 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAMS:Dual-Branch Adaptive Multiscale Spatiotemporal Framework for Video Anomaly Detection
Jul 28, 2025



The goal of video anomaly detection is tantamount to performing spatio-temporal localization of abnormal events in the video. The multiscale temporal dependencies, visual-semantic heterogeneity, and the scarcity of labeled data exhibited by video anomalies collectively present a challenging research problem in computer vision. This study offers a dual-path architecture called the Dual-Branch Adaptive Multiscale Spatiotemporal Framework (DAMS), which is based on multilevel feature decoupling and fusion, enabling efficient anomaly detection modeling by integrating hierarchical feature learning and complementary information. The main processing path of this framework integrates the Adaptive Multiscale Time Pyramid Network (AMTPN) with the Convolutional Block Attention Mechanism (CBAM). AMTPN enables multigrained representation and dynamically weighted reconstruction of temporal features through a three-level cascade structure (time pyramid pooling, adaptive feature fusion, and temporal context enhancement). CBAM maximizes the entropy distribution of feature channels and spatial dimensions through dual attention mapping. Simultaneously, the parallel path driven by CLIP introduces a contrastive language-visual pre-training paradigm. Cross-modal semantic alignment and a multiscale instance selection mechanism provide high-order semantic guidance for spatio-temporal features. This creates a complete inference chain from the underlying spatio-temporal features to high-level semantic concepts. The orthogonal complementarity of the two paths and the information fusion mechanism jointly construct a comprehensive representation and identification capability for anomalous events. Extensive experimental results on the UCF-Crime and XD-Violence benchmarks establish the effectiveness of the DAMS framework.
AggPose: Deep Aggregation Vision Transformer for Infant Pose Estimation
May 11, 2022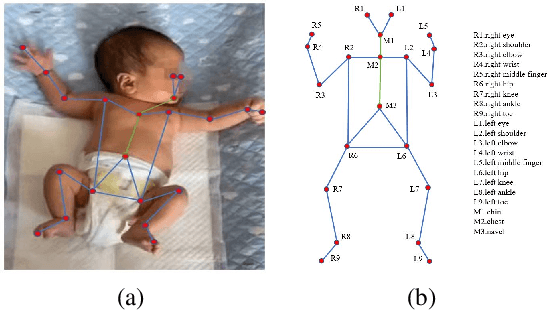

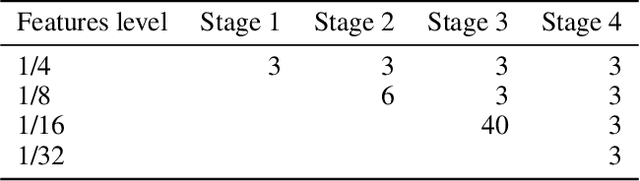
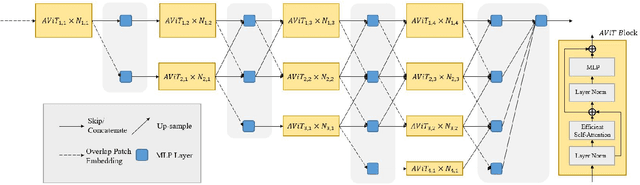
Movement and pose assessment of newborns lets experienced pediatricians predict neurodevelopmental disorders, allowing early intervention for related diseases. However, most of the newest AI approaches for human pose estimation methods focus on adults, lacking publicly benchmark for infant pose estimation. In this paper, we fill this gap by proposing infant pose dataset and Deep Aggregation Vision Transformer for human pose estimation, which introduces a fast trained full transformer framework without using convolution operations to extract features in the early stages. It generalizes Transformer + MLP to high-resolution deep layer aggregation within feature maps, thus enabling information fusion between different vision levels. We pre-train AggPose on COCO pose dataset and apply it on our newly released large-scale infant pose estimation dataset. The results show that AggPose could effectively learn the multi-scale features among different resolutions and significantly improve the performance of infant pose estimation. We show that AggPose outperforms hybrid model HRFormer and TokenPose in the infant pose estimation dataset. Moreover, our AggPose outperforms HRFormer by 0.7% AP on COCO val pose estimation on average. Our code is available at github.com/SZAR-LAB/AggPose.