 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Relation Extraction with Cross-Modal Retrieval and Synthesis
May 25, 2023

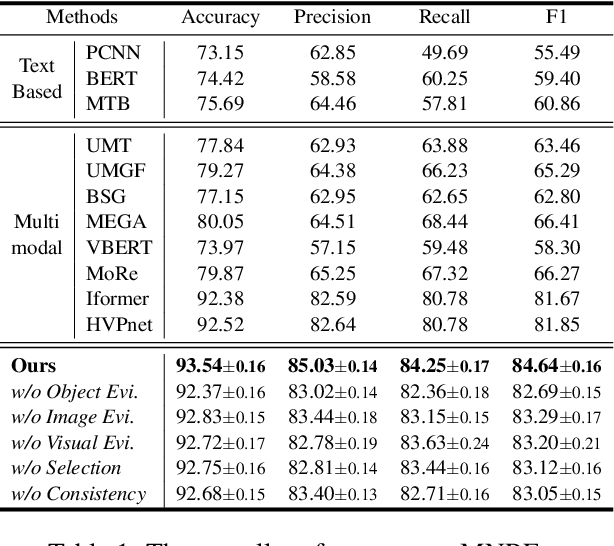
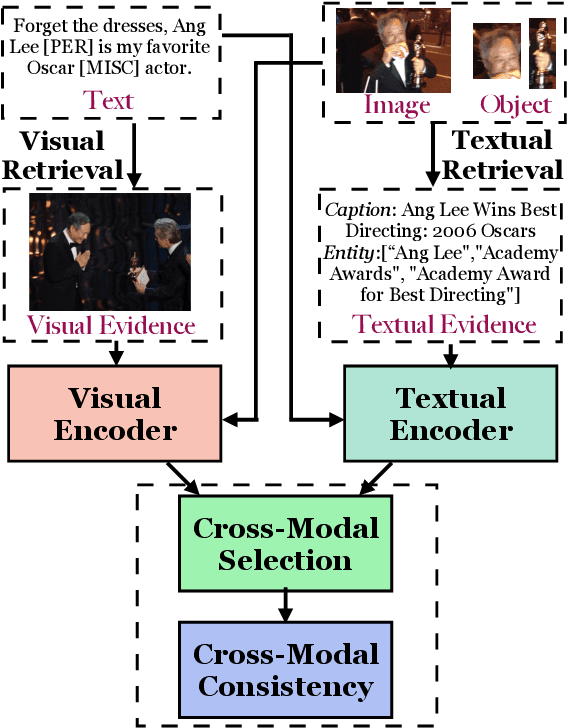
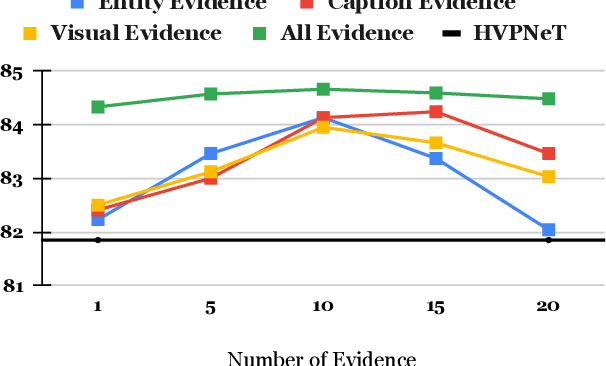
Multimodal relation extraction (MRE) is the task of identifying the semantic relationships between two entities based on the context of the sentence image pair. Existing retrieval-augmented approaches mainly focused on modeling the retrieved textual knowledge, but this may not be able to accurately identify complex relations. To improve the prediction, this research proposes to retrieve textual and visual evidence based on the object, sentence, and whole image. We further develop a novel approach to synthesize the object-level, image-level, and sentence-level information for better reasoning between the same and different modalities. Extensive experiments and analyses show that the proposed method is able to effectively select and compare evidence across modalities and significantly outperforms state-of-the-art models.
