole searched space, and to reach a more precise approximation of the labels. The main principle is adding a smoothing part to the original IoU, where the smoothing part is given by a linear space with values that increases from the ground truth bounding box to the border of the input image, and thus covers the whole spatial search space. We show the motivation and formalism behind this loss function and experimentally prove that it outperforms IoU, DIoU, CIoU, and SIoU by a large margin. We experimentally show that the proposed loss function is robust with respect to the noise in the dimension of ground truth bounding boxes. The reference implementation is available at gitlab.com/irafm-ai/smoothing-iou.
Are Data-driven Explanations Robust against Out-of-distribution Data?
Mar 29, 2023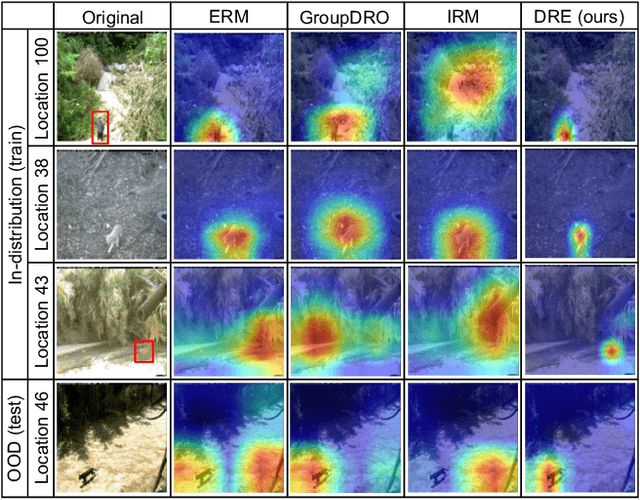
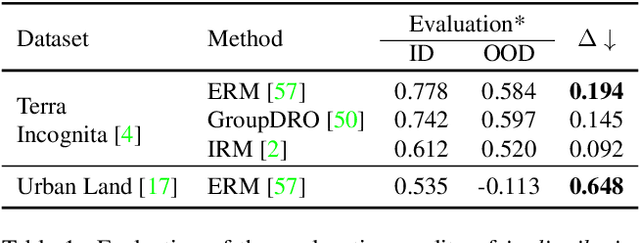
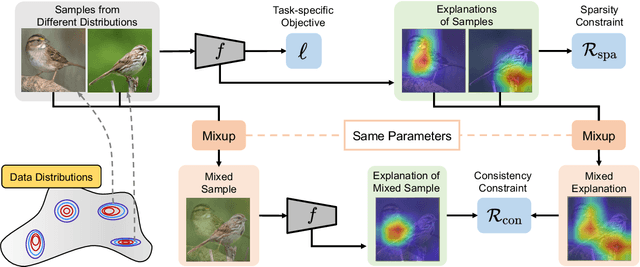

As black-box models increasingly power high-stakes applications, a variety of data-driven explanation methods have been introduced. Meanwhile, machine learning models are constantly challenged by distributional shifts. A question naturally arises: Are data-driven explanations robust against out-of-distribution data? Our empirical results show that even though predict correctly, the model might still yield unreliable explanations under distributional shifts. How to develop robust explanations against out-of-distribution data? To address this problem, we propose an end-to-end model-agnostic learning framework Distributionally Robust Explanations (DRE). The key idea is, inspired by self-supervised learning, to fully utilizes the inter-distribution information to provide supervisory signals for the learning of explanations without human annotation. Can robust explanations benefit the model's generalization capability? We conduct extensive experiments on a wide range of tasks and data types, including classification and regression on image and scientific tabular data. Our results demonstrate that the proposed method significantly improves the model's performance in terms of explanation and prediction robustness against distributional shifts.
