 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaseRT: Best-in-Class LLM Inference on Apple Silicon via Native Metal
Jul 01, 2026We present BaseRT, a native Metal inference runtime for large language models (LLMs) on Apple Silicon, and report the highest inference throughput on this hardware to date. Existing runtimes, including llama.cpp and MLX-based frameworks, incur overhead from abstractions not designed for Metal's execution model or Apple Silicon's unified memory topology. By building natively on Metal with chip-specific kernel fusion, unified memory-aware optimisation, and custom dispatch logic, BaseRT recovers performance that framework-based approaches leave on the table. BaseRT supports a wide range of model families across eight quantisation formats (Q2 to FP16) on all Apple M-series devices. In this paper, we evaluate the Qwen3, Llama 3.2, and Gemma 4 families at Q4 and Q8 quantisation on M3 and M4 Pro devices. BaseRT achieves up to 1.56x higher decode throughput than llama.cpp and up to 1.35x higher than MLX, with substantially larger margins on prefill for mixture-of-experts models, delivering consistent best-in-class throughput from sub-1B to 30B parameter models. These results establish Apple Silicon as a more capable inference platform than previously reported, with direct implications for the emerging edge inference paradigm: as privacy requirements, latency constraints, and cloud cost pressures drive inference toward on-device deployment, performance-optimised local runtimes are a critical enabling layer for this transition. BaseRT is publicly available at https://github.com/basecompute/baseRT
A Surrogate-Augmented Symbolic CFD-Driven Training Framework for Accelerating Multi-objective Physical Model Development
Dec 22, 2025Computational Fluid Dynamics (CFD)-driven training combines machine learning (ML) with CFD solvers to develop physically consistent closure models with improved predictive accuracy. In the original framework, each ML-generated candidate model is embedded in a CFD solver and evaluated against reference data, requiring hundreds to thousands of high-fidelity simulations and resulting in prohibitive computational cost for complex flows. To overcome this limitation, we propose an extended framework that integrates surrogate modeling into symbolic CFD-driven training in real time to reduce training cost. The surrogate model learns to approximate the errors of ML-generated models based on previous CFD evaluations and is continuously refined during training. Newly generated models are first assessed using the surrogate, and only those predicted to yield small errors or high uncertainty are subsequently evaluated with full CFD simulations. Discrete expressions generated by symbolic regression are mapped into a continuous space using averaged input-symbol values as inputs to a probabilistic surrogate model. To support multi-objective model training, particularly when fixed weighting of competing quantities is challenging, the surrogate is extended to a multi-output formulation by generalizing the kernel to a matrix form, providing one mean and variance prediction per training objective. Selection metrics based on these probabilistic outputs are used to identify an optimal training setup. The proposed surrogate-augmented CFD-driven training framework is demonstrated across a range of statistically one- and two-dimensional flows, including both single- and multi-expression model optimization. In all cases, the framework substantially reduces training cost while maintaining predictive accuracy comparable to that of the original CFD-driven approach.
