 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewsqa
Papers and Code
Evaluating ChatGPT as a Question Answering System: A Comprehensive Analysis and Comparison with Existing Models
Dec 11, 2023In the current era, a multitude of language models has emerged to cater to user inquiries. Notably, the GPT-3.5 Turbo language model has gained substantial attention as the underlying technology for ChatGPT. Leveraging extensive parameters, this model adeptly responds to a wide range of questions. However, due to its reliance on internal knowledge, the accuracy of responses may not be absolute. This article scrutinizes ChatGPT as a Question Answering System (QAS), comparing its performance to other existing QASs. The primary focus is on evaluating ChatGPT's proficiency in extracting responses from provided paragraphs, a core QAS capability. Additionally, performance comparisons are made in scenarios without a surrounding passage. Multiple experiments, exploring response hallucination and considering question complexity, were conducted on ChatGPT. Evaluation employed well-known Question Answering (QA) datasets, including SQuAD, NewsQA, and PersianQuAD, across English and Persian languages. Metrics such as F-score, exact match, and accuracy were employed in the assessment. The study reveals that, while ChatGPT demonstrates competence as a generative model, it is less effective in question answering compared to task-specific models. Providing context improves its performance, and prompt engineering enhances precision, particularly for questions lacking explicit answers in provided paragraphs. ChatGPT excels at simpler factual questions compared to "how" and "why" question types. The evaluation highlights occurrences of hallucinations, where ChatGPT provides responses to questions without available answers in the provided context.
Machine Reading Comprehension using Case-based Reasoning
May 24, 2023



We present an accurate and interpretable method for answer extraction in machine reading comprehension that is reminiscent of case-based reasoning (CBR) from classical AI. Our method (CBR-MRC) builds on the hypothesis that contextualized answers to similar questions share semantic similarities with each other. Given a target question, CBR-MRC retrieves a set of similar questions from a memory of observed cases and predicts an answer by selecting the span in the target context that is most similar to the contextualized representations of answers in the retrieved cases. The semi-parametric nature of our approach allows