 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilateral Grid
Papers and Code
The Sample Complexity of Uniform Approximation for Multi-Dimensional CDFs and Fixed-Price Mechanisms
Feb 11, 2026We study the sample complexity of learning a uniform approximation of an $n$-dimensional cumulative distribution function (CDF) within an error $ε> 0$, when observations are restricted to a minimal one-bit feedback. This serves as a counterpart to the multivariate DKW inequality under ''full feedback'', extending it to the setting of ''bandit feedback''. Our main result shows a near-dimensional-invariance in the sample complexity: we get a uniform $ε$-approximation with a sample complexity $\frac{1}{ε^3}{\log\left(\frac 1 ε\right)^{\mathcal{O}(n)}}$ over a arbitrary fine grid, where the dimensionality $n$ only affects logarithmic terms. As direct corollaries, we provide tight sample complexity bounds and novel regret guarantees for learning fixed-price mechanisms in small markets, such as bilateral trade settings.
Virtual-Eyes: Quantitative Validation of a Lung CT Quality-Control Pipeline for Foundation-Model Cancer Risk Prediction
Dec 30, 2025Robust preprocessing is rarely quantified in deep-learning pipelines for low-dose CT (LDCT) lung cancer screening. We develop and validate Virtual-Eyes, a clinically motivated 16-bit CT quality-control pipeline, and measure its differential impact on generalist foundation models versus specialist models. Virtual-Eyes enforces strict 512x512 in-plane resolution, rejects short or non-diagnostic series, and extracts a contiguous lung block using Hounsfield-unit filtering and bilateral lung-coverage scoring while preserving the native 16-bit grid. Using 765 NLST patients (182 cancer, 583 non-cancer), we compute slice-level embeddings from RAD-DINO and Merlin with frozen encoders and train leakage-free patient-level MLP heads; we also evaluate Sybil and a 2D ResNet-18 baseline under Raw versus Virtual-Eyes inputs without backbone retraining. Virtual-Eyes improves RAD-DINO slice-level AUC from 0.576 to 0.610 and patient-level AUC from 0.646 to 0.683 (mean pooling) and from 0.619 to 0.735 (max pooling), with improved calibration (Brier score 0.188 to 0.112). In contrast, Sybil and ResNet-18 degrade under Virtual-Eyes (Sybil AUC 0.886 to 0.837; ResNet-18 AUC 0.571 to 0.596) with evidence of context dependence and shortcut learning, and Merlin shows limited transferability (AUC approximately 0.507 to 0.567) regardless of preprocessing. These results demonstrate that anatomically targeted QC can stabilize and improve generalist foundation-model workflows but may disrupt specialist models adapted to raw clinical context.
Learning Pixel-adaptive Multi-layer Perceptrons for Real-time Image Enhancement
Jul 16, 2025Deep learning-based bilateral grid processing has emerged as a promising solution for image enhancement, inherently encoding spatial and intensity information while enabling efficient full-resolution processing through slicing operations. However, existing approaches are limited to linear affine transformations, hindering their ability to model complex color relationships. Meanwhile, while multi-layer perceptrons (MLPs) excel at non-linear mappings, traditional MLP-based methods employ globally shared parameters, which is hard to deal with localized variations. To overcome these dual challenges, we propose a Bilateral Grid-based Pixel-Adaptive Multi-layer Perceptron (BPAM) framework. Our approach synergizes the spatial modeling of bilateral grids with the non-linear capabilities of MLPs. Specifically, we generate bilateral grids containing MLP parameters, where each pixel dynamically retrieves its unique transformation parameters and obtain a distinct MLP for color mapping based on spatial coordinates and intensity values. In addition, we propose a novel grid decomposition strategy that categorizes MLP parameters into distinct types stored in separate subgrids. Multi-channel guidance maps are used to extract category-specific parameters from corresponding subgrids, ensuring effective utilization of color information during slicing while guiding precise parameter generation. Extensive experiments on public datasets demonstrate that our method outperforms state-of-the-art methods in performance while maintaining real-time processing capabilities.