Hard Regularization to Prevent Collapse in Online Deep Clustering without Data Augmentation
Mar 29, 2023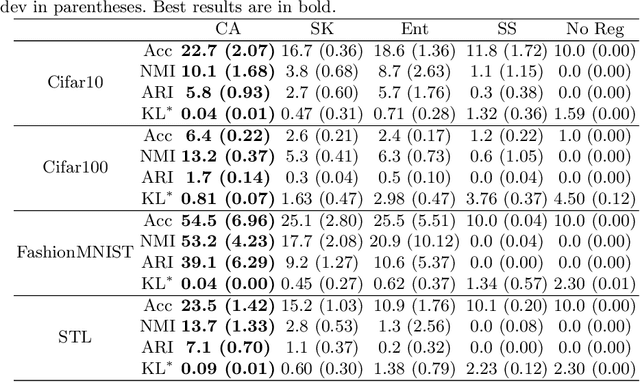
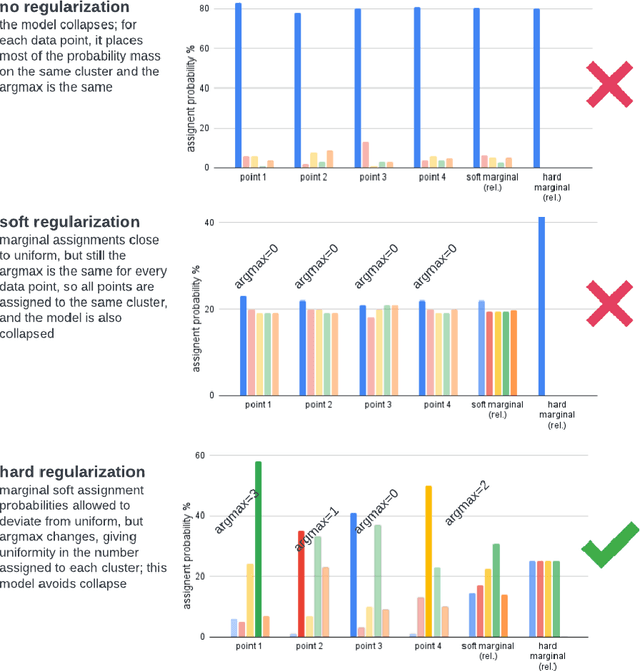
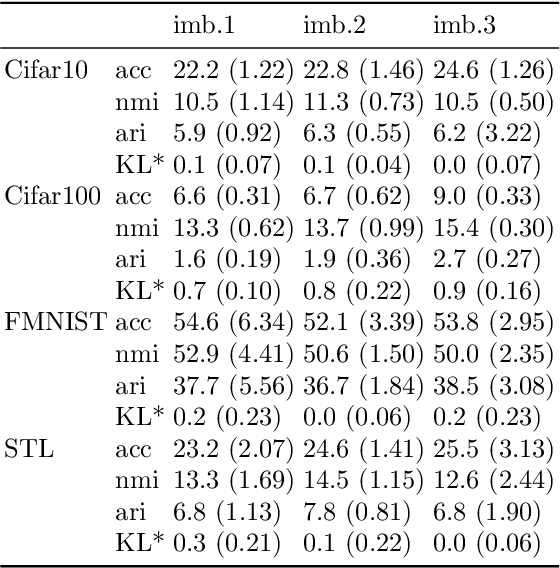
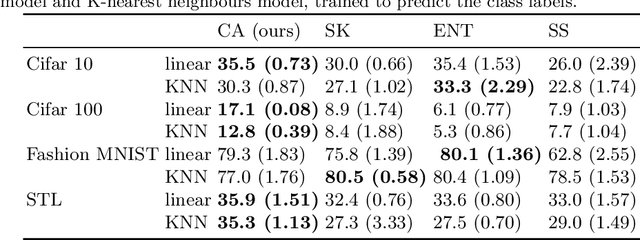
Online deep clustering refers to the joint use of a feature extraction network and a clustering model to assign cluster labels to each new data point or batch as it is processed. While faster and more versatile than offline methods, online clustering can easily reach the collapsed solution where the encoder maps all inputs to the same point and all are put into a single cluster. Successful existing models have employed various techniques to avoid this problem, most of which require data augmentation or which aim to make the average soft assignment across the dataset the same for each cluster. We propose a method that does not require data augmentation, and that, differently from existing methods, regularizes the hard assignments. Using a Bayesian framework, we derive an intuitive optimization objective that can be straightforwardly included in the training of the encoder network. Tested on four image datasets, we show that it consistently avoids collapse more robustly than other methods and that it leads to more accurate clustering. We also conduct further experiments and analyses justifying our choice to regularize the hard cluster assignments.