Alignment-free HDR Deghosting with Semantics Consistent Transformer
May 29, 2023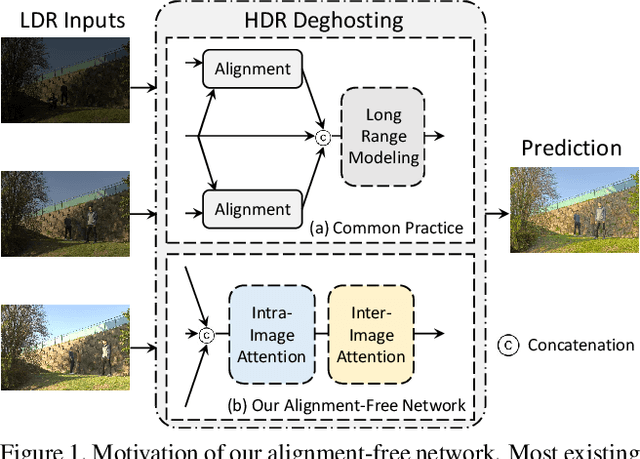

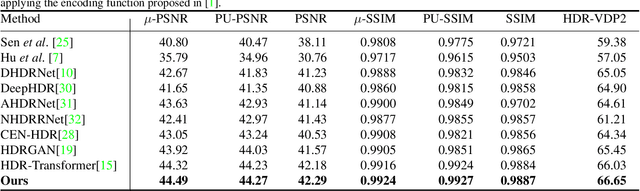
High dynamic range (HDR) imaging aims to retrieve information from multiple low-dynamic range inputs to generate realistic output. The essence is to leverage the contextual information, including both dynamic and static semantics, for better image generation. Existing methods often focus on the spatial misalignment across input frames caused by the foreground and/or camera motion. However, there is no research on jointly leveraging the dynamic and static context in a simultaneous manner. To delve into this problem, we propose a novel alignment-free network with a Semantics Consistent Transformer (SCTNet) with both spatial and channel attention modules in the network. The spatial attention aims to deal with the intra-image correlation to model the dynamic motion, while the channel attention enables the inter-image intertwining to enhance the semantic consistency across frames. Aside from this, we introduce a novel realistic HDR dataset with more variations in foreground objects, environmental factors, and larger motions. Extensive comparisons on both conventional datasets and ours validate the effectiveness of our method, achieving the best trade-off on the performance and the computational cost.
Unsupervised Domain Adaptation for MRI Volume Segmentation and Classification Using Image-to-Image Translation
Feb 16, 2023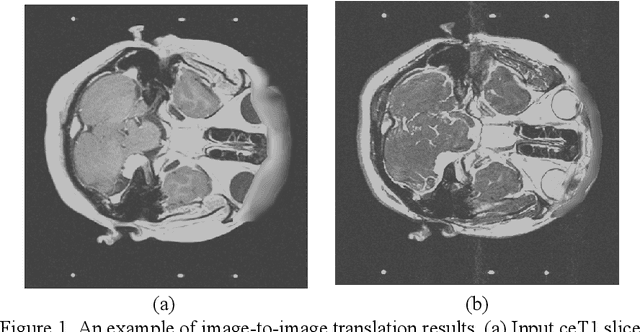
Unsupervised domain adaptation is a type of domain adaptation and exploits labeled data from the source domain and unlabeled data from the target one. In the Cross-Modality Domain Adaptation for Medical Image Segmenta-tion challenge (crossMoDA2022), contrast enhanced T1 MRI volumes for brain are provided as the source domain data, and high-resolution T2 MRI volumes are provided as the target domain data. The crossMoDA2022 challenge contains two tasks, segmentation of vestibular schwannoma (VS) and cochlea, and clas-sification of VS with Koos grade. In this report, we presented our solution for the crossMoDA2022 challenge. We employ an image-to-image translation method for unsupervised domain adaptation and residual U-Net the segmenta-tion task. We use SVM for the classification task. The experimental results show that the mean DSC and ASSD are 0.614 and 2.936 for the segmentation task and MA-MAE is 0.84 for the classification task.