Unifying Appearance Codes and Bilateral Grids for Driving Scene Gaussian Splatting
Jun 06, 2025Neural rendering techniques, including NeRF and Gaussian Splatting (GS), rely on photometric consistency to produce high-quality reconstructions. However, in real-world scenarios, it is challenging to guarantee perfect photometric consistency in acquired images. Appearance codes have been widely used to address this issue, but their modeling capability is limited, as a single code is applied to the entire image. Recently, the bilateral grid was introduced to perform pixel-wise color mapping, but it is difficult to optimize and constrain effectively. In this paper, we propose a novel multi-scale bilateral grid that unifies appearance codes and bilateral grids. We demonstrate that this approach significantly improves geometric accuracy in dynamic, decoupled autonomous driving scene reconstruction, outperforming both appearance codes and bilateral grids. This is crucial for autonomous driving, where accurate geometry is important for obstacle avoidance and control. Our method shows strong results across four datasets: Waymo, NuScenes, Argoverse, and PandaSet. We further demonstrate that the improvement in geometry is driven by the multi-scale bilateral grid, which effectively reduces floaters caused by photometric inconsistency.
Bilateral Guided Radiance Field Processing
Jun 01, 2024



Neural Radiance Fields (NeRF) achieves unprecedented performance in synthesizing novel view synthesis, utilizing multi-view consistency. When capturing multiple inputs, image signal processing (ISP) in modern cameras will independently enhance them, including exposure adjustment, color correction, local tone mapping, etc. While these processings greatly improve image quality, they often break the multi-view consistency assumption, leading to "floaters" in the reconstructed radiance fields. To address this concern without compromising visual aesthetics, we aim to first disentangle the enhancement by ISP at the NeRF training stage and re-apply user-desired enhancements to the reconstructed radiance fields at the finishing stage. Furthermore, to make the re-applied enhancements consistent between novel views, we need to perform imaging signal processing in 3D space (i.e. "3D ISP"). For this goal, we adopt the bilateral grid, a locally-affine model, as a generalized representation of ISP processing. Specifically, we optimize per-view 3D bilateral grids with radiance fields to approximate the effects of camera pipelines for each input view. To achieve user-adjustable 3D finishing, we propose to learn a low-rank 4D bilateral grid from a given single view edit, lifting photo enhancements to the whole 3D scene. We demonstrate our approach can boost the visual quality of novel view synthesis by effectively removing floaters and performing enhancements from user retouching. The source code and our data are available at: https://bilarfpro.github.io.
DiffRetouch: Using Diffusion to Retouch on the Shoulder of Experts
Jul 04, 2024



Image retouching aims to enhance the visual quality of photos. Considering the different aesthetic preferences of users, the target of retouching is subjective. However, current retouching methods mostly adopt deterministic models, which not only neglects the style diversity in the expert-retouched results and tends to learn an average style during training, but also lacks sample diversity during inference. In this paper, we propose a diffusion-based method, named DiffRetouch. Thanks to the excellent distribution modeling ability of diffusion, our method can capture the complex fine-retouched distribution covering various visual-pleasing styles in the training data. Moreover, four image attributes are made adjustable to provide a user-friendly editing mechanism. By adjusting these attributes in specified ranges, users are allowed to customize preferred styles within the learned fine-retouched distribution. Additionally, the affine bilateral grid and contrastive learning scheme are introduced to handle the problem of texture distortion and control insensitivity respectively. Extensive experiments have demonstrated the superior performance of our method on visually appealing and sample diversity. The code will be made available to the community.
Slicer Networks
Jan 18, 2024In medical imaging, scans often reveal objects with varied contrasts but consistent internal intensities or textures. This characteristic enables the use of low-frequency approximations for tasks such as segmentation and deformation field estimation. Yet, integrating this concept into neural network architectures for medical image analysis remains underexplored. In this paper, we propose the Slicer Network, a novel architecture designed to leverage these traits. Comprising an encoder utilizing models like vision transformers for feature extraction and a slicer employing a learnable bilateral grid, the Slicer Network strategically refines and upsamples feature maps via a splatting-blurring-slicing process. This introduces an edge-preserving low-frequency approximation for the network outcome, effectively enlarging the effective receptive field. The enhancement not only reduces computational complexity but also boosts overall performance. Experiments across different medical imaging applications, including unsupervised and keypoints-based image registration and lesion segmentation, have verified the Slicer Network's improved accuracy and efficiency.
4K-Resolution Photo Exposure Correction at 125 FPS with ~8K Parameters
Nov 15, 2023



The illumination of improperly exposed photographs has been widely corrected using deep convolutional neural networks or Transformers. Despite with promising performance, these methods usually suffer from large parameter amounts and heavy computational FLOPs on high-resolution photographs. In this paper, we propose extremely light-weight (with only ~8K parameters) Multi-Scale Linear Transformation (MSLT) networks under the multi-layer perception architecture, which can process 4K-resolution sRGB images at 125 Frame-Per-Second (FPS) by a Titan RTX GPU. Specifically, the proposed MSLT networks first decompose an input image into high and low frequency layers by Laplacian pyramid techniques, and then sequentially correct different layers by pixel-adaptive linear transformation, which is implemented by efficient bilateral grid learning or 1x1 convolutions. Experiments on two benchmark datasets demonstrate the efficiency of our MSLTs against the state-of-the-arts on photo exposure correction. Extensive ablation studies validate the effectiveness of our contributions. The code is available at https://github.com/Zhou-Yijie/MSLTNet.
