 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Reading Comprehension using Case-based Reasoning
May 24, 2023



We present an accurate and interpretable method for answer extraction in machine reading comprehension that is reminiscent of case-based reasoning (CBR) from classical AI. Our method (CBR-MRC) builds on the hypothesis that contextualized answers to similar questions share semantic similarities with each other. Given a target question, CBR-MRC retrieves a set of similar questions from a memory of observed cases and predicts an answer by selecting the span in the target context that is most similar to the contextualized representations of answers in the retrieved cases. The semi-parametric nature of our approach allows CBR-MRC to attribute a prediction to the specific set of cases used during inference, making it a desirable choice for building reliable and debuggable QA systems. We show that CBR-MRC achieves high test accuracy comparable with large reader models, outperforming baselines by 11.5 and 8.4 EM on NaturalQuestions and NewsQA, respectively. Further, we also demonstrate the ability of CBR-MRC in identifying not just the correct answer tokens but also the span with the most relevant supporting evidence. Lastly, we observe that contexts for certain question types show higher lexical diversity than others and find CBR-MRC to be robust to these variations while performance using fully-parametric methods drops.
SeRP: Self-Supervised Representation Learning Using Perturbed Point Clouds
Sep 13, 2022
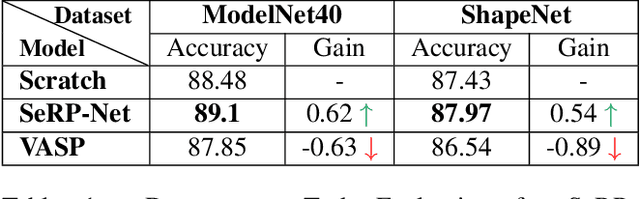
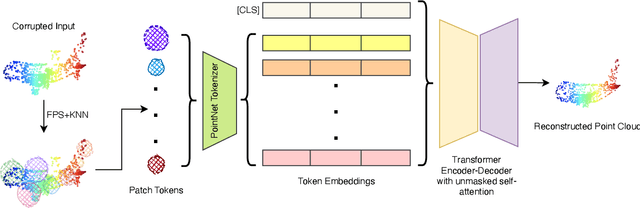
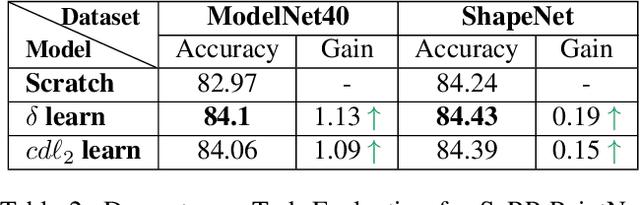
We present SeRP, a framework for Self-Supervised Learning of 3D point clouds. SeRP consists of encoder-decoder architecture that takes perturbed or corrupted point clouds as inputs and aims to reconstruct the original point cloud without corruption. The encoder learns the high-level latent representations of the points clouds in a low-dimensional subspace and recovers the original structure. In this work, we have used Transformers and PointNet-based Autoencoders. The proposed framework also addresses some of the limitations of Transformers-based Masked Autoencoders which are prone to leakage of location information and uneven information density. We trained our models on the complete ShapeNet dataset and evaluated them on ModelNet40 as a downstream classification task. We have shown that the pretrained models achieved 0.5-1% higher classification accuracies than the networks trained from scratch. Furthermore, we also proposed VASP: Vector-Quantized Autoencoder for Self-supervised Representation Learning for Point Clouds that employs Vector-Quantization for discrete representation learning for Transformer-based autoencoders.