Neural Spectro-polarimetric Fields
Jun 21, 2023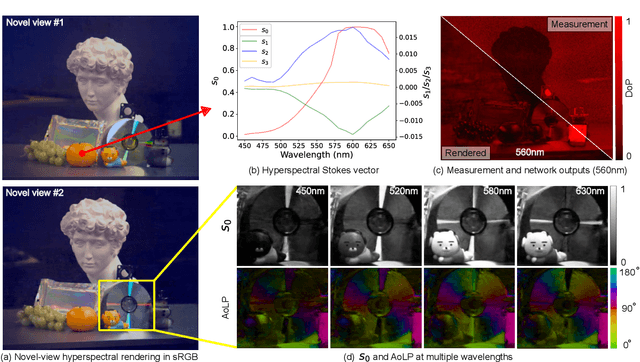
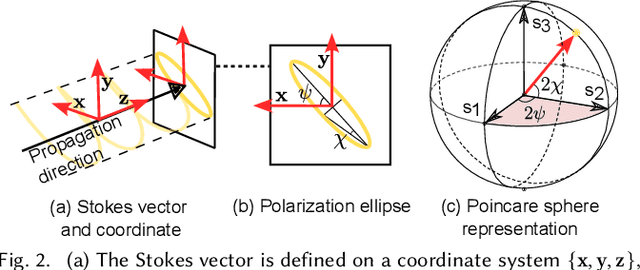
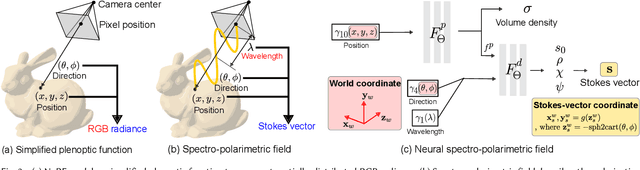

Modeling the spatial radiance distribution of light rays in a scene has been extensively explored for applications, including view synthesis. Spectrum and polarization, the wave properties of light, are often neglected due to their integration into three RGB spectral bands and their non-perceptibility to human vision. Despite this, these properties encompass substantial material and geometric information about a scene. In this work, we propose to model spectro-polarimetric fields, the spatial Stokes-vector distribution of any light ray at an arbitrary wavelength. We present Neural Spectro-polarimetric Fields (NeSpoF), a neural representation that models the physically-valid Stokes vector at given continuous variables of position, direction, and wavelength. NeSpoF manages inherently noisy raw measurements, showcases memory efficiency, and preserves physically vital signals, factors that are crucial for representing the high-dimensional signal of a spectro-polarimetric field. To validate NeSpoF, we introduce the first multi-view hyperspectral-polarimetric image dataset, comprised of both synthetic and real-world scenes. These were captured using our compact hyperspectral-polarimetric imaging system, which has been calibrated for robustness against system imperfections. We demonstrate the capabilities of NeSpoF on diverse scenes.
DIAS: A Comprehensive Benchmark for DSA-sequence Intracranial Artery Segmentation
Jun 21, 2023Automatic segmentation of the intracranial artery (IA) in digital subtraction angiography (DSA) sequence is an essential step in diagnosing IA-related diseases and guiding neuro-interventional surgery. However, the lack of publicly available datasets has impeded research in this area. In this paper, we release DIAS, an IA segmentation dataset, consisting of 120 DSA sequences from intracranial interventional therapy. In addition to pixel-wise annotations, this dataset provides two types of scribble annotations for weakly supervised IA segmentation research. We present a comprehensive benchmark for evaluating the performance of this challenging dataset by utilizing fully-, weakly-, and semi-supervised learning approaches. Specifically, we propose a method that incorporates a dimensionality reduction module into a 2D/3D model to achieve vessel segmentation in DSA sequences. For weakly-supervised learning, we propose a scribble learning-based image segmentation framework, SSCR, which comprises scribble supervision and consistency regularization. Furthermore, we introduce a random patch-based self-training framework that utilizes unlabeled DSA sequences to improve segmentation performance. Our extensive experiments on the DIAS dataset demonstrate the effectiveness of these methods as potential baselines for future research and clinical applications.