CBR-MRC to attribute a prediction to the specific set of cases used during inference, making it a desirable choice for building reliable and debuggable QA systems. We show that CBR-MRC achieves high test accuracy comparable with large reader models, outperforming baselines by 11.5 and 8.4 EM on NaturalQuestions and NewsQA, respectively. Further, we also demonstrate the ability of CBR-MRC in identifying not just the correct answer tokens but also the span with the most relevant supporting evidence. Lastly, we observe that contexts for certain question types show higher lexical diversity than others and find CBR-MRC to be robust to these variations while performance using fully-parametric methods drops.
Unsupervised Question Answering via Answer Diversifying
Aug 23, 2022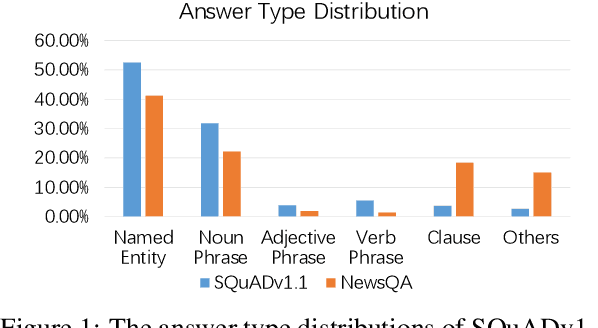
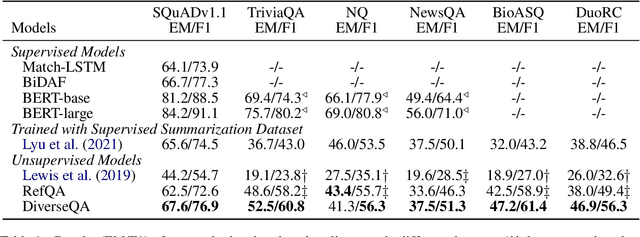
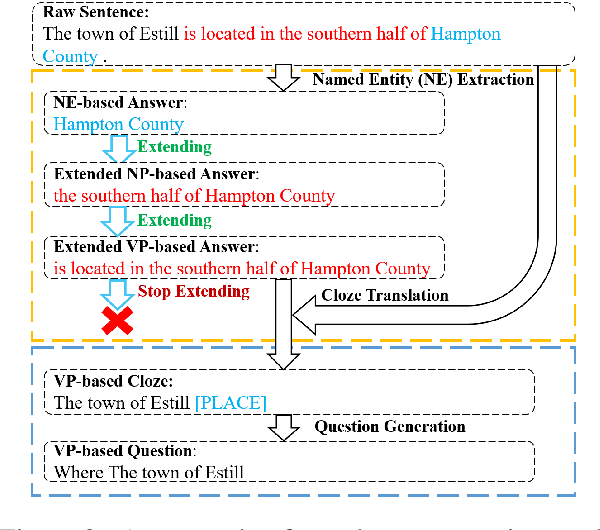
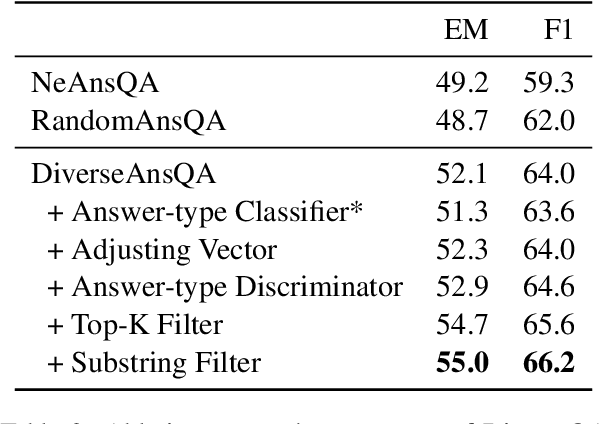
Unsupervised question answering is an attractive task due to its independence on labeled data. Previous works usually make use of heuristic rules as well as pre-trained models to construct data and train QA models. However, most of these works regard named entity (NE) as the only answer type, which ignores the high diversity of answers in the real world. To tackle this problem, we propose a novel unsupervised method by diversifying answers, named DiverseQA. Specifically, the proposed method is composed of three modules: data construction, data augmentation and denoising filter. Firstly, the data construction module extends the extracted named entity into a longer sentence constituent as the new answer span to construct a QA dataset with diverse answers. Secondly, the data augmentation module adopts an answer-type dependent data augmentation process via adversarial training in the embedding level. Thirdly, the denoising filter module is designed to alleviate the noise in the constructed data. Extensive experiments show that the proposed method outperforms previous unsupervised models on five benchmark datasets, including SQuADv1.1, NewsQA, TriviaQA, BioASQ, and DuoRC. Besides, the proposed method shows strong performance in the few-shot learning setting.
An Automated Question-Answering Framework Based on Evolution Algorithm
Jan 26, 2022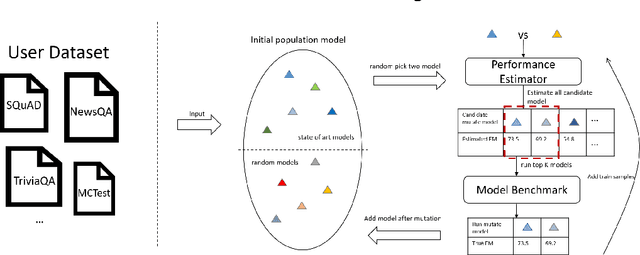

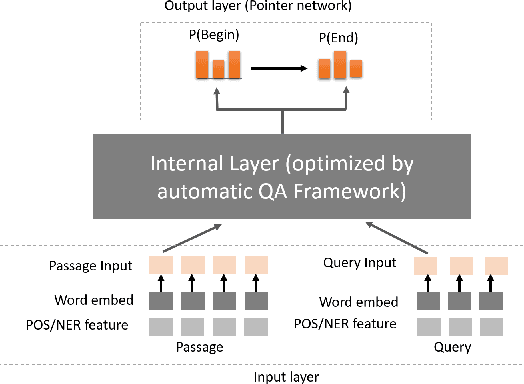
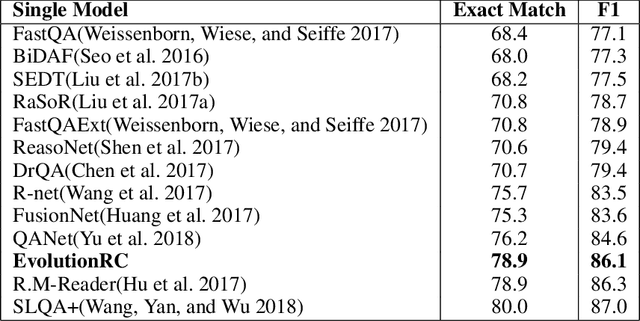