Cross-lingual Word Embeddings in Hyperbolic Space
May 04, 2022
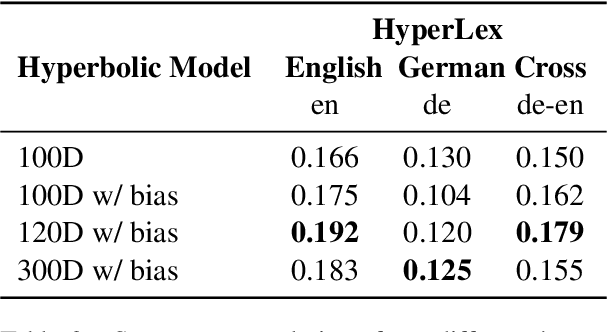
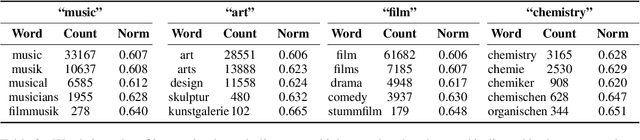
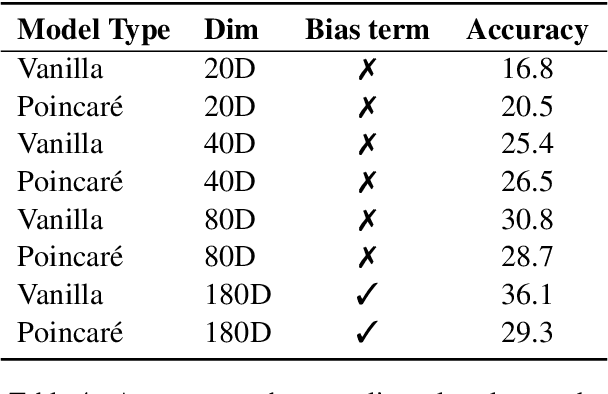
Cross-lingual word embeddings can be applied to several natural language processing applications across multiple languages. Unlike prior works that use word embeddings based on the Euclidean space, this short paper presents a simple and effective cross-lingual Word2Vec model that adapts to the Poincar\'e ball model of hyperbolic space to learn unsupervised cross-lingual word representations from a German-English parallel corpus. It has been shown that hyperbolic embeddings can capture and preserve hierarchical relationships. We evaluate the model on both hypernymy and analogy tasks. The proposed model achieves comparable performance with the vanilla Word2Vec model on the cross-lingual analogy task, the hypernymy task shows that the cross-lingual Poincar\'e Word2Vec model can capture latent hierarchical structure from free text across languages, which are absent from the Euclidean-based Word2Vec representations. Our results show that by preserving the latent hierarchical information, hyperbolic spaces can offer better representations for cross-lingual embeddings.
CBR-iKB: A Case-Based Reasoning Approach for Question Answering over Incomplete Knowledge Bases
Apr 18, 2022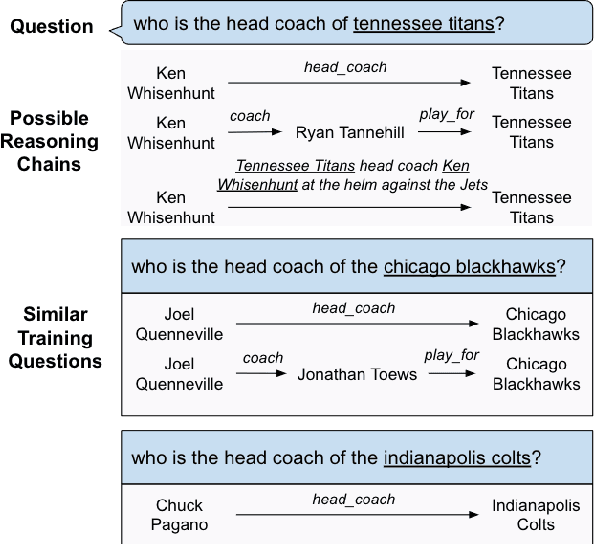
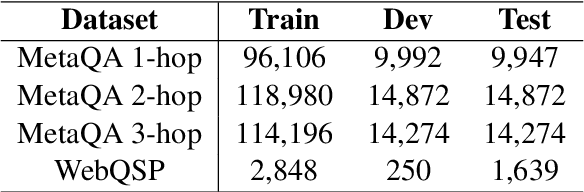
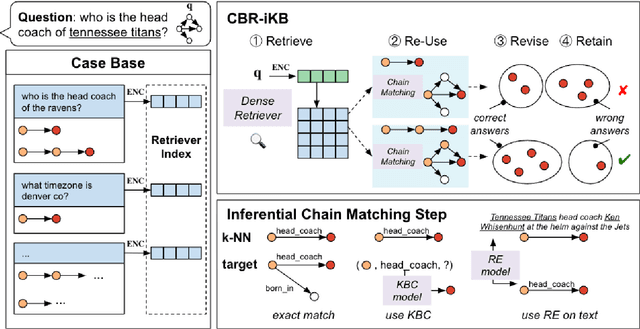
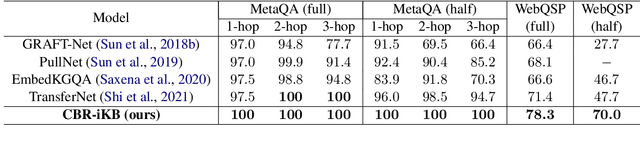
Knowledge bases (KBs) are often incomplete and constantly changing in practice. Yet, in many question answering applications coupled with knowledge bases, the sparse nature of KBs is often overlooked. To this end, we propose a case-based reasoning approach, CBR-iKB, for knowledge base question answering (KBQA) with incomplete-KB as our main focus. Our method ensembles decisions from multiple reasoning chains with a novel nonparametric reasoning algorithm. By design, CBR-iKB can seamlessly adapt to changes in KBs without any task-specific training or fine-tuning. Our method achieves 100% accuracy on MetaQA and establishes new state-of-the-art on multiple benchmarks. For instance, CBR-iKB achieves an accuracy of 70% on WebQSP under the incomplete-KB setting, outperforming the existing state-of-the-art method by 22.3%.