Segment Anything Model for Medical Image Analysis: an Experimental Study
Apr 20, 2023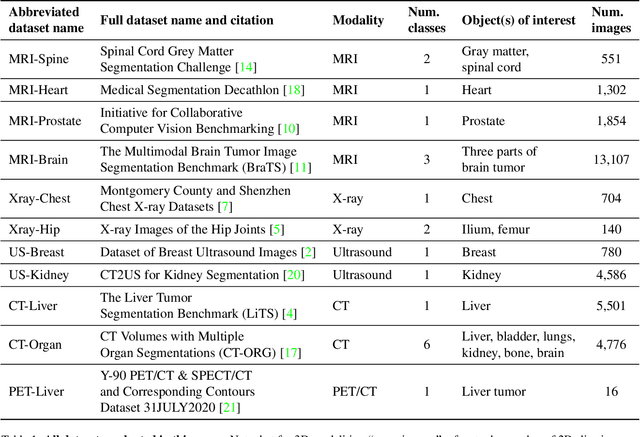
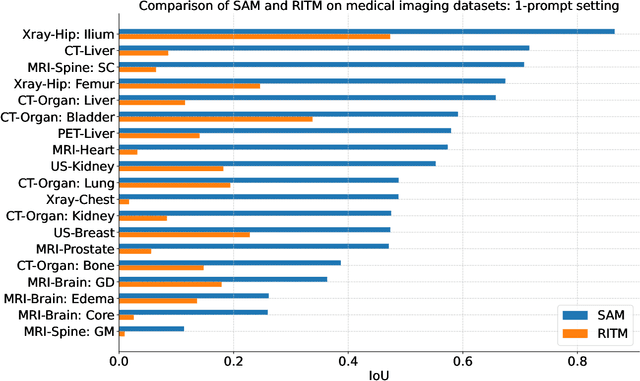
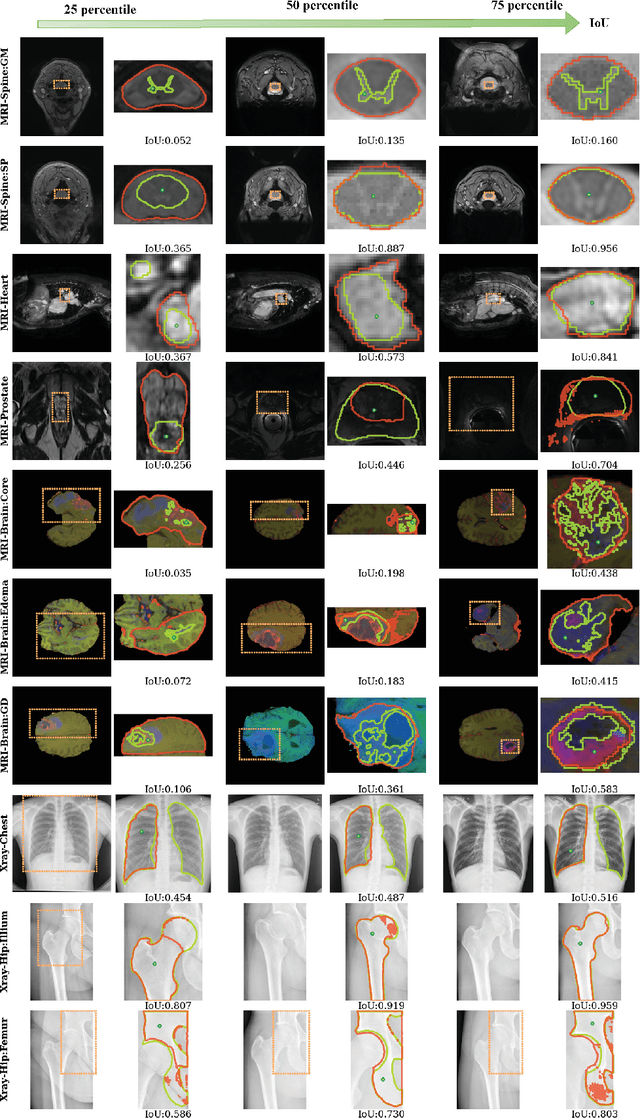
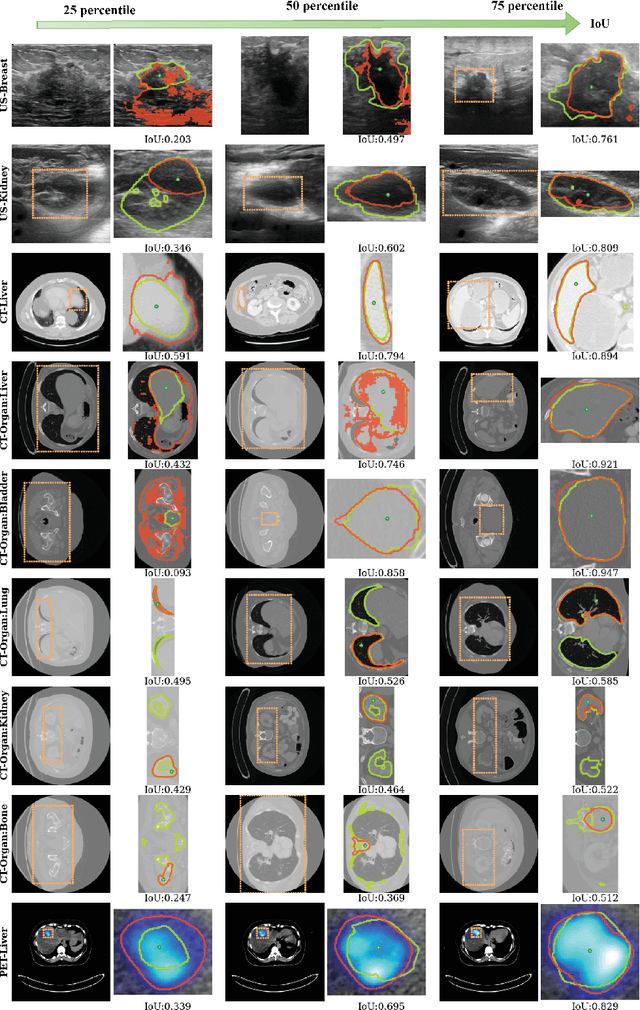
Training segmentation models for medical images continues to be challenging due to the limited availability and acquisition expense of data annotations. Segment Anything Model (SAM) is a foundation model trained on over 1 billion annotations, predominantly for natural images, that is intended to be able to segment the user-defined object of interest in an interactive manner. Despite its impressive performance on natural images, it is unclear how the model is affected when shifting to medical image domains. Here, we perform an extensive evaluation of SAM's ability to segment medical images on a collection of 11 medical imaging datasets from various modalities and anatomies. In our experiments, we generated point prompts using a standard method that simulates interactive segmentation. Experimental results show that SAM's performance based on single prompts highly varies depending on the task and the dataset, i.e., from 0.1135 for a spine MRI dataset to 0.8650 for a hip x-ray dataset, evaluated by IoU. Performance appears to be high for tasks including well-circumscribed objects with unambiguous prompts and poorer in many other scenarios such as segmentation of tumors. When multiple prompts are provided, performance improves only slightly overall, but more so for datasets where the object is not contiguous. An additional comparison to RITM showed a much better performance of SAM for one prompt but a similar performance of the two methods for a larger number of prompts. We conclude that SAM shows impressive performance for some datasets given the zero-shot learning setup but poor to moderate performance for multiple other datasets. While SAM as a model and as a learning paradigm might be impactful in the medical imaging domain, extensive research is needed to identify the proper ways of adapting it in this domain.
