 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Build Spatial World Models? Evidence from Grid-World Maze Tasks
Apr 12, 2026Foundation models have shown remarkable performance across diverse tasks, yet their ability to construct internal spatial world models for reasoning and planning remains unclear. We systematically evaluate the spatial understanding of large language models through maze tasks, a controlled testing context requiring multi-step planning and spatial abstraction. Across comprehensive experiments with Gemini-2.5-Flash, GPT-5-mini, Claude-Haiku-4.5, and DeepSeek-Chat, we uncover significant discrepancies in spatial reasoning that challenge assumptions about LLM planning capabilities. Using chain-of-thought prompting, Gemini achieves 80-86% accuracy on smaller mazes (5x5 to 7x7 grids) with tokenized adjacency representations, but performance collapses to 16-34% with visual grid formats, which is a 2-5x difference, suggesting representation-dependent rather than format-invariant spatial reasoning. We further probe spatial understanding through sequential proximity questions and compositional distance comparisons. Despite achieving 96-99% semantic coverage in reasoning traces, models fail to leverage this understanding for consistent spatial computations, indicating that they treat each question independently rather than building cumulative spatial knowledge. Our findings based on the maze-solving tasks suggest that LLMs do not develop robust spatial world models, but rather exhibit representation-specific and prompting-dependent reasoning that succeeds only under narrow conditions. These results have critical implications for deploying foundation models in applications requiring spatial abstraction.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Impact of Noise on LLM-Models Performance in Abstraction and Reasoning Corpus (ARC) Tasks with Model Temperature Considerations
Apr 22, 2025Recent advancements in Large Language Models (LLMs) have generated growing interest in their structured reasoning capabilities, particularly in tasks involving abstraction and pattern recognition. The Abstraction and Reasoning Corpus (ARC) benchmark plays a crucial role in evaluating these capabilities by testing how well AI models generalize to novel problems. While GPT-4o demonstrates strong performance by solving all ARC tasks under zero-noise conditions, other models like DeepSeek R1 and LLaMA 3.2 fail to solve any, suggesting limitations in their ability to reason beyond simple pattern matching. To explore this gap, we systematically evaluate these models across different noise levels and temperature settings. Our results reveal that the introduction of noise consistently impairs model performance, regardless of architecture. This decline highlights a shared vulnerability: current LLMs, despite showing signs of abstract reasoning, remain highly sensitive to input perturbations. Such fragility raises concerns about their real-world applicability, where noise and uncertainty are common. By comparing how different model architectures respond to these challenges, we offer insights into the structural weaknesses of modern LLMs in reasoning tasks. This work underscores the need for developing more robust and adaptable AI systems capable of handling the ambiguity and variability inherent in real-world scenarios. Our findings aim to guide future research toward enhancing model generalization, robustness, and alignment with human-like cognitive flexibility.
Exploring Next Token Prediction in Theory of Mind (ToM) Tasks: Comparative Experiments with GPT-2 and LLaMA-2 AI Models
Apr 22, 2025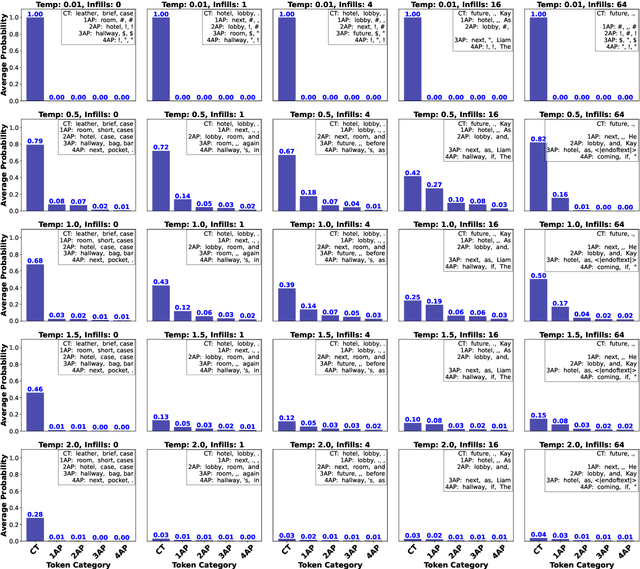
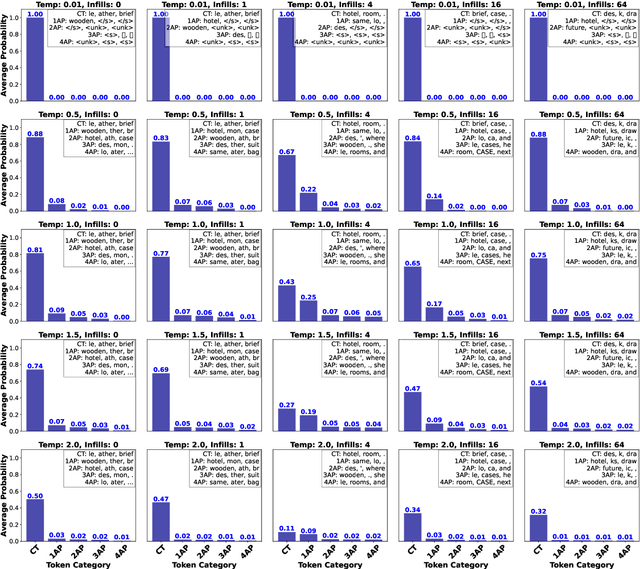
