 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXd Violence
Papers and Code
Learning to Tell Apart: Weakly Supervised Video Anomaly Detection via Disentangled Semantic Alignment
Nov 13, 2025Recent advancements in weakly-supervised video anomaly detection have achieved remarkable performance by applying the multiple instance learning paradigm based on multimodal foundation models such as CLIP to highlight anomalous instances and classify categories. However, their objectives may tend to detect the most salient response segments, while neglecting to mine diverse normal patterns separated from anomalies, and are prone to category confusion due to similar appearance, leading to unsatisfactory fine-grained classification results. Therefore, we propose a novel Disentangled Semantic Alignment Network (DSANet) to explicitly separate abnormal and normal features from coarse-grained and fine-grained aspects, enhancing the distinguishability. Specifically, at the coarse-grained level, we introduce a self-guided normality modeling branch that reconstructs input video features under the guidance of learned normal prototypes, encouraging the model to exploit normality cues inherent in the video, thereby improving the temporal separation of normal patterns and anomalous events. At the fine-grained level, we present a decoupled contrastive semantic alignment mechanism, which first temporally decomposes each video into event-centric and background-centric components using frame-level anomaly scores and then applies visual-language contrastive learning to enhance class-discriminative representations. Comprehensive experiments on two standard benchmarks, namely XD-Violence and UCF-Crime, demonstrate that DSANet outperforms existing state-of-the-art methods.
MoniTor: Exploiting Large Language Models with Instruction for Online Video Anomaly Detection
Oct 24, 2025Video Anomaly Detection (VAD) aims to locate unusual activities or behaviors within videos. Recently, offline VAD has garnered substantial research attention, which has been invigorated by the progress in large language models (LLMs) and vision-language models (VLMs), offering the potential for a more nuanced understanding of anomalies. However, online VAD has seldom received attention due to real-time constraints and computational intensity. In this paper, we introduce a novel Memory-based online scoring queue scheme for Training-free VAD (MoniTor), to address the inherent complexities in online VAD. Specifically, MoniTor applies a streaming input to VLMs, leveraging the capabilities of pre-trained large-scale models. To capture temporal dependencies more effectively, we incorporate a novel prediction mechanism inspired by Long Short-Term Memory (LSTM) networks. This ensures the model can effectively model past states and leverage previous predictions to identify anomalous behaviors. Thereby, it better understands the current frame. Moreover, we design a scoring queue and an anomaly prior to dynamically store recent scores and cover all anomalies in the monitoring scenario, providing guidance for LLMs to distinguish between normal and abnormal behaviors over time. We evaluate MoniTor on two large datasets (i.e., UCF-Crime and XD-Violence) containing various surveillance and real-world scenarios. The results demonstrate that MoniTor outperforms state-of-the-art methods and is competitive with weakly supervised methods without training. Code is available at https://github.com/YsTvT/MoniTor.