Training Diffusion Models with Reinforcement Learning
May 23, 2023
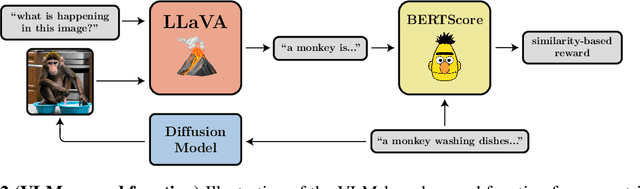


Diffusion models are a class of flexible generative models trained with an approximation to the log-likelihood objective. However, most use cases of diffusion models are not concerned with likelihoods, but instead with downstream objectives such as human-perceived image quality or drug effectiveness. In this paper, we investigate reinforcement learning methods for directly optimizing diffusion models for such objectives. We describe how posing denoising as a multi-step decision-making problem enables a class of policy gradient algorithms, which we refer to as denoising diffusion policy optimization (DDPO), that are more effective than alternative reward-weighted likelihood approaches. Empirically, DDPO is able to adapt text-to-image diffusion models to objectives that are difficult to express via prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality. Finally, we show that DDPO can improve prompt-image alignment using feedback from a vision-language model without the need for additional data collection or human annotation.
Adaptive CSI Feedback for Deep Learning-Enabled Image Transmission
Feb 27, 2023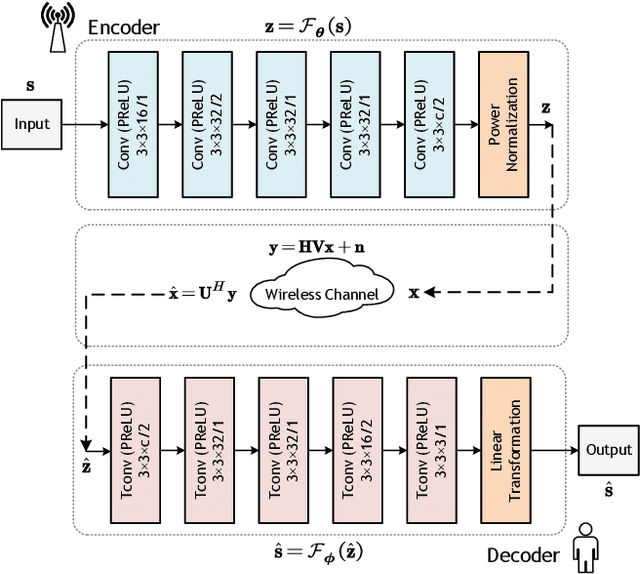
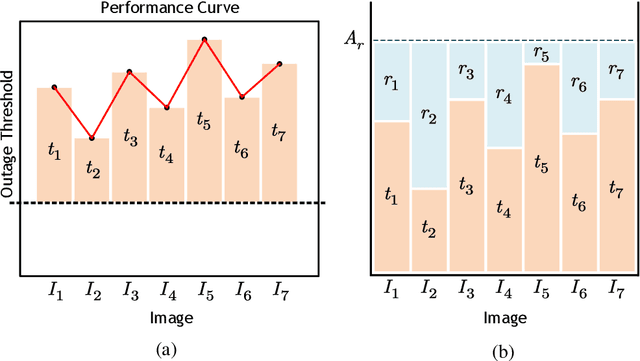
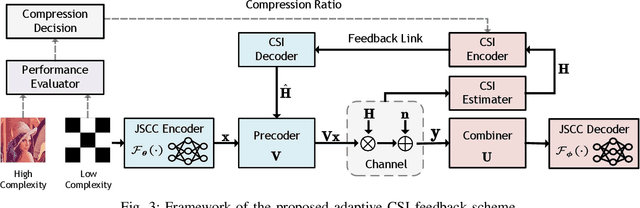
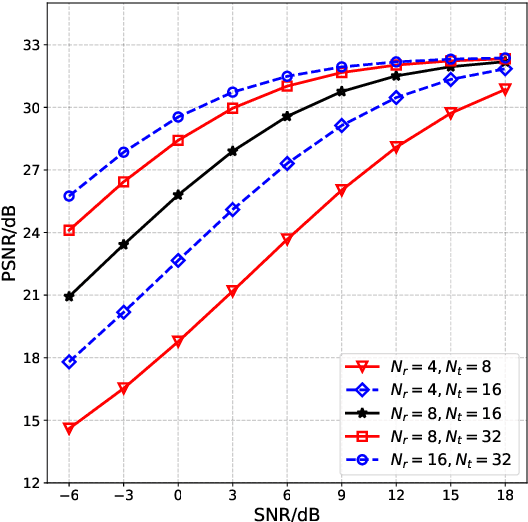
Recently, deep learning-enabled joint-source channel coding (JSCC) has received increasing attention due to its great success in image transmission. However, most existing JSCC studies only focus on single-input single-output (SISO) channels. In this paper, we first propose a JSCC system for wireless image transmission over multiple-input multiple-output (MIMO) channels. As the complexity of an image determines its reconstruction difficulty, the JSCC achieves quite different reconstruction performances on different images. Moreover, we observe that the images with higher reconstruction