Unlocking Vision-Language Models for Video Anomaly Detection via Fine-Grained Prompting
Oct 02, 2025
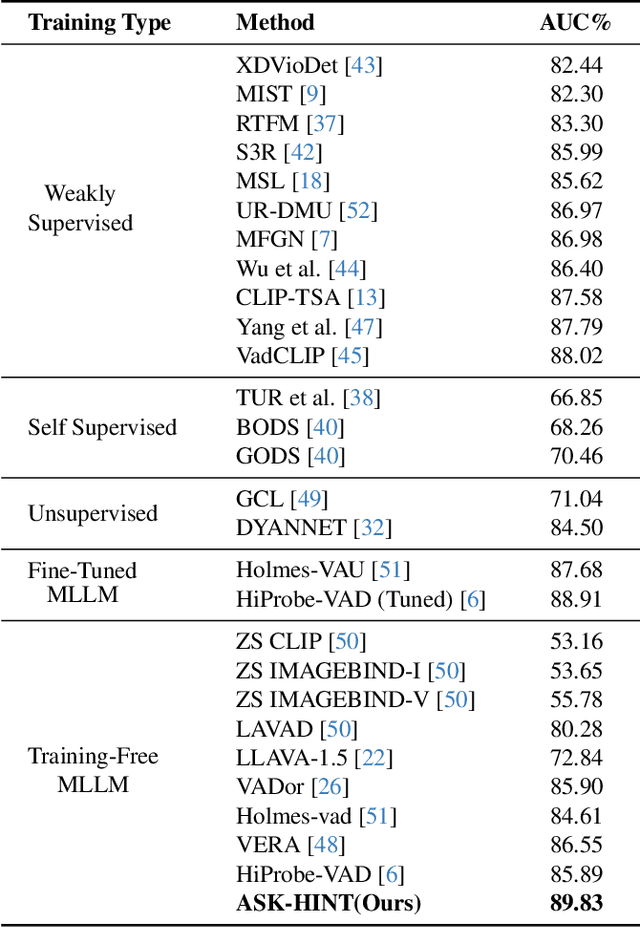
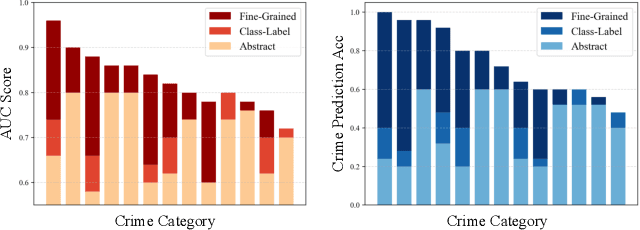
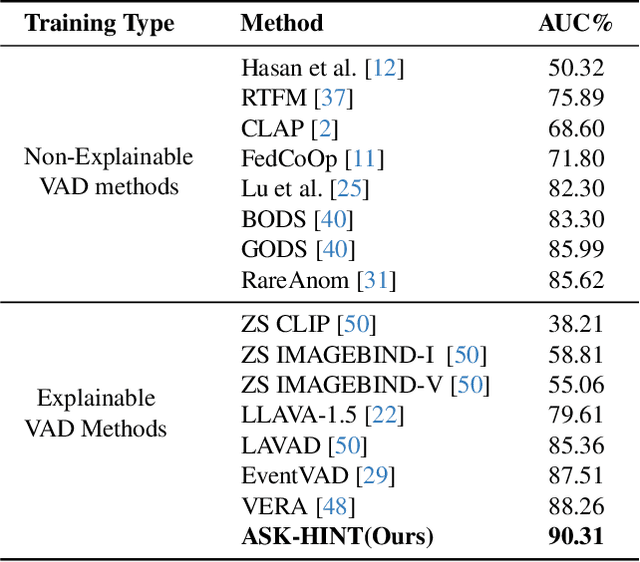
Prompting has emerged as a practical way to adapt frozen vision-language models (VLMs) for video anomaly detection (VAD). Yet, existing prompts are often overly abstract, overlooking the fine-grained human-object interactions or action semantics that define complex anomalies in surveillance videos. We propose ASK-Hint, a structured prompting framework that leverages action-centric knowledge to elicit more accurate and interpretable reasoning from frozen VLMs. Our approach organizes prompts into semantically coherent groups (e.g. violence, property crimes, public safety) and formulates fine-grained guiding questions that align model predictions with discriminative visual cues. Extensive experiments on UCF-Crime and XD-Violence show that ASK-Hint consistently improves AUC over prior baselines, achieving state-of-the-art performance compared to both fine-tuned and training-free methods. Beyond accuracy, our framework provides interpretable reasoning traces towards anomaly and demonstrates strong generalization across datasets and VLM backbones. These results highlight the critical role of prompt granularity and establish ASK-Hint as a new training-free and generalizable solution for explainable video anomaly detection.