Building a deep learning model for a Question-Answering (QA) task requires a lot of human effort, it may need several months to carefully tune various model architectures and find a best one. It's even harder to find different excellent models for multiple datasets. Recent works show that the best model structure is related to the dataset used, and one single model cannot adapt to all tasks. In this paper, we propose an automated Question-Answering framework, which could automatically adjust network architecture for multiple datasets. Our framework is based on an innovative evolution algorithm, which is stable and suitable for multiple dataset scenario. The evolution algorithm for search combine prior knowledge into initial population and use a performance estimator to avoid inefficient mutation by predicting the performance of candidate model architecture. The prior knowledge used in initial population could improve the final result of the evolution algorithm. The performance estimator could quickly filter out models with bad performance in population as the number of trials increases, to speed up the convergence. Our framework achieves 78.9 EM and 86.1 F1 on SQuAD 1.1, 69.9 EM and 72.5 F1 on SQuAD 2.0. On NewsQA dataset, the found model achieves 47.0 EM and 62.9 F1.
Natural Answer Generation: From Factoid Answer to Full-length Answer using Grammar Correction
Dec 07, 2021
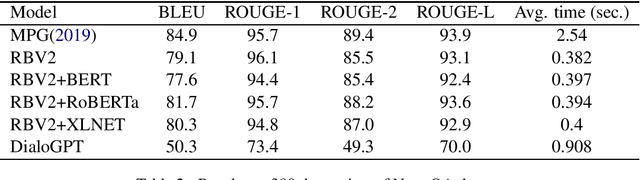
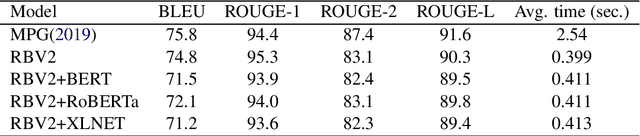
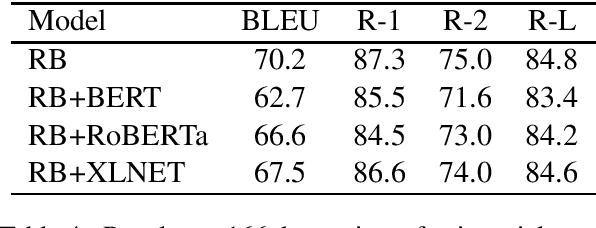
Question Answering systems these days typically use template-based language generation. Though adequate for a domain-specific task, these systems are too restrictive and predefined for domain-independent systems. This paper proposes a system that outputs a full-length answer given a question and the extracted factoid answer (short spans such as named entities) as the input. Our system uses constituency and dependency parse trees of questions. A transformer-based Grammar Error Correction model GECToR (2020), is used as a post-processing step for better fluency. We compare our system with (i) Modified Pointer Generator (SOTA) and (ii) Fine-tuned DialoGPT for factoid questions. We also test our approach on existential (yes-no) questions with better results. Our model generates accurate and fluent answers than the state-of-the-art (SOTA) approaches. The evaluation is done on NewsQA and SqUAD datasets with an increment of 0.4 and 0.9 percentage points in ROUGE-1 score respectively. Also the inference time is reduced by 85\% as compared to the SOTA. The improved datasets used for our evaluation will be released as part of the research contribution.