Countering Online Hate Speech: An NLP Perspective
Sep 07, 2021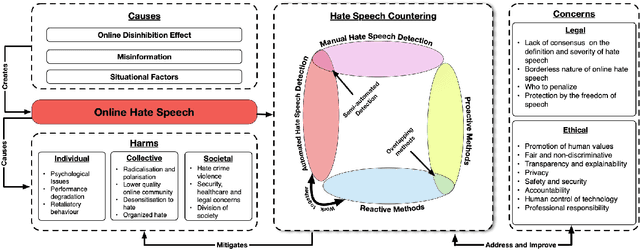
Online hate speech has caught everyone's attention from the news related to the COVID-19 pandemic, US elections, and worldwide protests. Online toxicity - an umbrella term for online hateful behavior, manifests itself in forms such as online hate speech. Hate speech is a deliberate attack directed towards an individual or a group motivated by the targeted entity's identity or opinions. The rising mass communication through social media further exacerbates the harmful consequences of online hate speech. While there has been significant research on hate-speech identification using Natural Language Processing (NLP), the work on utilizing NLP for prevention and intervention of online hate speech lacks relatively. This paper presents a holistic conceptual framework on hate-speech NLP countering methods along with a thorough survey on the current progress of NLP for countering online hate speech. It classifies the countering techniques based on their time of action, and identifies potential future research areas on this topic.
Unstructured Knowledge Access in Task-oriented Dialog Modeling using Language Inference, Knowledge Retrieval and Knowledge-Integrative Response Generation
Jan 15, 2021
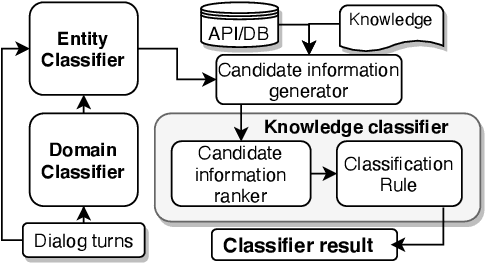

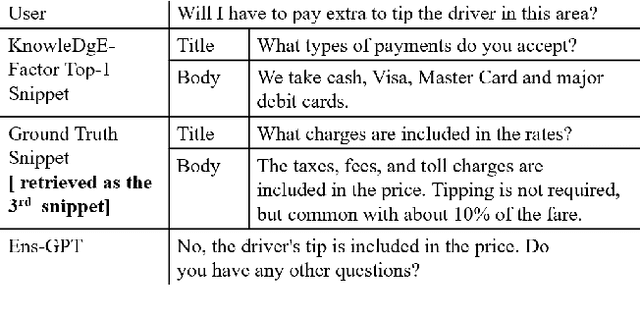
Dialog systems enriched with external knowledge can handle user queries that are outside the scope of the supporting databases/APIs. In this paper, we follow the baseline provided in DSTC9 Track 1 and propose three subsystems, KDEAK, KnowleDgEFactor, and Ens-GPT, which form the pipeline for a task-oriented dialog system capable of accessing unstructured knowledge. Specifically, KDEAK performs knowledge-seeking turn detection by formulating the problem as natural language inference using knowledge from dialogs, databases and FAQs. KnowleDgEFactor accomplishes the knowledge selection task by formulating a factorized knowledge/document retrieval problem with three modules performing domain, entity and knowledge level analyses. Ens-GPT generates a response by first processing multiple knowledge snippets, followed by an ensemble algorithm that decides if the response should be solely derived from a GPT2-XL model, or regenerated in combination with the top-ranking knowledge snippet. Experimental results demonstrate that the proposed pipeline system outperforms the baseline and generates high-quality responses, achieving at least 58.77% improvement on BLEU-4 score.