 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
May 26, 2026Normalization layers in modern large language models (LLMs) consist of a deterministic normalization operation and a learnable scale vector. While the normalization operation has been extensively studied, the scale vector remains poorly understood despite its ubiquitous use. In this work, we present a systematic study of scale vectors in LLMs from the perspectives of expressivity, optimization, and architectural structure. First, we show empirically that although scale vectors constitute only a negligible fraction of model parameters, removing them substantially degrades LLM pre-training. Our theory further shows that, in Pre-Norm architectures, scale vectors do not increase expressivity; instead, they improve optimization through a self-amplifying preconditioning effect on subsequent linear mappings. Second, we investigate the role of weight decay for scale vectors. By distinguishing Input-Norm and Output-Norm layers, we theoretically show that weight decay is beneficial for the former but harmful for the latter, due to their distinct roles in optimization and expressivity. Third, motivated by this understanding, we propose three lightweight and complementary improvements to scale vectors: branch-specific heterogeneity, improved placement around linear mappings, and magnitude-direction reparameterization. Both theory and experiments show that each improvement yields consistent gains. Finally, we combine these improvements into a unified scale-vector strategy and evaluate it through extensive LLM pre-training experiments on dense and mixture-of-experts models ranging from 0.12B to 2B parameters, across multiple optimizers and learning rate schedules, under industrial-scale token budgets. The unified strategy consistently achieves lower terminal loss than well-tuned baselines and exhibits more favorable scaling behavior, while adding negligible parameter and computational overhead.
Mixture-of-Depths Attention
Mar 16, 2026Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025



We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Mar 27, 2023



Contrastive language-image pre-training, CLIP for short, has gained increasing attention for its potential in various scenarios. In this paper, we propose EVA-CLIP, a series of models that significantly improve the efficiency and effectiveness of CLIP training. Our approach incorporates new techniques for representation learning, optimization, and augmentation, enabling EVA-CLIP to achieve superior performance compared to previous CLIP models with the same number of parameters but significantly smaller training costs. Notably, our largest 5.0B-parameter EVA-02-CLIP-E/14+ with only 9 billion seen samples achieves 82.0 zero-shot top-1 accuracy on ImageNet-1K val. A smaller EVA-02-CLIP-L/14+ with only 430 million parameters and 6 billion seen samples achieves 80.4 zero-shot top-1 accuracy on ImageNet-1K val. To facilitate open access and open research, we release the complete suite of EVA-CLIP to the community at https://github.com/baaivision/EVA/tree/master/EVA-CLIP.
EVA-02: A Visual Representation for Neon Genesis
Mar 22, 2023We launch EVA-02, a next-generation Transformer-based visual representation pre-trained to reconstruct strong and robust language-aligned vision features via masked image modeling. With an updated plain Transformer architecture as well as extensive pre-training from an open & accessible giant CLIP vision encoder, EVA-02 demonstrates superior performance compared to prior state-of-the-art approaches across various representative vision tasks, while utilizing significantly fewer parameters and compute budgets. Notably, using exclusively publicly accessible training data, EVA-02 with only 304M parameters achieves a phenomenal 90.0 fine-tuning top-1 accuracy on ImageNet-1K val set. Additionally, our EVA-02-CLIP can reach up to 80.4 zero-shot top-1 on ImageNet-1K, outperforming the previous largest & best open-sourced CLIP with only ~1/6 parameters and ~1/6 image-text training data. We offer four EVA-02 variants in various model sizes, ranging from 6M to 304M parameters, all with impressive performance. To facilitate open access and open research, we release the complete suite of EVA-02 to the community at https://github.com/baaivision/EVA/tree/master/EVA-02.
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
Nov 14, 2022