Improving Unsupervised Question Answering via Summarization-Informed Question Generation
Sep 16, 2021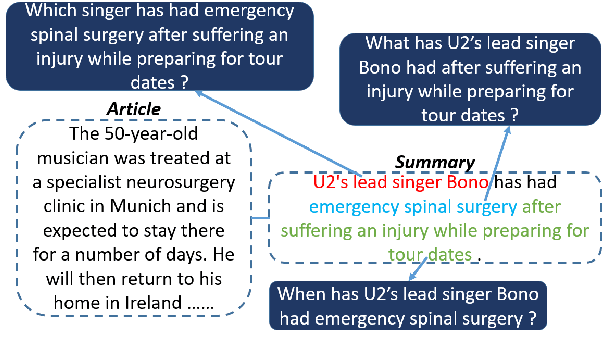
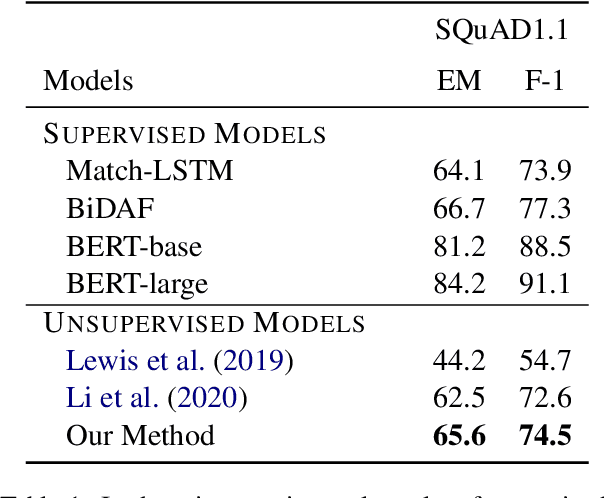
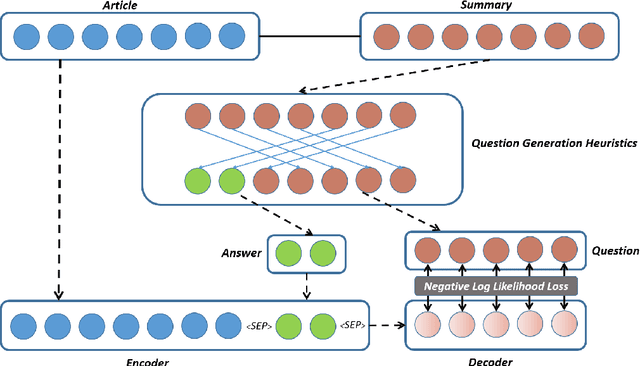
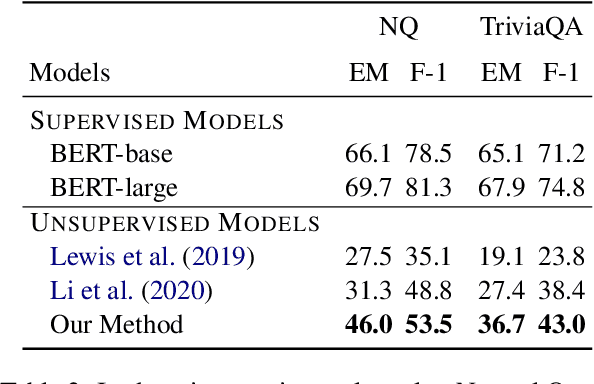
Question Generation (QG) is the task of generating a plausible question for a given <passage, answer> pair. Template-based QG uses linguistically-informed heuristics to transform declarative sentences into interrogatives, whereas supervised QG uses existing Question Answering (QA) datasets to train a system to generate a question given a passage and an answer. A disadvantage of the heuristic approach is that the generated questions are heavily tied to their declarative counterparts. A disadvantage of the supervised approach is that they are heavily tied to the domain/language of the QA dataset used as training data. In order to overcome these shortcomings, we propose an unsupervised QG method which uses questions generated heuristically from summaries as a source of training data for a QG system. We make use of freely available news summary data, transforming declarative summary sentences into appropriate questions using heuristics informed by dependency parsing, named entity recognition and semantic role labeling. The resulting questions are then combined with the original news articles to train an end-to-end neural QG model. We extrinsically evaluate our approach using unsupervised QA: our QG model is used to generate synthetic QA pairs for training a QA model. Experimental results show that, trained with only 20k English Wikipedia-based synthetic QA pairs, the QA model substantially outperforms previous unsupervised models on three in-domain datasets (SQuAD1.1, Natural Questions, TriviaQA) and three out-of-domain datasets (NewsQA, BioASQ, DuoRC), demonstrating the transferability of the approach.