qualities are generally more robust to the noise, and can be allocated with less communication resources than the images with lower reconstruction qualities. Based on this observation, we propose an adaptive channel state information (CSI) feedback scheme for precoding, which improves the effectiveness by adjusting the feedback overhead. In particular, we develop a performance evaluator to predict the reconstruction quality of each image, so that the proposed scheme can adaptively decrease the CSI feedback overhead for the transmitted images with high predicted reconstruction qualities in the JSCC system. We perform experiments to demonstrate that the proposed scheme can significantly improve the image transmission performance with much-reduced feedback overhead.
RoCOCO: Robust Benchmark MS-COCO to Stress-test Robustness of Image-Text Matching Models
Apr 21, 2023



Recently, large-scale vision-language pre-training models and visual semantic embedding methods have significantly improved image-text matching (ITM) accuracy on MS COCO 5K test set. However, it is unclear how robust these state-of-the-art (SOTA) models are when using them in the wild. In this paper, we propose a novel evaluation benchmark to stress-test the robustness of ITM models. To this end, we add various fooling images and captions to a retrieval pool. Specifically, we change images by inserting unrelated images, and change captions by substituting a noun, which can change the meaning of a sentence. We discover that just adding these newly created images and captions to the test set can degrade performances (i.e., Recall@1) of a wide range of SOTA models (e.g., 81.9% $\rightarrow$ 64.5% in BLIP, 66.1% $\rightarrow$ 37.5% in VSE$\infty$). We expect that our findings can provide insights for improving the robustness of the vision-language models and devising more diverse stress-test methods in cross-modal retrieval task. Source code and dataset will be available at https://github.com/pseulki/rococo.
