 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA single algorithm for both restless and rested rotting bandits
Apr 23, 2026In many application domains (e.g., recommender systems, intelligent tutoring systems), the rewards associated to the actions tend to decrease over time. This decay is either caused by the actions executed in the past (e.g., a user may get bored when songs of the same genre are recommended over and over) or by an external factor (e.g., content becomes outdated). These two situations can be modeled as specific instances of the rested and restless bandit settings, where arms are rotting (i.e., their value decrease over time). These problems were thought to be significantly different, since Levine et al. (2017) showed that state-of-the-art algorithms for restless bandit perform poorly in the rested rotting setting. In this paper, we introduce a novel algorithm, Rotting Adaptive Window UCB (RAW-UCB), that achieves near-optimal regret in both rotting rested and restless bandit, without any prior knowledge of the setting (rested or restless) and the type of non-stationarity (e.g., piece-wise constant, bounded variation). This is in striking contrast with previous negative results showing that no algorithm can achieve similar results as soon as rewards are allowed to increase. We confirm our theoretical findings on a number of synthetic and dataset-based experiments.
Planning in entropy-regularized Markov decision processes and games
Apr 21, 2026We propose SmoothCruiser, a new planning algorithm for estimating the value function in entropy-regularized Markov decision processes and two-player games, given a generative model of the environment. SmoothCruiser makes use of the smoothness of the Bellman operator promoted by the regularization to achieve problem-independent sample complexity of order O~(1/epsilon^4) for a desired accuracy epsilon, whereas for non-regularized settings there are no known algorithms with guaranteed polynomial sample complexity in the worst case.
* NeurIPS 2019
Gaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
Feb 12, 2026We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the "sim2real" gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Optimal Design for Reward Modeling in RLHF
Oct 23, 2024

Reinforcement Learning from Human Feedback (RLHF) has become a popular approach to align language models (LMs) with human preferences. This method involves collecting a large dataset of human pairwise preferences across various text generations and using it to infer (implicitly or explicitly) a reward model. Numerous methods have been proposed to learn the reward model and align a LM with it. However, the costly process of collecting human preferences has received little attention and could benefit from theoretical insights. This paper addresses this issue and aims to formalize the reward training model in RLHF. We frame the selection of an effective dataset as a simple regret minimization task, using a linear contextual dueling bandit method. Given the potentially large number of arms, this approach is more coherent than the best-arm identification setting. We then propose an offline framework for solving this problem. Under appropriate assumptions - linearity of the reward model in the embedding space, and boundedness of the reward parameter - we derive bounds on the simple regret. Finally, we provide a lower bound that matches our upper bound up to constant and logarithmic terms. To our knowledge, this is the first theoretical contribution in this area to provide an offline approach as well as worst-case guarantees.
Local and adaptive mirror descents in extensive-form games
Sep 01, 2023
We study how to learn $\epsilon$-optimal strategies in zero-sum imperfect information games (IIG) with trajectory feedback. In this setting, players update their policies sequentially based on their observations over a fixed number of episodes, denoted by $T$. Existing procedures suffer from high variance due to the use of importance sampling over sequences of actions (Steinberger et al., 2020; McAleer et al., 2022). To reduce this variance, we consider a fixed sampling approach, where players still update their policies over time, but with observations obtained through a given fixed sampling policy. Our approach is based on an adaptive Online Mirror Descent (OMD) algorithm that applies OMD locally to each information set, using individually decreasing learning rates and a regularized loss. We show that this approach guarantees a convergence rate of $\tilde{\mathcal{O}}(T^{-1/2})$ with high probability and has a near-optimal dependence on the game parameters when applied with the best theoretical choices of learning rates and sampling policies. To achieve these results, we generalize the notion of OMD stabilization, allowing for time-varying regularization with convex increments.
Regularization and Variance-Weighted Regression Achieves Minimax Optimality in Linear MDPs: Theory and Practice
May 22, 2023Mirror descent value iteration (MDVI), an abstraction of Kullback-Leibler (KL) and entropy-regularized reinforcement learning (RL), has served as the basis for recent high-performing practical RL algorithms. However, despite the use of function approximation in practice, the theoretical understanding of MDVI has been limited to tabular Markov decision processes (MDPs). We study MDVI with linear function approximation through its sample complexity required to identify an $\varepsilon$-optimal policy with probability $1-\delta$ under the settings of an infinite-horizon linear MDP, generative model, and G-optimal design. We demonstrate that least-squares regression weighted by the variance of an estimated optimal value function of the next state is crucial to achieving minimax optimality. Based on this observation, we present Variance-Weighted Least-Squares MDVI (VWLS-MDVI), the first theoretical algorithm that achieves nearly minimax optimal sample complexity for infinite-horizon linear MDPs. Furthermore, we propose a practical VWLS algorithm for value-based deep RL, Deep Variance Weighting (DVW). Our experiments demonstrate that DVW improves the performance of popular value-based deep RL algorithms on a set of MinAtar benchmarks.
Learning Generative Models with Goal-conditioned Reinforcement Learning
Mar 26, 2023