Language models have made significant progress in generating coherent text and predicting next tokens based on input prompts. This study compares the next-token prediction performance of two well-known models: OpenAI's GPT-2 and Meta's Llama-2-7b-chat-hf on Theory of Mind (ToM) tasks. To evaluate their capabilities, we built a dataset from 10 short stories sourced from the Explore ToM Dataset. We enhanced these stories by programmatically inserting additional sentences (infills) using GPT-4, creating variations that introduce different levels of contextual complexity. This setup enables analysis of how increasing context affects model performance. We tested both models under four temperature settings (0.01, 0.5, 1.0, 2.0) and evaluated their ability to predict the next token across three reasoning levels. Zero-order reasoning involves tracking the state, either current (ground truth) or past (memory). First-order reasoning concerns understanding another's mental state (e.g., "Does Anne know the apple is salted?"). Second-order reasoning adds recursion (e.g., "Does Anne think that Charles knows the apple is salted?"). Our results show that adding more infill sentences slightly reduces prediction accuracy, as added context increases complexity and ambiguity. Llama-2 consistently outperforms GPT-2 in prediction accuracy, especially at lower temperatures, demonstrating greater confidence in selecting the most probable token. As reasoning complexity rises, model responses diverge more. Notably, GPT-2 and Llama-2 display greater variability in predictions during first- and second-order reasoning tasks. These findings illustrate how model architecture, temperature, and contextual complexity influence next-token prediction, contributing to a better understanding of the strengths and limitations of current language models.
Constrained Decoding with Speculative Lookaheads
Dec 09, 2024Constrained decoding with lookahead heuristics (CDLH) is a highly effective method for aligning LLM generations to human preferences. However, the extensive lookahead roll-out operations for each generated token makes CDLH prohibitively expensive, resulting in low adoption in practice. In contrast, common decoding strategies such as greedy decoding are extremely efficient, but achieve very low constraint satisfaction. We propose constrained decoding with speculative lookaheads (CDSL), a technique that significantly improves upon the inference efficiency of CDLH without experiencing the drastic performance reduction seen with greedy decoding. CDSL is motivated by the recently proposed idea of speculative decoding that uses a much smaller draft LLM for generation and a larger target LLM for verification. In CDSL, the draft model is used to generate lookaheads which is verified by a combination of target LLM and task-specific reward functions. This process accelerates decoding by reducing the computational burden while maintaining strong performance. We evaluate CDSL in two constraint decoding tasks with three LLM families and achieve 2.2x to 12.15x speedup over CDLH without significant performance reduction.
Bring Your Own KG: Self-Supervised Program Synthesis for Zero-Shot KGQA
Nov 14, 2023



We present BYOKG, a universal question-answering (QA) system that can operate on any knowledge graph (KG), requires no human-annotated training data, and can be ready to use within a day -- attributes that are out-of-scope for current KGQA systems. BYOKG draws inspiration from the remarkable ability of humans to comprehend information present in an unseen KG through exploration -- starting at random nodes, inspecting the labels of adjacent nodes and edges, and combining them with their prior world knowledge. In BYOKG, exploration leverages an LLM-backed symbolic agent that generates a diverse set of query-program exemplars, which are then used to ground a retrieval-augmented reasoning procedure to predict programs for arbitrary questions. BYOKG is effective over both small- and large-scale graphs, showing dramatic gains in QA accuracy over a zero-shot baseline of 27.89 and 58.02 F1 on GrailQA and MetaQA, respectively. On GrailQA, we further show that our unsupervised BYOKG outperforms a supervised in-context learning method, demonstrating the effectiveness of exploration. Lastly, we find that performance of BYOKG reliably improves with continued exploration as well as improvements in the base LLM, notably outperforming a state-of-the-art fine-tuned model by 7.08 F1 on a sub-sampled zero-shot split of GrailQA.