Learning INR for Event-guided Rolling Shutter Frame Correction, Deblur, and Interpolation
May 24, 2023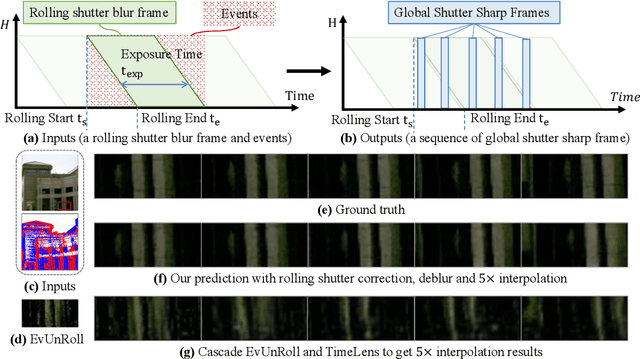
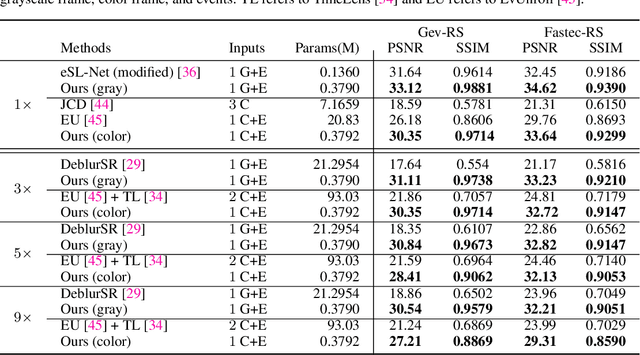
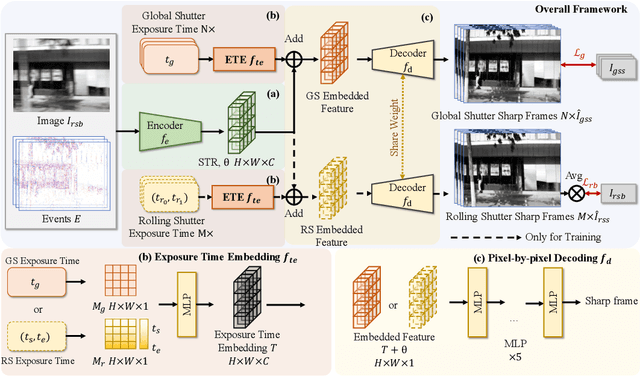
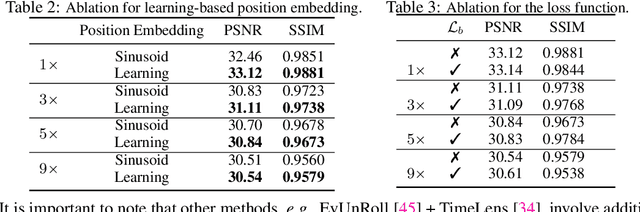
Images captured by rolling shutter (RS) cameras under fast camera motion often contain obvious image distortions and blur, which can be modeled as a row-wise combination of a sequence of global shutter (GS) frames within the exposure time naturally, recovering high-frame-rate GS sharp frames from an RS blur image needs to simultaneously consider RS correction, deblur, and frame interpolation Taking this task is nontrivial, and to our knowledge, no feasible solutions exist by far. A naive way is to decompose the complete process into separate tasks and simply cascade existing methods; however, this results in cumulative errors and noticeable artifacts. Event cameras enjoy many advantages, e.g., high temporal resolution, making them potential for our problem. To this end, we make the first attempt to recover high-frame-rate sharp GS frames from an RS blur image and paired event data. Our key idea is to learn an implicit neural representation (INR) to directly map the position and time coordinates to RGB values to address the interlocking degradations in the image restoration process. Specifically, we introduce spatial-temporal implicit encoding (STE) to convert an RS blur image and events into a spatial-temporal representation (STR). To query a specific sharp frame (GS or RS), we embed the exposure time into STR and decode the embedded features to recover a sharp frame. Moreover, we propose an RS blur image-guided integral loss to better train the network. Our method is relatively lightweight as it contains only 0.379M parameters and demonstrates high efficiency as the STE is called only once for any number of interpolation frames. Extensive experiments show that our method significantly outperforms prior methods addressing only one or two of the tasks.