Unlocking Vision-Language Models for Video Anomaly Detection via Fine-Grained Prompting
Oct 02, 2025
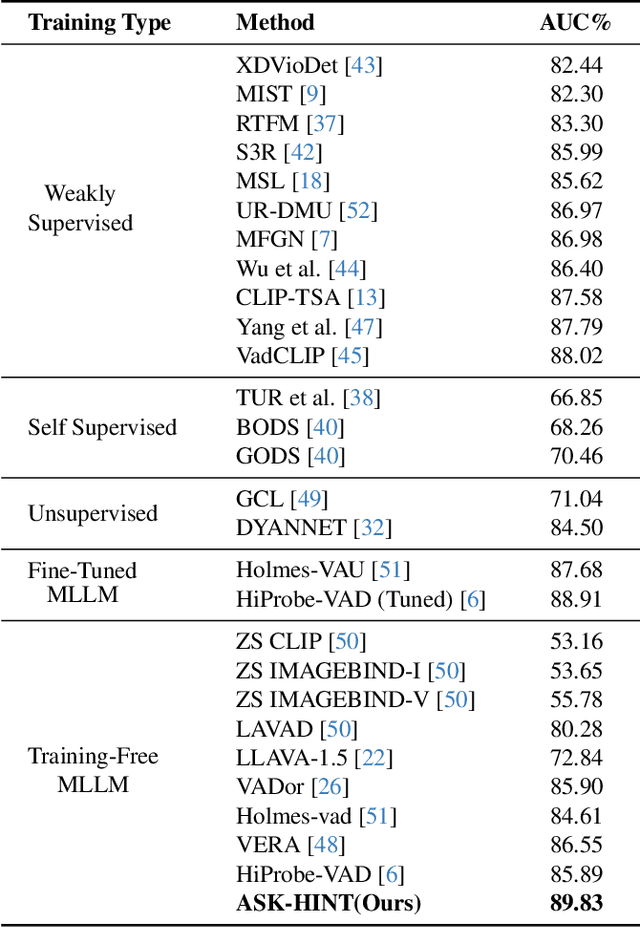
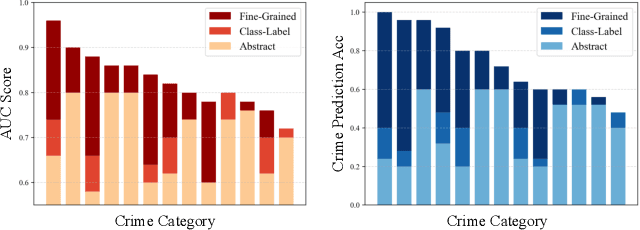
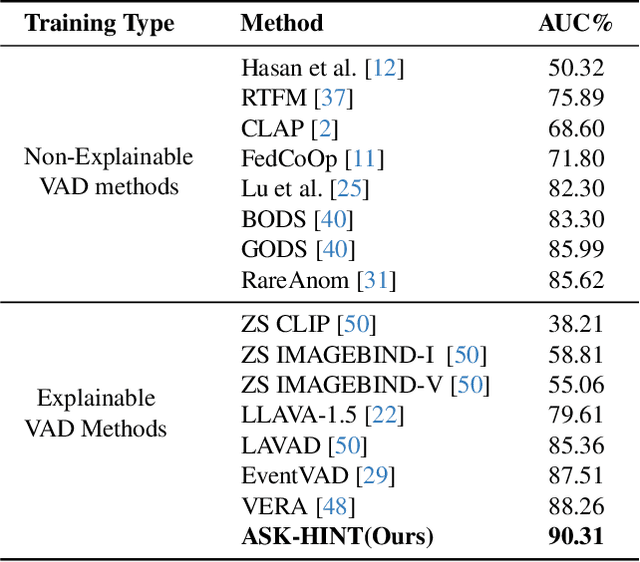
Prompting has emerged as a practical way to adapt frozen vision-language models (VLMs) for video anomaly detection (VAD). Yet, existing prompts are often overly abstract, overlooking the fine-grained human-object interactions or action semantics that define complex anomalies in surveillance videos. We propose ASK-Hint, a structured prompting framework that leverages action-centric knowledge to elicit more accurate and interpretable reasoning from frozen VLMs. Our approach organizes prompts into semantically coherent groups (e.g. violence, property crimes, public safety) and formulates fine-grained guiding questions that align model predictions with discriminative visual cues. Extensive experiments on UCF-Crime and XD-Violence show that ASK-Hint consistently improves AUC over prior baselines, achieving state-of-the-art performance compared to both fine-tuned and training-free methods. Beyond accuracy, our framework provides interpretable reasoning traces towards anomaly and demonstrates strong generalization across datasets and VLM backbones. These results highlight the critical role of prompt granularity and establish ASK-Hint as a new training-free and generalizable solution for explainable video anomaly detection.
Aligning Effective Tokens with Video Anomaly in Large Language Models
Aug 08, 2025Understanding abnormal events in videos is a vital and challenging task that has garnered significant attention in a wide range of applications. Although current video understanding Multi-modal Large Language Models (MLLMs) are capable of analyzing general videos, they often struggle to handle anomalies due to the spatial and temporal sparsity of abnormal events, where the redundant information always leads to suboptimal outcomes. To address these challenges, exploiting the representation and generalization capabilities of Vison Language Models (VLMs) and Large Language Models (LLMs), we propose VA-GPT, a novel MLLM designed for summarizing and localizing abnormal events in various videos. Our approach efficiently aligns effective tokens between visual encoders and LLMs through two key proposed modules: Spatial Effective Token Selection (SETS) and Temporal Effective Token Generation (TETG). These modules enable our model to effectively capture and analyze both spatial and temporal information associated with abnormal events, resulting in more accurate responses and interactions. Furthermore, we construct an instruction-following dataset specifically for fine-tuning video-anomaly-aware MLLMs, and introduce a cross-domain evaluation benchmark based on XD-Violence dataset. Our proposed method outperforms existing state-of-the-art methods on various benchmarks.