AdaCM: Adaptive ColorMLP for Real-Time Universal Photo-realistic Style Transfer
Dec 03, 2022Photo-realistic style transfer aims at migrating the artistic style from an exemplar style image to a content image, producing a result image without spatial distortions or unrealistic artifacts. Impressive results have been achieved by recent deep models. However, deep neural network based methods are too expensive to run in real-time. Meanwhile, bilateral grid based methods are much faster but still contain artifacts like overexposure. In this work, we propose the \textbf{Adaptive ColorMLP (AdaCM)}, an effective and efficient framework for universal photo-realistic style transfer. First, we find the complex non-linear color mapping between input and target domain can be efficiently modeled by a small multi-layer perceptron (ColorMLP) model. Then, in \textbf{AdaCM}, we adopt a CNN encoder to adaptively predict all parameters for the ColorMLP conditioned on each input content and style image pair. Experimental results demonstrate that AdaCM can generate vivid and high-quality stylization results. Meanwhile, our AdaCM is ultrafast and can process a 4K resolution image in 6ms on one V100 GPU.
Image Enhancement via Bilateral Learning
Dec 07, 2021
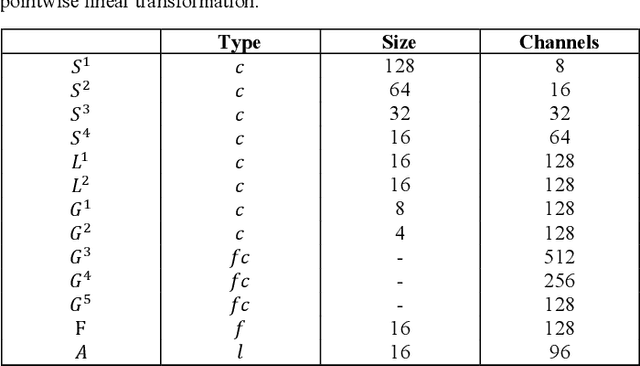
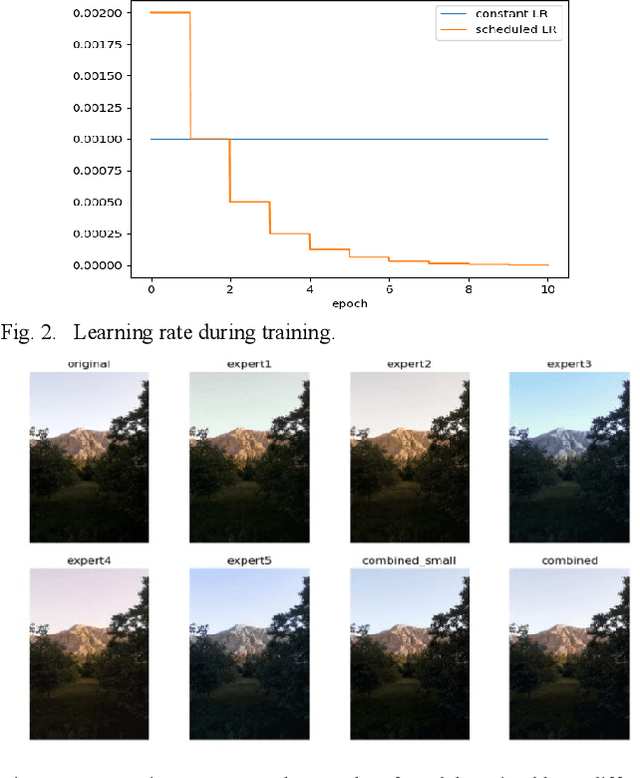

Nowadays, due to advanced digital imaging technologies and internet accessibility to the public, the number of generated digital images has increased dramatically. Thus, the need for automatic image enhancement techniques is quite apparent. In recent years, deep learning has been used effectively. Here, after introducing some recently developed works on image enhancement, an image enhancement system based on convolutional neural networks is presented. Our goal is to make an effective use of two available approaches, convolutional neural network and bilateral grid. In our approach, we increase the training data and the model dimensions and propose a variable rate during the training process. The enhancement results produced by our proposed method, while incorporating 5 different experts, show both quantitative and qualitative improvements as compared to other available methods.