Machine Reading Comprehension using Case-based Reasoning
May 24, 2023



We present an accurate and interpretable method for answer extraction in machine reading comprehension that is reminiscent of case-based reasoning (CBR) from classical AI. Our method (CBR-MRC) builds on the hypothesis that contextualized answers to similar questions share semantic similarities with each other. Given a target question, CBR-MRC retrieves a set of similar questions from a memory of observed cases and predicts an answer by selecting the span in the target context that is most similar to the contextualized representations of answers in the retrieved cases. The semi-parametric nature of our approach allows CBR-MRC to attribute a prediction to the specific set of cases used during inference, making it a desirable choice for building reliable and debuggable QA systems. We show that CBR-MRC achieves high test accuracy comparable with large reader models, outperforming baselines by 11.5 and 8.4 EM on NaturalQuestions and NewsQA, respectively. Further, we also demonstrate the ability of CBR-MRC in identifying not just the correct answer tokens but also the span with the most relevant supporting evidence. Lastly, we observe that contexts for certain question types show higher lexical diversity than others and find CBR-MRC to be robust to these variations while performance using fully-parametric methods drops.
When Not to Trust Language Models: Investigating Effectiveness and Limitations of Parametric and Non-Parametric Memories
Dec 20, 2022Despite their impressive performance on diverse tasks, large language models (LMs) still struggle with tasks requiring rich world knowledge, implying the limitations of relying solely on their parameters to encode a wealth of world knowledge. This paper aims to understand LMs' strengths and limitations in memorizing factual knowledge, by conducting large-scale knowledge probing experiments of 10 models and 4 augmentation methods on PopQA, our new open-domain QA dataset with 14k questions. We find that LMs struggle with less popular factual knowledge, and that scaling fails to appreciably improve memorization of factual knowledge in the tail. We then show that retrieval-augmented LMs largely outperform orders of magnitude larger LMs, while unassisted LMs remain competitive in questions about high-popularity entities. Based on those findings, we devise a simple, yet effective, method for powerful and efficient retrieval-augmented LMs, which retrieves non-parametric memories only when necessary. Experimental results show that this significantly improves models' performance while reducing the inference costs.