We launch EVA, a vision-centric foundation model to explore the limits of visual representation at scale using only publicly accessible data. EVA is a vanilla ViT pre-trained to reconstruct the masked out image-text aligned vision features conditioned on visible image patches. Via this pretext task, we can efficiently scale up EVA to one billion parameters, and sets new records on a broad range of representative vision downstream tasks, such as image recognition, video action recognition, object detection, instance segmentation and semantic segmentation without heavy supervised training. Moreover, we observe quantitative changes in scaling EVA result in qualitative changes in transfer learning performance that are not present in other models. For instance, EVA takes a great leap in the challenging large vocabulary instance segmentation task: our model achieves almost the same state-of-the-art performance on LVISv1.0 dataset with over a thousand categories and COCO dataset with only eighty categories. Beyond a pure vision encoder, EVA can also serve as a vision-centric, multi-modal pivot to connect images and text. We find initializing the vision tower of a giant CLIP from EVA can greatly stabilize the training and outperform the training from scratch counterpart with much fewer samples and less compute, providing a new direction for scaling up and accelerating the costly training of multi-modal foundation models. To facilitate future research, we will release all the code and models at \url{https://github.com/baaivision/EVA}.
Temporally Efficient Vision Transformer for Video Instance Segmentation
Apr 18, 2022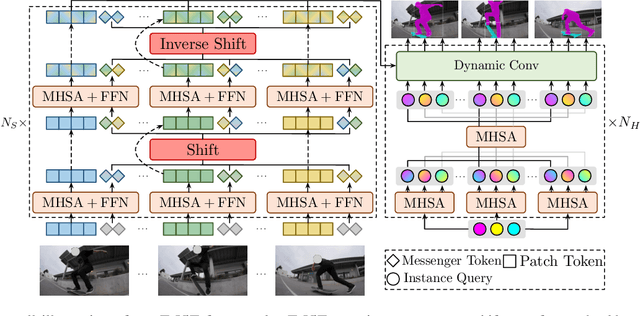
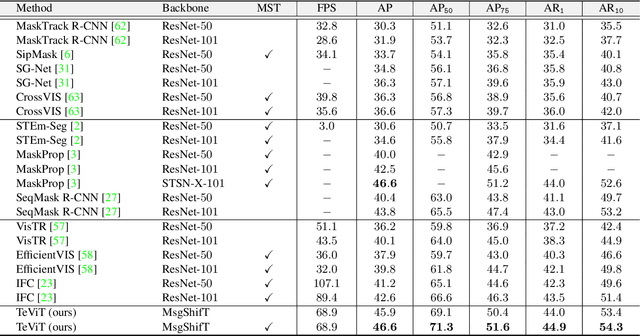
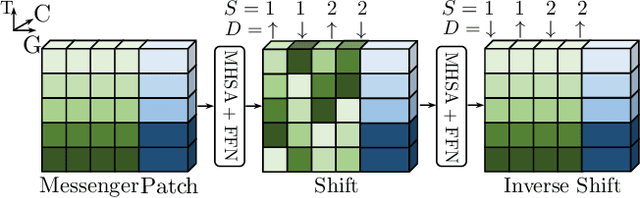
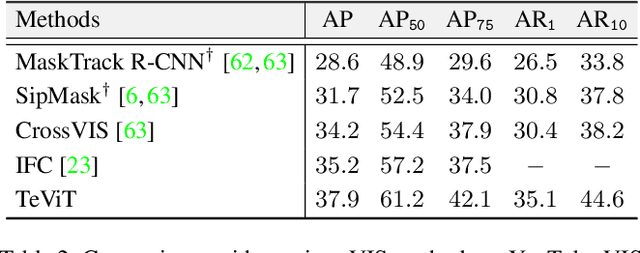
Recently vision transformer has achieved tremendous success on image-level visual recognition tasks. To effectively and efficiently model the crucial temporal information within a video clip, we propose a Temporally Efficient Vision Transformer (TeViT) for video instance segmentation (VIS). Different from previous transformer-based VIS methods, TeViT is nearly convolution-free, which contains a transformer backbone and a query-based video instance segmentation head. In the backbone stage, we propose a nearly parameter-free messenger shift mechanism for early temporal context fusion. In the head stages, we propose a parameter-shared spatiotemporal query interaction mechanism to build the one-to-one correspondence between video instances and queries. Thus, TeViT fully utilizes both framelevel and instance-level temporal context information and obtains strong temporal modeling capacity with negligible extra computational cost. On three widely adopted VIS benchmarks, i.e., YouTube-VIS-2019, YouTube-VIS-2021, and OVIS, TeViT obtains state-of-the-art results and maintains high inference speed, e.g., 46.6 AP with 68.9 FPS on YouTube-VIS-2019. Code is available at https://github.com/hustvl/TeViT.
Unleashing Vanilla Vision Transformer with Masked Image Modeling for Object Detection
Apr 06, 2022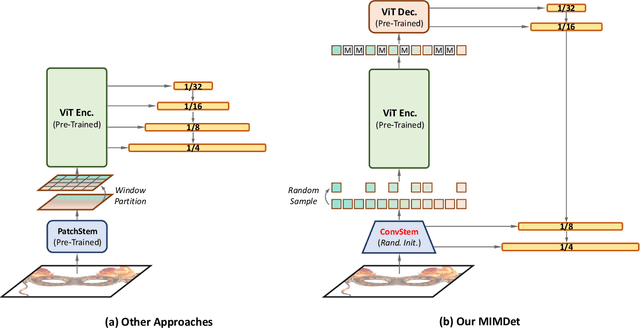
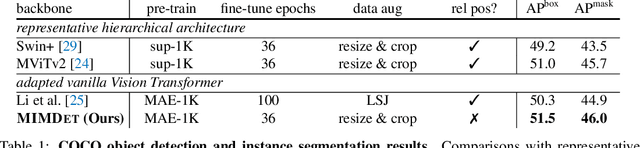
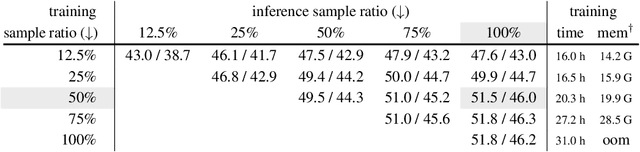