OneStop QAMaker: Extract Question-Answer Pairs from Text in a One-Stop Approach
Feb 24, 2021Large-scale question-answer (QA) pairs are critical for advancing research areas like machine reading comprehension and question answering. To construct QA pairs from documents requires determining how to ask a question and what is the corresponding answer. Existing methods for QA pair generation usually follow a pipeline approach. Namely, they first choose the most likely candidate answer span and then generate the answer-specific question. This pipeline approach, however, is undesired in mining the most appropriate QA pairs from documents since it ignores the connection between question generation and answer extraction, which may lead to incompatible QA pair generation, i.e., the selected answer span is inappropriate for question generation. However, for human annotators, we take the whole QA pair into account and consider the compatibility between question and answer. Inspired by such motivation, instead of the conventional pipeline approach, we propose a model named OneStop generate QA pairs from documents in a one-stop approach. Specifically, questions and their corresponding answer span is extracted simultaneously and the process of question generation and answer extraction mutually affect each other. Additionally, OneStop is much more efficient to be trained and deployed in industrial scenarios since it involves only one model to solve the complex QA generation task. We conduct comprehensive experiments on three large-scale machine reading comprehension datasets: SQuAD, NewsQA, and DuReader. The experimental results demonstrate that our OneStop model outperforms the baselines significantly regarding the quality of generated questions, quality of generated question-answer pairs, and model efficiency.
KgPLM: Knowledge-guided Language Model Pre-training via Generative and Discriminative Learning
Dec 07, 2020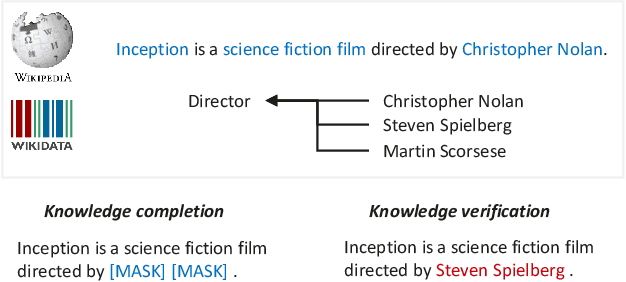
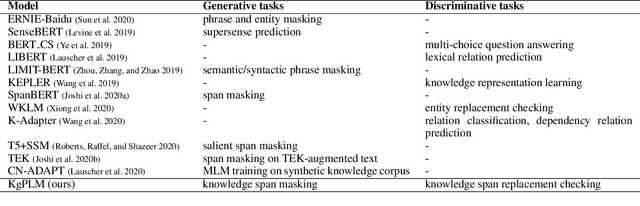

Recent studies on pre-trained language models have demonstrated their ability to capture factual knowledge and applications in knowledge-aware downstream tasks. In this work, we present a language model pre-training framework guided by factual knowledge completion and verification, and use the generative and discriminative approaches cooperatively to learn the model. Particularly, we investigate two learning schemes, named two-tower scheme and pipeline scheme, in training the generator and discriminator with shared parameter. Experimental results on LAMA, a set of zero-shot cloze-style question answering tasks, show that our model contains richer factual knowledge than the conventional pre-trained language models. Furthermore, when fine-tuned and evaluated on the MRQA shared tasks which consists of several machine reading comprehension datasets, our model achieves the state-of-the-art performance, and gains large improvements on NewsQA (+1.26 F1) and TriviaQA (+1.56 F1) over RoBERTa.