CBR-iKB: A Case-Based Reasoning Approach for Question Answering over Incomplete Knowledge Bases
Apr 18, 2022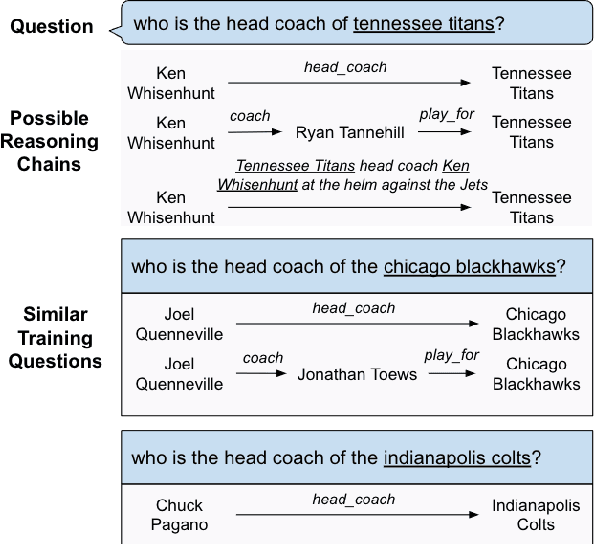
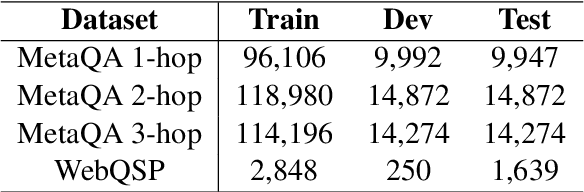
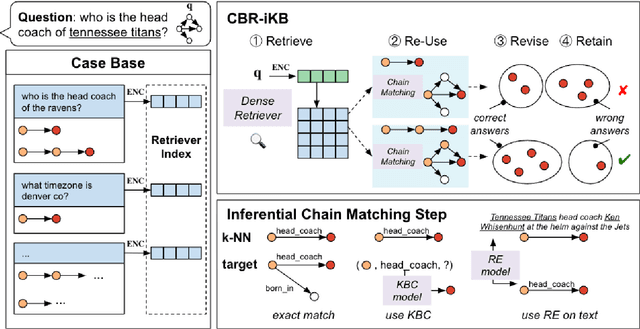
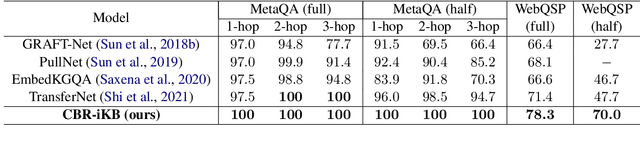
Knowledge bases (KBs) are often incomplete and constantly changing in practice. Yet, in many question answering applications coupled with knowledge bases, the sparse nature of KBs is often overlooked. To this end, we propose a case-based reasoning approach, CBR-iKB, for knowledge base question answering (KBQA) with incomplete-KB as our main focus. Our method ensembles decisions from multiple reasoning chains with a novel nonparametric reasoning algorithm. By design, CBR-iKB can seamlessly adapt to changes in KBs without any task-specific training or fine-tuning. Our method achieves 100% accuracy on MetaQA and establishes new state-of-the-art on multiple benchmarks. For instance, CBR-iKB achieves an accuracy of 70% on WebQSP under the incomplete-KB setting, outperforming the existing state-of-the-art method by 22.3%.
Calibration of Machine Reading Systems at Scale
Mar 20, 2022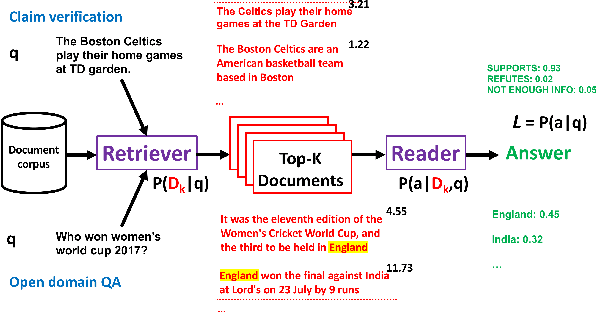
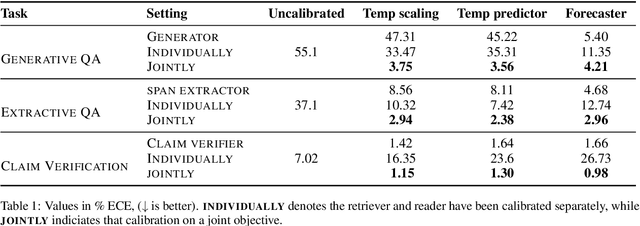

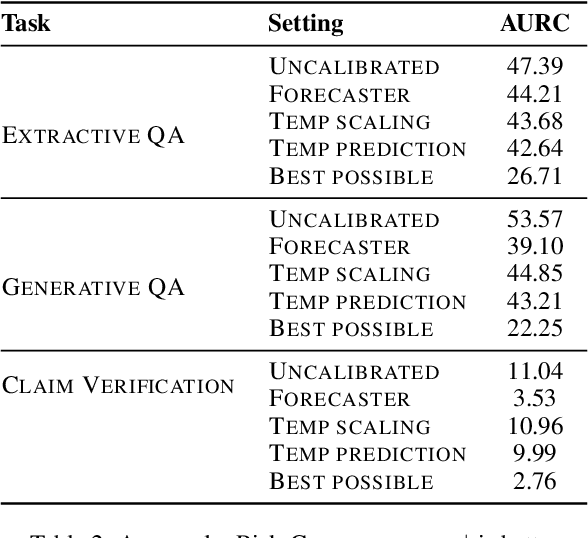
In typical machine learning systems, an estimate of the probability of the prediction is used to assess the system's confidence in the prediction. This confidence measure is usually uncalibrated; i.e.\ the system's confidence in the prediction does not match the true probability of the predicted output. In this paper, we present an investigation into calibrating open setting machine reading systems such as open-domain question answering and claim verification systems. We show that calibrating such complex systems which contain discrete retrieval and deep reading components is challenging and current calibration techniques fail to scale to these settings. We propose simple extensions to existing calibration approaches that allows us to adapt them to these settings. Our experimental results reveal that the approach works well, and can be useful to selectively predict answers when question answering systems are posed with unanswerable or out-of-the-training distribution questions.