We present an approach to efficiently and effectively adapt a masked image modeling (MIM) pre-trained vanilla Vision Transformer (ViT) for object detection, which is based on our two novel observations: (i) A MIM pre-trained vanilla ViT can work surprisingly well in the challenging object-level recognition scenario even with random sampled partial observations, e.g., only 25% ~ 50% of the input sequence. (ii) In order to construct multi-scale representations for object detection, a random initialized compact convolutional stem supplants the pre-trained large kernel patchify stem, and its intermediate features can naturally serve as the higher resolution inputs of a feature pyramid without upsampling. While the pre-trained ViT is only regarded as the third-stage of our detector's backbone instead of the whole feature extractor, resulting in a ConvNet-ViT hybrid architecture. The proposed detector, named MIMDet, enables a MIM pre-trained vanilla ViT to outperform hierarchical Swin Transformer by 2.3 box AP and 2.5 mask AP on COCO, and achieve even better results compared with other adapted vanilla ViT using a more modest fine-tuning recipe while converging 2.8x faster. Code and pre-trained models are available at \url{https://github.com/hustvl/MIMDet}.
Corrupted Image Modeling for Self-Supervised Visual Pre-Training
Feb 07, 2022



We introduce Corrupted Image Modeling (CIM) for self-supervised visual pre-training. CIM uses an auxiliary generator with a small trainable BEiT to corrupt the input image instead of using artificial mask tokens, where some patches are randomly selected and replaced with plausible alternatives sampled from the BEiT output distribution. Given this corrupted image, an enhancer network learns to either recover all the original image pixels, or predict whether each visual token is replaced by a generator sample or not. The generator and the enhancer are simultaneously trained and synergistically updated. After pre-training, the enhancer can be used as a high-capacity visual encoder for downstream tasks. CIM is a general and flexible visual pre-training framework that is suitable for various network architectures. For the first time, CIM demonstrates that both ViT and CNN can learn rich visual representations using a unified, non-Siamese framework. Experimental results show that our approach achieves compelling results in vision benchmarks, such as ImageNet classification and ADE20K semantic segmentation. For example, 300-epoch CIM pre-trained vanilla ViT-Base/16 and ResNet-50 obtain 83.3 and 80.6 Top-1 fine-tuning accuracy on ImageNet-1K image classification respectively.
What Makes for Hierarchical Vision Transformer?
Jul 05, 2021
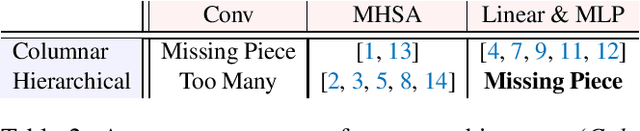


Recent studies show that hierarchical Vision Transformer with interleaved non-overlapped intra window self-attention \& shifted window self-attention is able to achieve state-of-the-art performance in various visual recognition tasks and challenges CNN's dense sliding window paradigm. Most follow-up works try to replace shifted window operation with other kinds of cross window communication while treating self-attention as the de-facto standard for intra window information aggregation. In this short preprint, we question whether self-attention is the only choice for hierarchical Vision Transformer to attain strong performance, and what makes for hierarchical Vision Transformer? We replace self-attention layers in Swin Transformer and Shuffle Transformer with simple linear mapping and keep other components unchanged. The resulting architecture with 25.4M parameters and 4.2G FLOPs achieves 80.5\% Top-1 accuracy, compared to 81.3\% for Swin Transformer with 28.3M parameters and 4.5G FLOPs. We also experiment with other alternatives to self-attention for context aggregation inside each non-overlapped window, which all give similar competitive results under the same architecture. Our study reveals that the \textbf{macro architecture} of Swin model families (i.e., interleaved intra window \& cross window communications), other than specific aggregation layers or specific means of cross window communication, may be more responsible for its strong performance and is the real challenger to CNN's dense sliding window paradigm.