Mixture of Experts Guided by Gaussian Splatters Matters: A new Approach to Weakly-Supervised Video Anomaly Detection
Aug 08, 2025Video Anomaly Detection (VAD) is a challenging task due to the variability of anomalous events and the limited availability of labeled data. Under the Weakly-Supervised VAD (WSVAD) paradigm, only video-level labels are provided during training, while predictions are made at the frame level. Although state-of-the-art models perform well on simple anomalies (e.g., explosions), they struggle with complex real-world events (e.g., shoplifting). This difficulty stems from two key issues: (1) the inability of current models to address the diversity of anomaly types, as they process all categories with a shared model, overlooking category-specific features; and (2) the weak supervision signal, which lacks precise temporal information, limiting the ability to capture nuanced anomalous patterns blended with normal events. To address these challenges, we propose Gaussian Splatting-guided Mixture of Experts (GS-MoE), a novel framework that employs a set of expert models, each specialized in capturing specific anomaly types. These experts are guided by a temporal Gaussian splatting loss, enabling the model to leverage temporal consistency and enhance weak supervision. The Gaussian splatting approach encourages a more precise and comprehensive representation of anomalies by focusing on temporal segments most likely to contain abnormal events. The predictions from these specialized experts are integrated through a mixture-of-experts mechanism to model complex relationships across diverse anomaly patterns. Our approach achieves state-of-the-art performance, with a 91.58% AUC on the UCF-Crime dataset, and demonstrates superior results on XD-Violence and MSAD datasets. By leveraging category-specific expertise and temporal guidance, GS-MoE sets a new benchmark for VAD under weak supervision.
DAMS:Dual-Branch Adaptive Multiscale Spatiotemporal Framework for Video Anomaly Detection
Jul 28, 2025



The goal of video anomaly detection is tantamount to performing spatio-temporal localization of abnormal events in the video. The multiscale temporal dependencies, visual-semantic heterogeneity, and the scarcity of labeled data exhibited by video anomalies collectively present a challenging research problem in computer vision. This study offers a dual-path architecture called the Dual-Branch Adaptive Multiscale Spatiotemporal Framework (DAMS), which is based on multilevel feature decoupling and fusion, enabling efficient anomaly detection modeling by integrating hierarchical feature learning and complementary information. The main processing path of this framework integrates the Adaptive Multiscale Time Pyramid Network (AMTPN) with the Convolutional Block Attention Mechanism (CBAM). AMTPN enables multigrained representation and dynamically weighted reconstruction of temporal features through a three-level cascade structure (time pyramid pooling, adaptive feature fusion, and temporal context enhancement). CBAM maximizes the entropy distribution of feature channels and spatial dimensions through dual attention mapping. Simultaneously, the parallel path driven by CLIP introduces a contrastive language-visual pre-training paradigm. Cross-modal semantic alignment and a multiscale instance selection mechanism provide high-order semantic guidance for spatio-temporal features. This creates a complete inference chain from the underlying spatio-temporal features to high-level semantic concepts. The orthogonal complementarity of the two paths and the information fusion mechanism jointly construct a comprehensive representation and identification capability for anomalous events. Extensive experimental results on the UCF-Crime and XD-Violence benchmarks establish the effectiveness of the DAMS framework.