Question Generation for Supporting Informational Query Intents
Oct 19, 2020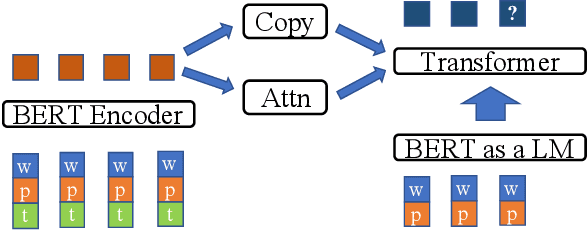

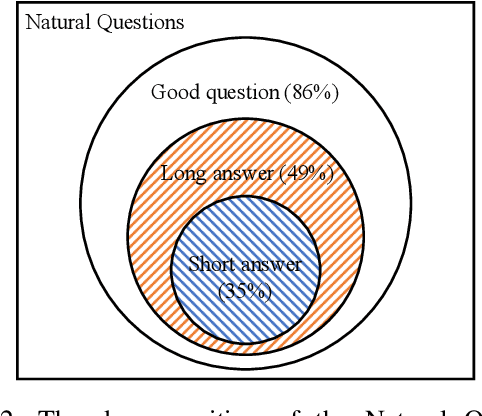

Users frequently ask simple factoid questions when encountering question answering (QA) systems, attenuating the impact of myriad recent works designed to support more complex questions. Prompting users with automatically generated suggested questions (SQs) can improve understanding of QA system capabilities and thus facilitate using this technology more effectively. While question generation (QG) is a well-established problem, existing methods are not targeted at producing SQ guidance for human users seeking more in-depth information about a specific concept. In particular, existing QG works are insufficient for this task as the generated questions frequently (1) require access to supporting documents as comprehension context (e.g., How many points did LeBron score?) and (2) focus on short answer spans, often producing peripheral factoid questions unlikely to attract interest. In this work, we aim to generate self-explanatory questions that focus on the main document topics and are answerable with variable length passages as appropriate. We satisfy these requirements by using a BERT-based Pointer-Generator Network (BertPGN) trained on the Natural Questions (NQ) dataset. First, we show that the BertPGN model produces state-of-the-art QG performance for long and short answers for in-domain NQ (BLEU-4 for 20.13 and 28.09, respectively). Secondly, we evaluate this QG model on the out-of-domain NewsQA dataset automatically and with human evaluation, demonstrating that our method produces better SQs for news articles, even those from a different domain than the training data.
Harvesting and Refining Question-Answer Pairs for Unsupervised QA
May 06, 2020
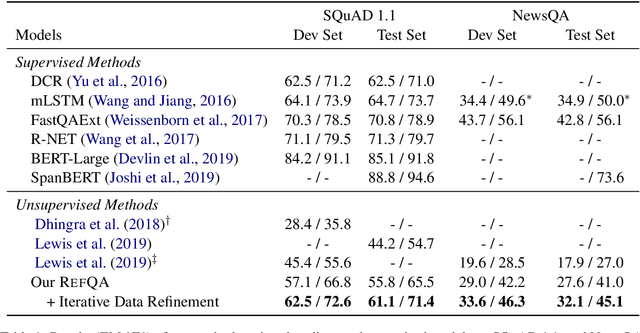

Question Answering (QA) has shown great success thanks to the availability of large-scale datasets and the effectiveness of neural models. Recent research works have attempted to extend these successes to the settings with few or no labeled data available. In this work, we introduce two approaches to improve unsupervised QA. First, we harvest lexically and syntactically divergent questions from Wikipedia to automatically construct a corpus of question-answer pairs (named as RefQA). Second, we take advantage of the QA model to extract more appropriate answers, which iteratively refines data over RefQA. We conduct experiments on SQuAD 1.1, and NewsQA by fine-tuning BERT without access to manually annotated data. Our approach outperforms previous unsupervised approaches by a large margin and is competitive with early supervised models. We also show the effectiveness of our approach in the few-shot learning setting.