We present a novel, alternative framework for learning generative models with goal-conditioned reinforcement learning. We define two agents, a goal conditioned agent (GC-agent) and a supervised agent (S-agent). Given a user-input initial state, the GC-agent learns to reconstruct the training set. In this context, elements in the training set are the goals. During training, the S-agent learns to imitate the GC-agent while remaining agnostic of the goals. At inference we generate new samples with the S-agent. Following a similar route as in variational auto-encoders, we derive an upper bound on the negative log-likelihood that consists of a reconstruction term and a divergence between the GC-agent policy and the (goal-agnostic) S-agent policy. We empirically demonstrate that our method is able to generate diverse and high quality samples in the task of image synthesis.
Adapting to game trees in zero-sum imperfect information games
Dec 23, 2022Imperfect information games (IIG) are games in which each player only partially observes the current game state. We study how to learn $\epsilon$-optimal strategies in a zero-sum IIG through self-play with trajectory feedback. We give a problem-independent lower bound $\mathcal{O}(H(A_{\mathcal{X}}+B_{\mathcal{Y}})/\epsilon^2)$ on the required number of realizations to learn these strategies with high probability, where $H$ is the length of the game, $A_{\mathcal{X}}$ and $B_{\mathcal{Y}}$ are the total number of actions for the two players. We also propose two Follow the Regularize leader (FTRL) algorithms for this setting: Balanced-FTRL which matches this lower bound, but requires the knowledge of the information set structure beforehand to define the regularization; and Adaptive-FTRL which needs $\mathcal{O}(H^2(A_{\mathcal{X}}+B_{\mathcal{Y}})/\epsilon^2)$ plays without this requirement by progressively adapting the regularization to the observations.
KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal
May 27, 2022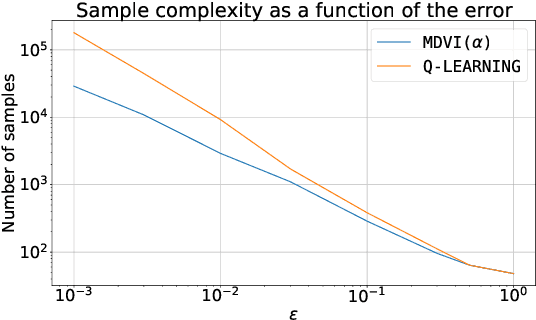

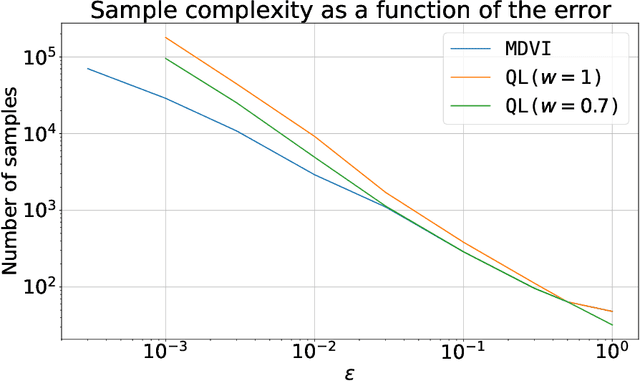
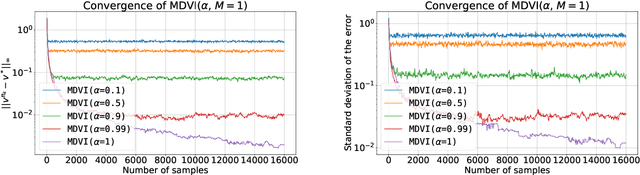
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.