HiProbe-VAD: Video Anomaly Detection via Hidden States Probing in Tuning-Free Multimodal LLMs
Jul 23, 2025



Video Anomaly Detection (VAD) aims to identify and locate deviations from normal patterns in video sequences. Traditional methods often struggle with substantial computational demands and a reliance on extensive labeled datasets, thereby restricting their practical applicability. To address these constraints, we propose HiProbe-VAD, a novel framework that leverages pre-trained Multimodal Large Language Models (MLLMs) for VAD without requiring fine-tuning. In this paper, we discover that the intermediate hidden states of MLLMs contain information-rich representations, exhibiting higher sensitivity and linear separability for anomalies compared to the output layer. To capitalize on this, we propose a Dynamic Layer Saliency Probing (DLSP) mechanism that intelligently identifies and extracts the most informative hidden states from the optimal intermediate layer during the MLLMs reasoning. Then a lightweight anomaly scorer and temporal localization module efficiently detects anomalies using these extracted hidden states and finally generate explanations. Experiments on the UCF-Crime and XD-Violence datasets demonstrate that HiProbe-VAD outperforms existing training-free and most traditional approaches. Furthermore, our framework exhibits remarkable cross-model generalization capabilities in different MLLMs without any tuning, unlocking the potential of pre-trained MLLMs for video anomaly detection and paving the way for more practical and scalable solutions.
Learning Event Completeness for Weakly Supervised Video Anomaly Detection
Jun 16, 2025Weakly supervised video anomaly detection (WS-VAD) is tasked with pinpointing temporal intervals containing anomalous events within untrimmed videos, utilizing only video-level annotations. However, a significant challenge arises due to the absence of dense frame-level annotations, often leading to incomplete localization in existing WS-VAD methods. To address this issue, we present a novel LEC-VAD, Learning Event Completeness for Weakly Supervised Video Anomaly Detection, which features a dual structure designed to encode both category-aware and category-agnostic semantics between vision and language. Within LEC-VAD, we devise semantic regularities that leverage an anomaly-aware Gaussian mixture to learn precise event boundaries, thereby yielding more complete event instances. Besides, we develop a novel memory bank-based prototype learning mechanism to enrich concise text descriptions associated with anomaly-event categories. This innovation bolsters the text's expressiveness, which is crucial for advancing WS-VAD. Our LEC-VAD demonstrates remarkable advancements over the current state-of-the-art methods on two benchmark datasets XD-Violence and UCF-Crime.
Flashback: Memory-Driven Zero-shot, Real-time Video Anomaly Detection
May 21, 2025Video Anomaly Detection (VAD) automatically identifies anomalous events from video, mitigating the need for human operators in large-scale surveillance deployments. However, three fundamental obstacles hinder real-world adoption: domain dependency and real-time constraints -- requiring near-instantaneous processing of incoming video. To this end, we propose Flashback, a zero-shot and real-time video anomaly detection paradigm. Inspired by the human cognitive mechanism of instantly judging anomalies and reasoning in current scenes based on past experience, Flashback operates in two stages: Recall and Respond. In the offline recall stage, an off-the-shelf LLM builds a pseudo-scene memory of both normal and anomalous captions without any reliance on real anomaly data. In the online respond stage, incoming video segments are embedded and matched against this memory via similarity search. By eliminating all LLM calls at inference time, Flashback delivers real-time VAD even on a consumer-grade GPU. On two large datasets from real-world surveillance scenarios, UCF-Crime and XD-Violence, we achieve 87.3 AUC (+7.0 pp) and 75.1 AP (+13.1 pp), respectively, outperforming prior zero-shot VAD methods by large margins.
PiercingEye: Dual-Space Video Violence Detection with Hyperbolic Vision-Language Guidance
Apr 26, 2025Existing weakly supervised video violence detection (VVD) methods primarily rely on Euclidean representation learning, which often struggles to distinguish visually similar yet semantically distinct events due to limited hierarchical modeling and insufficient ambiguous training samples. To address this challenge, we propose PiercingEye, a novel dual-space learning framework that synergizes Euclidean and hyperbolic geometries to enhance discriminative feature representation. Specifically, PiercingEye introduces a layer-sensitive hyperbolic aggregation strategy with hyperbolic Dirichlet energy constraints to progressively model event hierarchies, and a cross-space attention mechanism to facilitate complementary feature interactions between Euclidean and hyperbolic spaces. Furthermore, to mitigate the scarcity of ambiguous samples, we leverage large language models to generate logic-guided ambiguous event descriptions, enabling explicit supervision through a hyperbolic vision-language contrastive loss that prioritizes high-confusion samples via dynamic similarity-aware weighting. Extensive experiments on XD-Violence and UCF-Crime benchmarks demonstrate that PiercingEye achieves state-of-the-art performance, with particularly strong results on a newly curated ambiguous event subset, validating its superior capability in fine-grained violence detection.